算法原理
前面我们讲到,一段文字所包含的信息,就是它的信息熵。如果对这段信息进行无损压缩编码,理论上编码后的最短长度就是它的信息熵大小。如果仅仅是用来做区分,则远不需要那么长的编码,任何一段信息(文字、语音、视频、图片等),都可以被映射(Hash编码)为一个不太长的随机数,作为区别这段信息和其他信息的指纹,只要Hash算法设计得好,任何两段信息的指纹都很难重复。
SimHash是一种用来做文本查重的常用方法,是Google在2002年发明的一项技术,其特点是,如果两个文本的SimHash值差别越小,这两个网页的相似性就越高。下面我们来看一下它是怎么做到的?
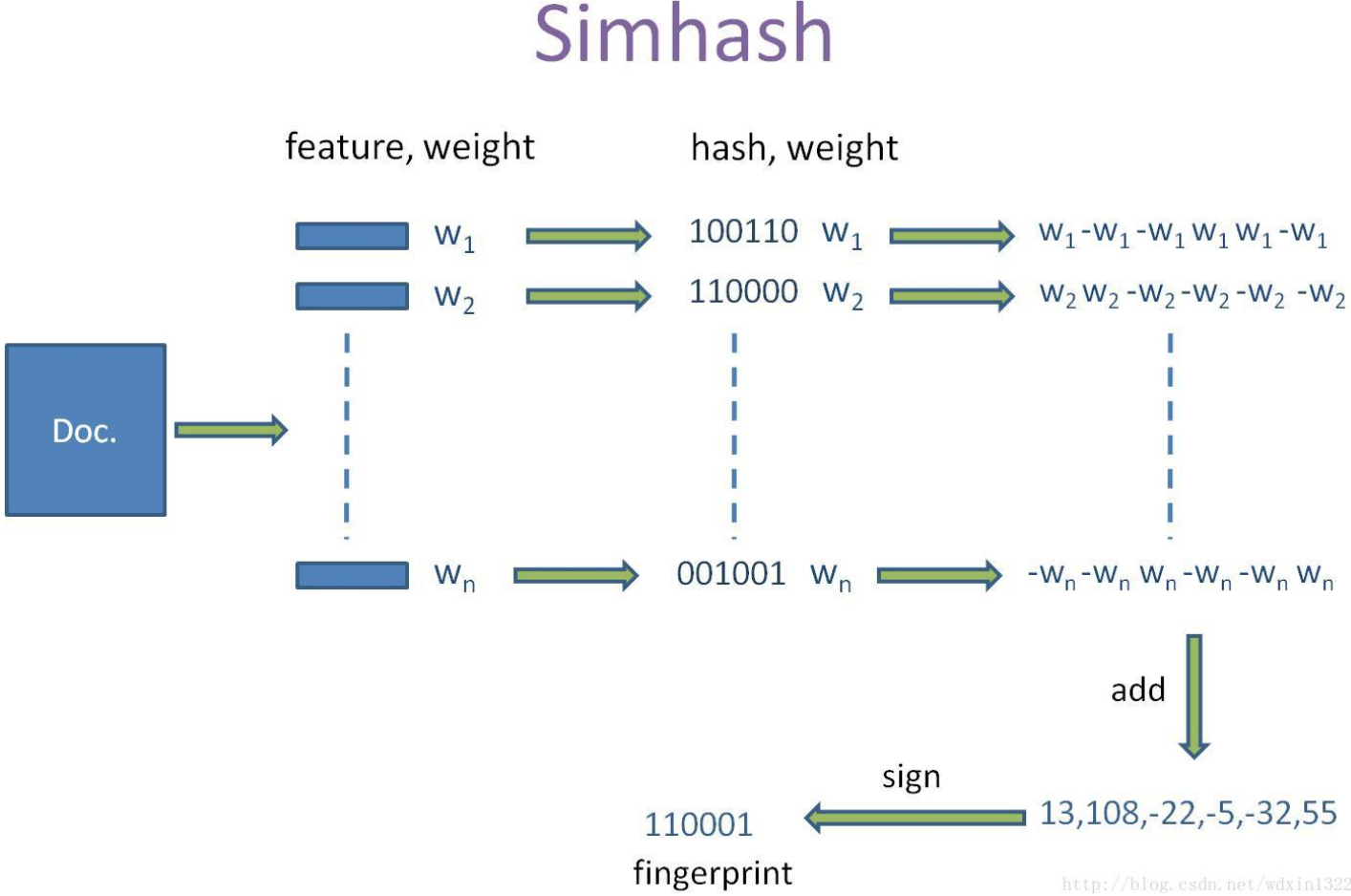
- 将一个f维的向量V初始化为0,f位的二进制数S也初始化为0;
- 对每一个特征(分词),用传统的hash算法对该特征产生一个f位的二进制签名b;
- 对i=1到f,如果b的第i位为1,则该位的值即为该特征的权重值(TF-IDF),如果为0,则为负的权重值;
- 将所有特征的权重向量按位相加赋值给V;
- 如果V的第i个元素值大于0,则S的第i位为1,否则为0;
- 输出S作为最终签名,即SimHash值。
对两篇文档的SimHash值,计算它们的海明距离(Simhash值之间不同位的个数)。可以有如下高效的实现:
int hamdistance(uint64_t sim1, uint64_t sim2){
uint64_t xor_val = sim1 ^ sim2;
int distance = 0;
while(xor_val > 0){
xor_val = xor_val & (xor_val - 1);
distance++;
}
return distance;
}
int main(int argc, char *argv[]){
uint64_t sim1 = 851459198;
uint64_t sim2 = 847263864;
int dis = hamdistance(sim1, sim2);
printf("hamdistance of %lu and %lu is %d", sim1, sim2, dis);
}
加密算法(MD5、SHA-1等)也是将不定长的信息变成定长的128位或160位二进制随机数,但是加密算法的一个明显特征是,两段信息哪怕只有微小的不同,最终结果也会截然不同。 SimHash的最大特点就是它的局部敏感性。
- 因为SimHash算法最终是将权重值相加,而加法满足交换律,所以对词的顺序不敏感;
- 如果两篇文章只有少数权重小的词不相同,几乎可以肯定它的SimHash值也会相同。 SimHash去重非常高效:一是指纹的计算可以离线进行,而是海明距离的计算也非常高效(直接异或,还可以使用Hash分桶原理,假如我们认为海明距离在3以内的具有很高的相似性,我们可以将simhash值分成4段,那么至少有一段完全相等的情况下才能满足海明距离在3以内)。
通过大量测试,simhash用于比较大文本,比如500字以上效果都还蛮好,距离小于3的基本都是相似,误判率也比较低。但是如果我们处理的是微博信息,最多也就140个字,使用simhash的效果并不那么理想,我们测试短文本很多看起来相似的距离确实为10,如果使用距离为3,短文本大量重复信息不会被过滤,如果使用距离为10,长文本的错误率也非常高。
利用SimHash原理实现的经典应用还有以图搜图:相似图像检索
社群
- QQ交流群

- 微信交流群

- 微信公众号
