算法原理
条件随机场(Conditional Random Field,CRF),是在给定输入的条件下,求输出变量的条件概率分布模型。通常使用最广泛的是线性链条件随机场,即通过输入序列预测输出序列(序列标注),形式仍然是对数线性模型。若令X = {x1,x2,…,xn}为观测序列,Y = {y1,y2,…,yn}为与之相应的标记序列,则条件随机场的目标是构建条件概率模型P(Y|X)。
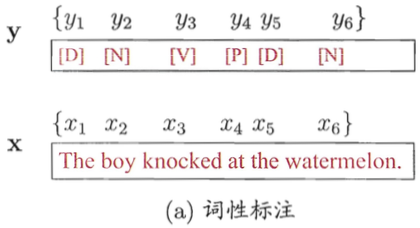
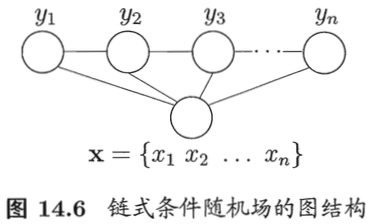
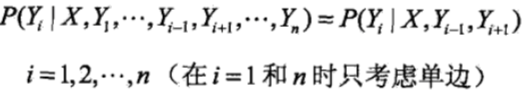 可以看到Yi与其前后的标记都相关。
可以看到Yi与其前后的标记都相关。

 条件随机场有如下简化形式:
条件随机场有如下简化形式:
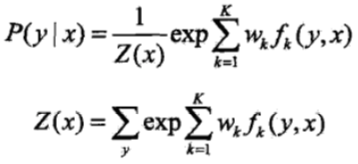 条件随机场模型的训练可以通过极大似然估计+随机梯度下降法求解,或者我们可以用后面将要学到的bi-LSTM + CRF,或者seq2seq。
条件随机场的预测问题是给定条件随机场P(Y|X)和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)y*,即对观测序列进行标注。由CRF的两类特征函数形式可知,其和HMM一样也有转移矩阵和发射矩阵,所以预测方法也是维特比算法。
条件随机场模型的训练可以通过极大似然估计+随机梯度下降法求解,或者我们可以用后面将要学到的bi-LSTM + CRF,或者seq2seq。
条件随机场的预测问题是给定条件随机场P(Y|X)和输入序列(观测序列)x,求条件概率最大的输出序列(标记序列)y*,即对观测序列进行标注。由CRF的两类特征函数形式可知,其和HMM一样也有转移矩阵和发射矩阵,所以预测方法也是维特比算法。
CRF比HMM要强大的多,HMM其实是CRF的一种特殊情况。在HMM模型中,当前的单词只依赖于当前的标签,当前的标签只依赖于前一个标签;但是CRF却可以着眼于整个句子s定义更具有全局性的特征函数,并且即使是线性链条件随机场,当前标签也依赖于其前后的标签。
参考文献:如何轻松愉快地理解条件随机场(CRF)?
模型训练
代码地址 https://github.com/qianshuang/NER
def train():
print("start training...")
# 处理CRF训练数据
train_feature, train_target = process_crf_file(crf_train_source_dir, crf_train_target_dir)
# 模型训练
crf_model.fit(train_feature, train_target)
def test():
print("start testing...")
# 处理测试数据
test_feature, test_target = process_crf_file(crf_test_source_dir, crf_test_target_dir)
# 去除无意义的标记O
labels = list(crf_model.classes_)
labels.remove('O')
print(labels)
# 返回预测标记
test_predict = crf_model.predict(test_feature)
# test_predict = crf_model.predict_single(test_feature[0]) # 预测单个样本
accuracy = metrics.flat_f1_score(test_target, test_predict, average='weighted', labels=labels)
# accuracy
print()
print("accuracy is %f" % accuracy)
# precision recall f1-score
print()
sorted_labels = sorted(
labels,
key=lambda name: (name[1:], name[0])
)
print(metrics.flat_classification_report(test_target, test_predict, labels=sorted_labels, digits=3))
# CRF
crf_model = sklearn_crfsuite.CRF(c1=0.1, c2=0.1, max_iterations=200, all_possible_transitions=True)
train()
test()
运行结果:
start training...
start testing...
['B-E', 'E-E', 'B-P', 'E-P', 'I-E', 'I-P']
accuracy is 0.870096
precision recall f1-score support
B-E 0.853 0.900 0.876 90
E-E 0.824 0.959 0.886 73
I-E 0.884 0.884 0.884 43
B-P 0.910 0.803 0.853 76
E-P 0.896 0.833 0.863 72
I-P 0.909 0.769 0.833 13
avg / total 0.873 0.872 0.870 367
社群
- QQ交流群

- 微信交流群

- 微信公众号
