算法原理
最大熵模型(Max Entroy,MaxEnt),在所有满足约束条件的模型集合中,熵最大的模型是最好的模型。论及投资,人们常说不要把鸡蛋放在一个篮子里,这样分散投资可以降低风险,进而达到收益最大化,因为越平均(越分散,能保留全部的不确定性),熵越大。

下面我们引入特征函数的概念,特征函数是特征的函数式表示,跟特征一样,需要通过特征工程得到。
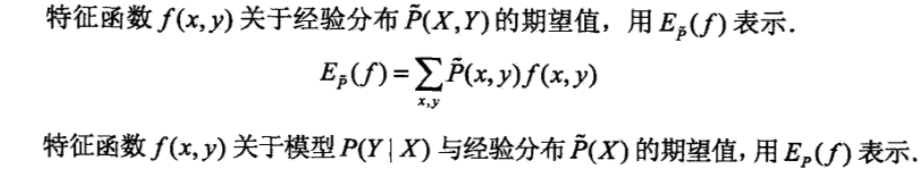
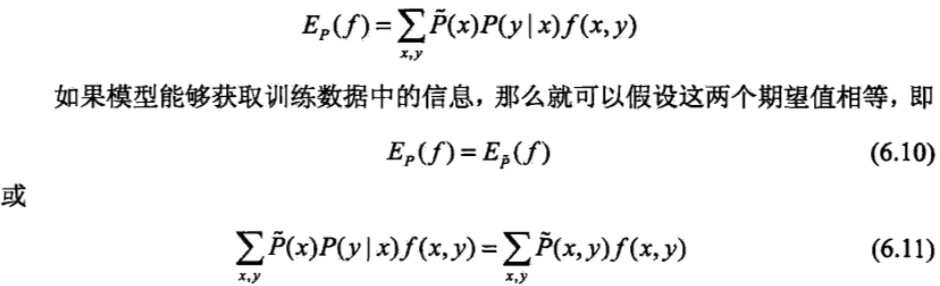
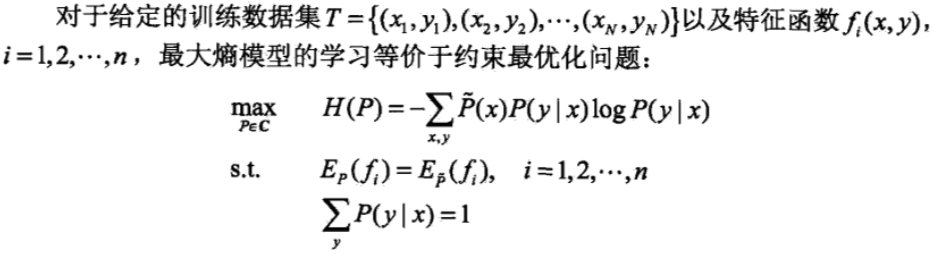 其实可以证明求熵的最大值等价于最大熵模型的极大似然估计。
求解方式我们应该已经很熟悉了,使用拉格朗日乘子法,然后利用偏导数为0,求得:
其实可以证明求熵的最大值等价于最大熵模型的极大似然估计。
求解方式我们应该已经很熟悉了,使用拉格朗日乘子法,然后利用偏导数为0,求得:
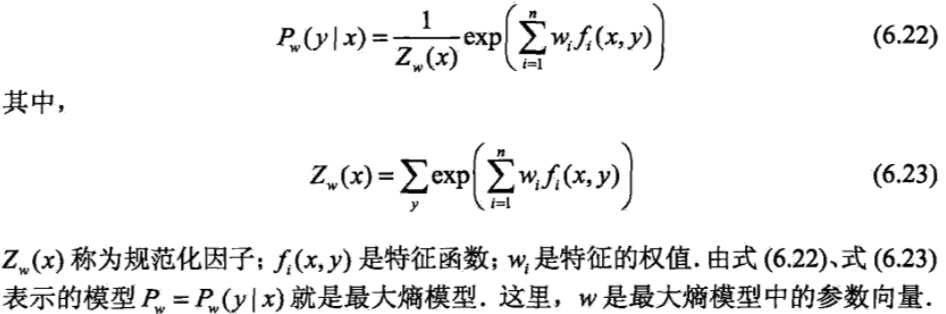 通过观察可以发现,最大熵模型和逻辑回归模型的softmax版本有完全一模一样的形式,所以完全可以在给定训练数据的条件下,对模型进行极大似然估计,然后通过随机梯度下降来进行训练。实际中对于最大熵模型的训练,通常采用改进的迭代尺度算法(IIS)和拟牛顿法。
通过观察可以发现,最大熵模型和逻辑回归模型的softmax版本有完全一模一样的形式,所以完全可以在给定训练数据的条件下,对模型进行极大似然估计,然后通过随机梯度下降来进行训练。实际中对于最大熵模型的训练,通常采用改进的迭代尺度算法(IIS)和拟牛顿法。
下面通过一个实际的例子来让大家直观的感受一下最大熵模型的训练过程: 对于我们的文本分类问题,假设我们有三个类别:C1、C2、C3,我们现在以词频作为特征函数,那么可以构造下面的一张特征函数表如下,x代表词频特征函数(word1在各个类别下出现的次数),λ代表特征函数权重。
| word1 | word2 | word3 | ··· | wordn | |
|---|---|---|---|---|---|
| C1 | λ11*x11 | λ12*x12 | λ13*x13 | ··· | λ1n*x1n |
| C2 | λ21*x21 | λ22*x22 | λ23*x23 | ··· | λ2n*x2n |
| C3 | λ31*x31 | λ32*x32 | λ33*x33 | ··· | λ3n*x3n |
假设某篇文章由word1、word2、word3组成,求这篇文章属于各个类别的概率?如何训练模型求出模型参数λ? 注意:最大熵模型的参数矩阵依然是5000 x 10,它的特征函数矩阵也是5000 x 10,我们取的是他们的点乘(dot product)作为w * f(x,y),然后再于词频输入特征做矩阵相乘;而逻辑回归和SVM直接是特征与模型参数的矩阵乘积作为预测score。
模型训练
代码地址 https://github.com/qianshuang/dl-exp
"""文本分类,maxent模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.float32, [None, self.config.vocab_size], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder_with_default(1.0, shape=())
self.log()
def log(self):
W = tf.Variable(tf.truncated_normal([self.config.vocab_size, self.config.num_classes], stddev=0.1))
# b = tf.Variable(tf.constant(0.1, shape=[self.config.num_classes]))
with tf.name_scope("score"):
# y_conv = tf.matmul(self.input_x, W) + b
y_conv = tf.matmul(self.input_x, W * self.config.F) # 特征函数与权重点乘
self.y_pred_cls = tf.argmax(y_conv, 1) # 预测类别
with tf.name_scope("optimize"):
self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=self.input_y, logits=y_conv))
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
运行结果:
Configuring MaxEnt model...
Loading training data...
2018-08-16 11:55:20.987253: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.2 instructions, but these are available on your machine and could speed up CPU computations.
2018-08-16 11:55:20.987276: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX instructions, but these are available on your machine and could speed up CPU computations.
2018-08-16 11:55:20.987281: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use AVX2 instructions, but these are available on your machine and could speed up CPU computations.
2018-08-16 11:55:20.987285: W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use FMA instructions, but these are available on your machine and could speed up CPU computations.
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 9.1e+02, Train Acc: 8.59%, Val Loss: 8.7e+02, Val Acc: 12.30%, Time: 0:00:01 *
Iter: 10, Train Loss: 4.6e+02, Train Acc: 15.62%, Val Loss: 4.5e+02, Val Acc: 18.10%, Time: 0:00:02 *
Iter: 20, Train Loss: 3.5e+02, Train Acc: 25.78%, Val Loss: 3.3e+02, Val Acc: 27.10%, Time: 0:00:04 *
Iter: 30, Train Loss: 2.2e+02, Train Acc: 43.75%, Val Loss: 2.5e+02, Val Acc: 40.40%, Time: 0:00:05 *
.......................
.......................
Epoch: 16
Iter: 1070, Train Loss: 0.11, Train Acc: 99.22%, Val Loss: 1.9e+01, Val Acc: 92.10%, Time: 0:02:08
Iter: 1080, Train Loss: 2.0, Train Acc: 98.44%, Val Loss: 1.8e+01, Val Acc: 92.10%, Time: 0:02:10
No optimization for a long time, auto-stopping...
Loading test data...
Testing...
Test Loss: 1.9e+01, Test Acc: 92.80%
Precision, Recall and F1-Score...
precision recall f1-score support
游戏 0.97 0.97 0.97 104
时尚 0.97 0.96 0.96 91
时政 0.93 0.80 0.86 94
教育 0.89 0.85 0.87 104
娱乐 0.93 0.96 0.94 89
家居 0.81 0.88 0.84 89
房产 0.89 0.95 0.92 104
科技 0.98 0.98 0.98 94
财经 0.94 0.96 0.95 115
体育 0.97 0.97 0.97 116
avg / total 0.93 0.93 0.93 1000
Confusion Matrix...
[[101 0 0 0 0 1 1 0 0 1]
[ 1 87 0 1 0 1 0 0 0 1]
[ 1 0 75 2 1 8 4 0 3 0]
[ 1 0 3 88 3 4 1 1 1 2]
[ 0 0 0 3 85 1 0 0 0 0]
[ 0 3 1 0 0 78 4 0 3 0]
[ 0 0 0 1 2 2 99 0 0 0]
[ 0 0 0 1 0 1 0 92 0 0]
[ 0 0 1 1 0 0 2 1 110 0]
[ 0 0 1 2 0 0 0 0 0 113]]
社群
- QQ交流群

- 微信交流群

- 微信公众号
