算法原理
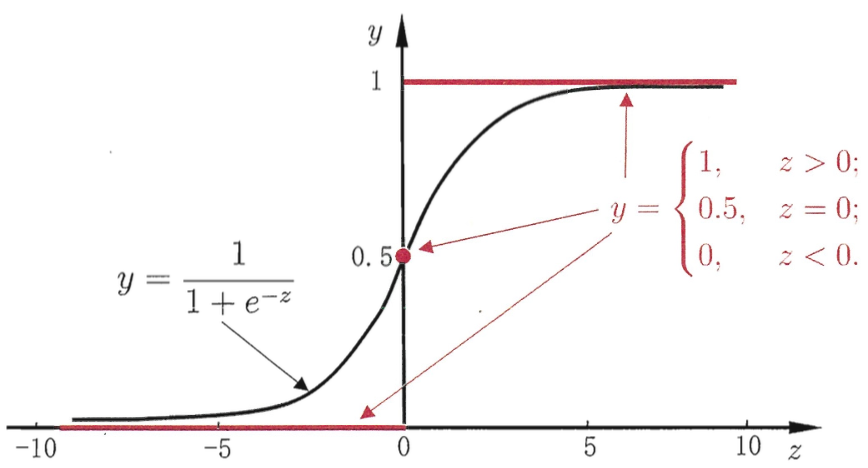
逻辑回归(logistic regression)是机器学习中的经典分类方法。该模型在线性回归的基础上套以Sigmoid函数,将线性回归的值域范围整流到0到1之间,由于结果仍然是连续的,所以是一种回归模型,但是该模型通常用来解决分类问题,因为0到1之间的值可以认为是概率,所以如果概率大于某个阈值,就代表是正类,小于某阈值则认为是负类。
下图是Sigmoid函数的图像:
 逻辑回归模型的函数式表达:
逻辑回归模型的函数式表达:
 由此可见,逻辑回归实际上是用线性回归模型去拟合真实样本的对数几率,所以是一种对数线性模型。
由此可见,逻辑回归实际上是用线性回归模型去拟合真实样本的对数几率,所以是一种对数线性模型。
对于逻辑回归模型的损失函数(其实就是我们后面要讲到的交叉熵损失cross-entropy),我们通常使用最大似然估计,即令每个样本属于其真实标记的概率越大越好。对于二分类而言,
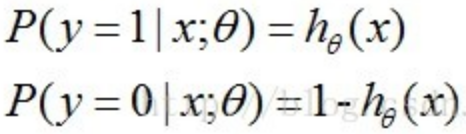 上面两个式子综合起来为:
上面两个式子综合起来为:
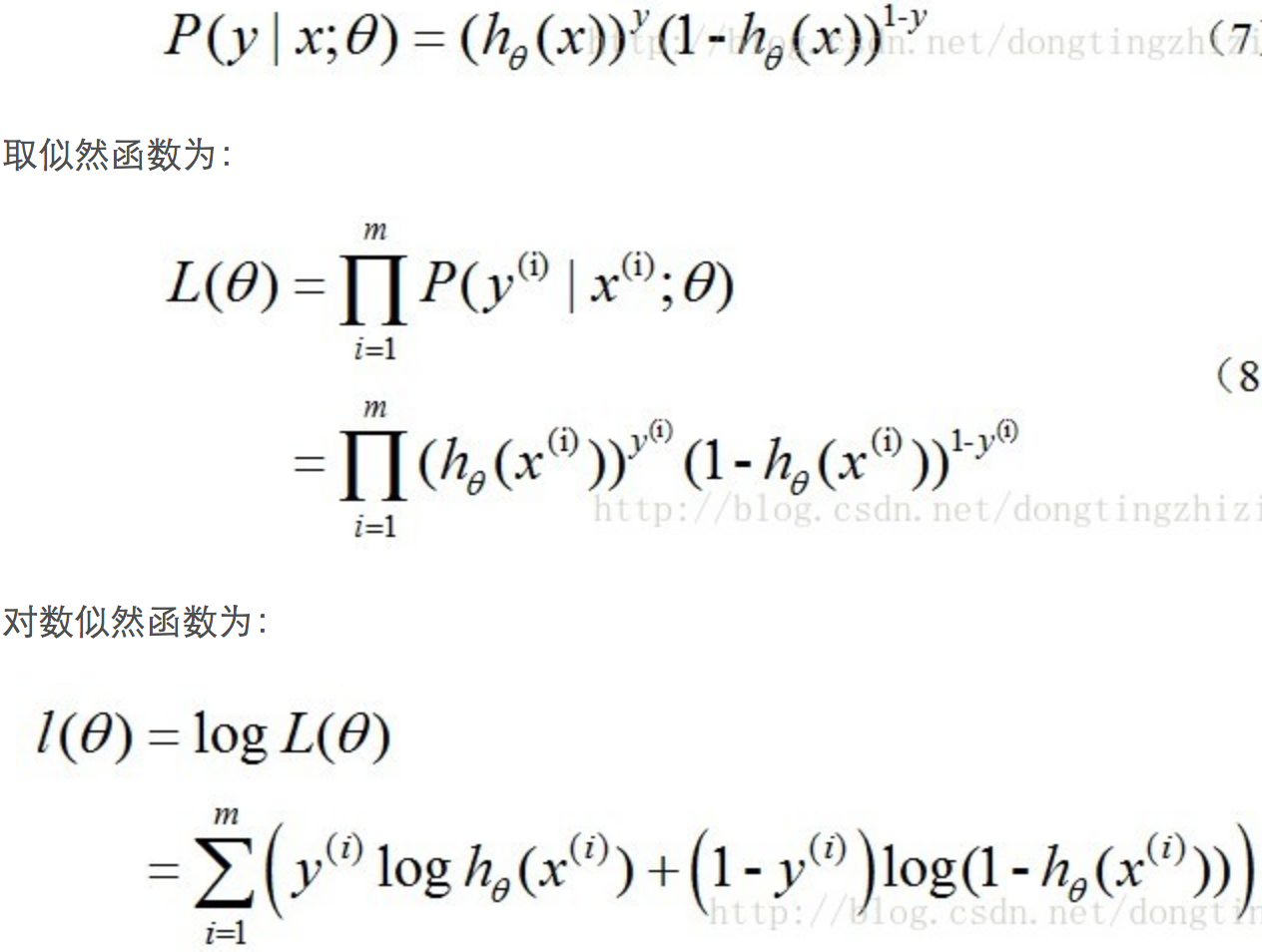
对于上面的损失函数,我们不能像线性回归模型一样求得解析解,所以对于逻辑回归模型的训练,我们一般用梯度下降法求解。参数的更新公式为:
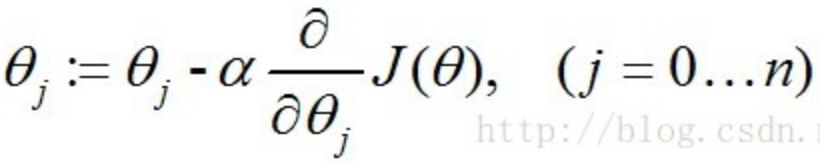
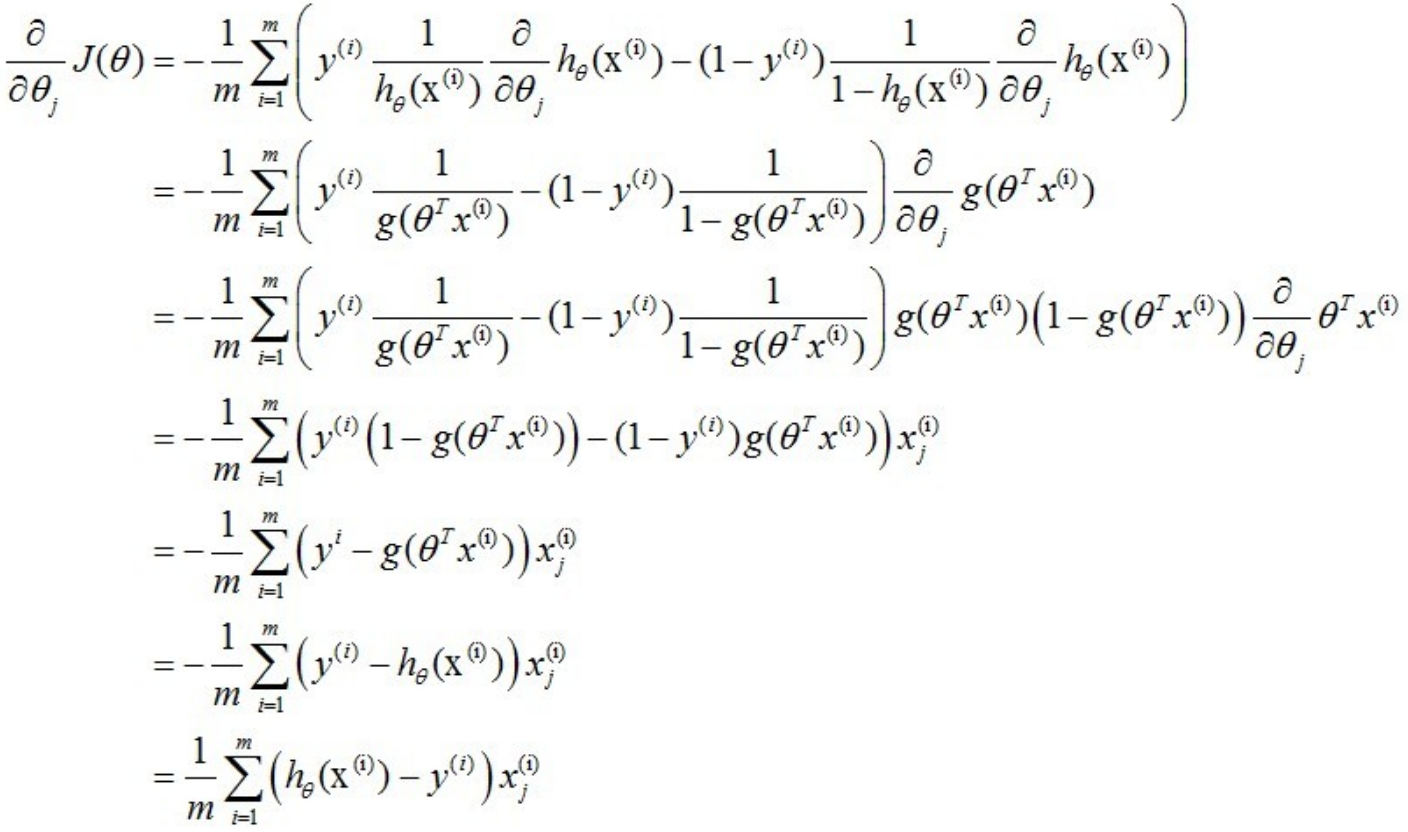 所以,参数的更新公式最终为:
所以,参数的更新公式最终为:
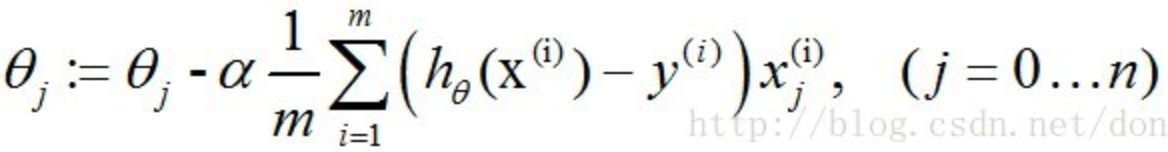
我们看到,逻辑回归的损失函数和训练过程都是通过二分类推到而来的,那么是不是就意味着逻辑回归模型只能用来处理二分类问题呢?答案是否定的,实际上逻辑回归把多分类看成是多个二分类问题,即每次将一个类的样本作为正例,其他所有类的样本作为反例来训练K个二分类器,在预测时将样本分别输入到K个分类器中,选择所有分类器中预测为正类的置信度(得分概率值)最大的类别作为分类结果。
但是这样做就带来了样本不均衡问题,即正类的样本数量严重偏少,解决方案除了对样本量多的类欠采样和对样本量少的类过采样外,还可以通过阈值移动。

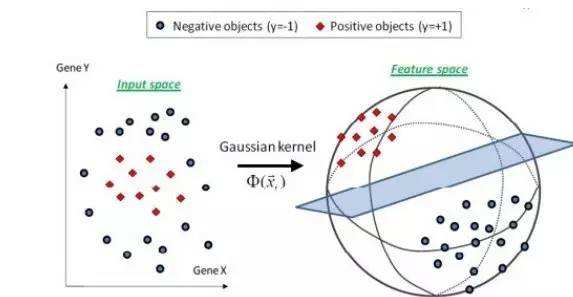
由于逻辑回归本身是一种对数线性模型,所以无法解决非线性分类问题,需要添加kernel trick,即通过核函数将特征由低阶(低维空间)向高阶(高维空间)变换,以使得样本在高维空间线性可分。这是一个去线性化的过程,其实跟线性回归中的Polynomial回归(将输入特征乘n次方作为新的特征训练线性回归模型)有点类似。
但是由于核函数的训练过程相对复杂,以至于sklearn的逻辑回归算法包中没有提供相应的支持,核函数在SVM模型中应用更加普遍。
模型训练
代码地址 https://github.com/qianshuang/ml-exp
def train():
print("start training...")
# 处理训练数据
# train_feature, train_target = process_file(train_dir, word_to_id, cat_to_id) # 词频特征
train_feature, train_target = process_tfidf_file(train_dir, word_to_id, cat_to_id) # TF-IDF特征
# 模型训练
model.fit(train_feature, train_target)
def test():
print("start testing...")
# 处理测试数据
test_feature, test_target = process_file(test_dir, word_to_id, cat_to_id)
# test_predict = model.predict(test_feature) # 返回预测类别
test_predict_proba = model.predict_proba(test_feature) # 返回属于各个类别的概率
test_predict = np.argmax(test_predict_proba, 1) # 返回概率最大的类别标签
# accuracy
true_false = (test_predict == test_target)
accuracy = np.count_nonzero(true_false) / float(len(test_target))
print()
print("accuracy is %f" % accuracy)
# precision recall f1-score
print()
print(metrics.classification_report(test_target, test_predict, target_names=categories))
# 混淆矩阵
print("Confusion Matrix...")
print(metrics.confusion_matrix(test_target, test_predict))
if not os.path.exists(vocab_dir):
# 构建词典表
build_vocab(train_dir, vocab_dir)
categories, cat_to_id = read_category()
words, word_to_id = read_vocab(vocab_dir)
# kNN
# model = neighbors.KNeighborsClassifier()
# decision tree
# model = tree.DecisionTreeClassifier()
# random forest
# model = ensemble.RandomForestClassifier(n_estimators=10) # n_estimators为基决策树的数量,一般越大效果越好直至趋于收敛
# AdaBoost
# model = ensemble.AdaBoostClassifier(learning_rate=1.0) # learning_rate的作用是收缩基学习器的权重贡献值
# GBDT
# model = ensemble.GradientBoostingClassifier(n_estimators=10)
# xgboost
# model = xgboost.XGBClassifier(n_estimators=10)
# Naive Bayes
model = naive_bayes.MultinomialNB()
# logistic regression
model = linear_model.LogisticRegression()
train()
test()
运行结果:
read_category...
read_vocab...
start training...
start testing...
accuracy is 0.933000
precision recall f1-score support
家居 0.93 0.87 0.90 89
游戏 1.00 0.98 0.99 104
体育 0.97 0.99 0.98 116
时尚 1.00 0.89 0.94 91
房产 0.77 0.94 0.85 104
时政 0.99 0.78 0.87 94
娱乐 0.95 0.99 0.97 89
财经 0.97 0.94 0.96 115
教育 0.84 0.94 0.89 104
科技 0.99 0.99 0.99 94
avg / total 0.94 0.93 0.93 1000
Confusion Matrix...
[[ 77 0 1 0 6 0 0 0 5 0]
[ 0 102 1 0 0 0 0 0 0 1]
[ 0 0 115 0 0 1 0 0 0 0]
[ 1 0 0 81 0 0 4 0 5 0]
[ 4 0 0 0 98 0 0 0 2 0]
[ 0 0 0 0 11 73 0 3 7 0]
[ 0 0 1 0 0 0 88 0 0 0]
[ 0 0 0 0 7 0 0 108 0 0]
[ 0 0 0 0 5 0 1 0 98 0]
[ 1 0 0 0 0 0 0 0 0 93]]
社群
- QQ交流群

- 微信交流群

- 微信公众号
