TensorFlow是Google在2015年开源的深度学习框架,基本原理也很简单,首先你需要定义一张计算图,然后TensorFlow拿到计算图并优化执行,最重要的是,他能将图切成多个chunk,然后并行的在多个CPU或GPU上运行,并且支持分布式训练。因此它支持海量数据和百万级参数的模型训练。 TensorFlow,顾名思义,就是Tensor在计算图上流转构成的Flow。
TensorFlow的安装非常简单:
pip3 install --upgrade tensorflow
上面默认安装的是CPU版本,如果你的硬件支持,你也可以安装tensorflow-gpu版本。
下面我们通过代码为大家介绍TensorFlow的一些基本用法。
import tensorflow as tf
print(tf.__version__) # 输出版本号,测试安装
# 定义两个变量x,y和函数表达式f(x,y)
# 这段变量及函数定义代码并不执行任何计算,只是创建了一张TensorFlow计算图,而且变量都还没有被真正的赋予值
x = tf.Variable(3, name="x") # 在计算图上创建一个变量定义节点
y = tf.Variable(4, name="y")
f = x*x*y + y + 2 # 在计算图上创建一个表达式计算节点
# 1. 想要计算值,我们需要打开一个TensorFlow session,用它来给变量初始化并执行计算
# 2. TensorFlow session负责将计算放置在CPU或GPU上运行,默认是放置在GPU上
sess = tf.Session()
sess.run(x.initializer)
sess.run(y.initializer)
result = sess.run(f) # 执行计算
print(result)
sess.close() # 释放资源
# 更优雅的写法如下
with tf.Session() as sess: # with块中,sess被设置为默认session,执行完后自动释放资源
x.initializer.run() # 等价于tf.get_default_session().run(x.initializer)
y.initializer.run()
result = f.eval() # 等价于tf.get_default_session().run(f)
print(result)
# 更更优雅的写法
init = tf.global_variables_initializer() # 在计算图上创建一个全局初始化节点
with tf.Session() as sess:
init.run() # 真正的初始化所有变量
result = f.eval()
print(result)
# 更更更优雅的写法
sess = tf.InteractiveSession() # 自动设置其后所有操作的默认session,不需要with块
init.run()
result = f.eval()
print(result)
sess.close()
一个TensorFlow程序可以分为两部分,首先创建计算图,然后运行计算图。 创建计算图相当于构建深度学习模型的网络结构,执行计算图相当于迭代的通过mini-batch往计算图输送数据,并执行计算图中的每一步1以训练模型参数。
图管理
import tensorflow as tf
x1 = tf.Variable(1) # 创建的每一个节点被自动添加到默认图
print(x1.graph is tf.get_default_graph()) # True
# 大多数情况下你只会构建一张计算图,但有时候你可能想要构建多张独立的计算图,每张计算图上构建不同的网络结构
graph = tf.Graph() # 创建一张新图
with graph.as_default(): # with块中临时设置新图为默认图
x2 = tf.Variable(2)
print(x2.graph is graph) # True
print(x2.graph is tf.get_default_graph()) # False
print(x2.graph is x1.graph) # False
变量的生命周期
import tensorflow as tf
# 下面的w,x,y,z都是tensor,将tensor转为值,需要sess.run(x),或者x.eval()
a = 5
b = tf.convert_to_tensor(a) # 将值类型转为tensor
w = tf.constant(3) # 定义一个常量
x = w + 2
y = x + 5
z = x * 3
# 注意,TensorFlow在执行计算z的时候,并不会重用计算y时已经计算好了的x和w,而是会重新计算x和w
with tf.Session() as sess:
print(y.eval()) # 10
print(z.eval()) # 15
# 下面的方式可以做到变量值重用
with tf.Session() as sess:
y_val, z_val = sess.run([y, z])
print(y_val) # 10
print(z_val) # 15
变量的作用域
import tensorflow as tf
# 对于Variable变量,如果检测到命名冲突,系统会自动处理
w_1 = tf.Variable(3, name="w_1", trainable=False) # trainable=False,不需要训练的变量,默认True
w_2 = tf.Variable(3, name="w_1")
w_3_1 = tf.get_variable(name="w_1", initializer=1) # get_variable变量与Variable变量可以同名
print(w_1.name) # w_1:0
print(w_2.name) # w_1_1:0
print(w_3_1.name) # w_1_2:0
# get_variable也可以用来创建变量,当命名冲突时,系统会报错
w_3 = tf.get_variable(name="w_2", initializer=1)
print(w_3.name) # w_2:0
# w_4 = tf.get_variable(name="w_2", initializer=2) # ValueError: Variable w_2 already exists, disallowed.
with tf.variable_scope("scope1"): # 变量共享,详细用法见方法注释
w1 = tf.get_variable("w1", shape=[])
w2 = tf.Variable(0.0, name="w2")
with tf.variable_scope("scope1", reuse=True):
w1_p = tf.get_variable("w1", shape=[])
w2_p = tf.Variable(0.0, name="w2")
with tf.variable_scope("", default_name="", reuse=True): # 可以使用root scope,效果同上
w1_p_r = tf.get_variable("scope1/w1")
# 如果不知道变量名,可以使用下面的方法,或者去TensorBoard查看
for variable in tf.global_variables():
print(variable.name)
# 由于tf.Variable()每次都在创建新对象,所有reuse=True和它并没有什么关系
print(w1 is w1_p, w2 is w2_p) # True False
print(w1.name, w2.name, w1_p.name, w2_p.name) # scope1/w1:0 scope1/w2:0 scope1/w1:0 scope1_1/w2:0
w = tf.constant(3)
# 拿到所有的变量(Variable或者get_variable),拿不到常量
print(tf.global_variables()) # [<tf.Variable 'w_1:0' shape=() dtype=int32_ref>, <tf.Variable 'w_1_1:0' shape=() dtype=int32_ref>,...]
# 拿到所有的需要训练的(trainable=True)变量,优化器只会优化此集合中的变量
print(tf.trainable_variables())
所有创建的变量(Variable或者get_variable),会自动被当前的计算图所收集,默认情况下,收集在图集合GraphKeys.GLOBAL_VARIABLES中。 trainable=True的变量还会被收集在GraphKeys.TRAINABLE_VARIABLES中。
TensorFlow中的节点有两种。一种是定义变量(variable),一种是定义操作(ops)。
import tensorflow as tf
with tf.variable_scope("foo"):
v = tf.get_variable("v", [1])
# v = tf.Variable([1], name="v", dtype=tf.float32)
x = 1.0 + v
# variable_scope影响了ops的name
print(x.op.name) # "foo/add"
print(x.name) # foo/add:0
with tf.variable_scope("foo", reuse=True): # reuse只对get_variable变量起作用,对Variable无效,并且可以继承
with tf.name_scope("bar"): # 相当于java中的包名,在TensorBoard中用来折叠变量,如果重名,TensorFlow会自动rename
v1 = tf.get_variable("v", [1])
x = 1.0 + v1 # foo_1/bar/add:0
# name_scope对变量名无影响
print(v.name) # foo/v:0
# name_scope影响了ops的name
print(x.op.name) # foo_1/bar/add
print(x.name) # foo_1/bar/add:0
# x不再是一个变量,而变成了一个常量tensor
print(tf.global_variables()) # [<tf.Variable 'foo/v:0' shape=(1,) dtype=float32_ref>]
print(tf.trainable_variables()) # [<tf.Variable 'foo/v:0' shape=(1,) dtype=float32_ref>]
tensor的shape
e1 = tf.get_variable('e1', [5000, 64]) # 定义二维Tensor
print(e1.shape) # (5000, 64)
print(e1.get_shape()) # (5000, 64),上一句方法的别名,只能拿到编译时的shape
# 创建一个在运行时返回X的shape的ops,能够在运行时拿到具体shape
print(tf.shape(e1)) # Tensor("Shape:0", shape=(2,), dtype=int32)
e1_ = tf.reshape(e1, [64, -1])
print(e1_.shape) # (64, 5000)
# e2 = tf.get_variable('e2', [None, 64]) # 报错:ValueError: Shape of a new variable (e2) must be fully defined, but instead was (?, 64).
placeholder 对于Mini-batch Gradient Descent,模型训练在每次迭代的过程中,需要输入新的batch数据,这时我们可以声明一个placeholder作占位。
A = tf.placeholder(tf.int32, shape=(None, 3)) # 第一个None表示此值未知,根据传入的数据推断出
print(A.shape) # (?, 3)
A_shape = tf.shape(A)[0]
B = A + A_shape
with tf.Session() as sess:
B_val_1 = B.eval(feed_dict={A: [[1, 2, 3]]})
B_val_1 = sess.run(B, feed_dict={A: [[1, 2, 3]]}) # 效果同上
B_val_2 = B.eval(feed_dict={A: [[4, 5, 6], [7, 8, 9]]})
print(B_val_1) # [[2 3 4]]
print(B_val_2) # [[ 6 7 8], [ 9 10 11]]
模型的导出与加载 模型需要在训练过程中定期保存checkpoint,这样当机器crash后,可以快速从checkpoint恢复。
theta = tf.Variable(4, name='theta')
plus = theta + 10
training_op = tf.assign(theta, plus)
init = tf.global_variables_initializer()
# 在构件图完成后,创建一个saver节点
# saver = tf.train.Saver({"weights": theta})
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
sess.run(training_op)
# 在执行图阶段,可以随时调用save方法,保存模型,保存传入的session所在的图上的所有节点
save_path = saver.save(sess, "tmp/my_model.ckpt")
with tf.Session() as sess:
# 在执行的开始阶段,加载模型,加载传入的session所在的图上的所有节点,这时候不需要sess.run(init),因为加载过程已经初始化好了(但是注意所有变量已定义)
saver.restore(sess, "tmp/my_model.ckpt")
print(theta.name) # theta:0
print(sess.run(theta)) # 14
print(tf.global_variables()) # [<tf.Variable 'theta:0' shape=() dtype=int32_ref>]
TensorBoard TensorBoard是TensorFlow内置的基于浏览器的可视化组件,通过它你可以看到你的graph定义,最重要的是可以方便观察损失函数、accuracy的曲线,帮助我们更快定位问题,找出瓶颈。
theta = tf.Variable(4, name='theta')
plus = theta + 10
training_op = tf.assign(theta, plus)
init = tf.global_variables_initializer()
# 在构件图完成后,创建一个summary节点,默认添加到图集合GraphKeys.SUMMARIES
mse_summary = tf.summary.scalar('MSE', training_op)
# 每次运行前清空该目录,否则TensorBoard会合并已有内容,使可视化混乱
file_writer = tf.summary.FileWriter("tmp/tensorboard/", tf.get_default_graph())
with tf.Session() as sess:
sess.run(init)
summary_str = mse_summary.eval()
# 记录日志数据和当前迭代步数
file_writer.add_summary(summary_str, 50)
file_writer.add_summary(summary_str, 100)
# 关闭FileWriter
file_writer.close()
在训练模型时,通常的写法如下:
for batch_index in range(n_batches):
X_batch, y_batch = fetch_batch(epoch, batch_index, batch_size)
if batch_index % 10 == 0:
summary_str = mse_summary.eval(feed_dict={X: X_batch, y: y_batch})
step = epoch * n_batches + batch_index
file_writer.add_summary(summary_str, step)
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
下面启动TensorBoard:
# 命令行输入如下命令,启动tensorboard web server
$ tensorboard --logdir tmp/tensorboard/
Starting TensorBoard on port 6006
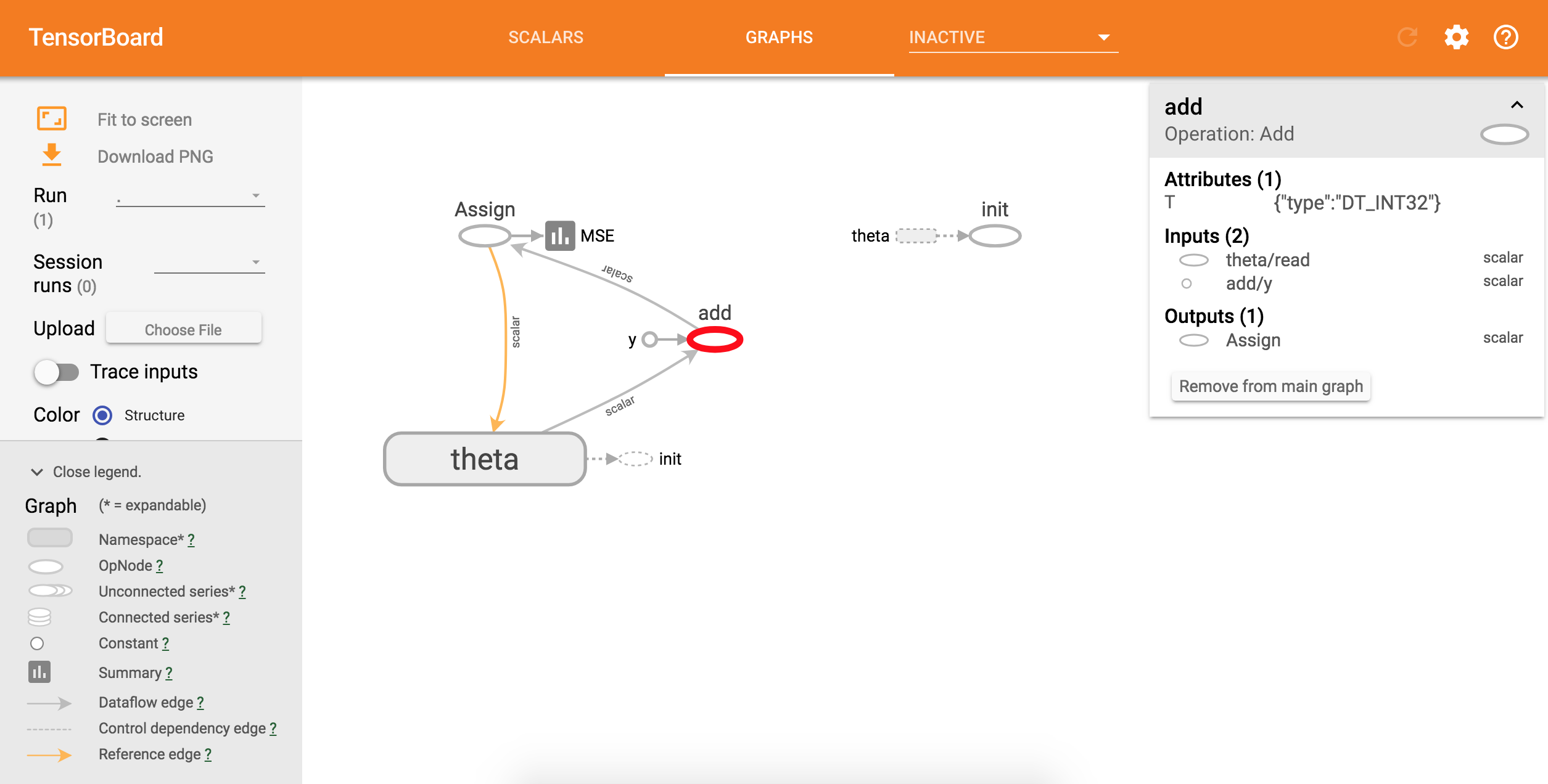 可以从上图看到各节点的定义,包括Variables和ops。
可以从上图看到各节点的定义,包括Variables和ops。
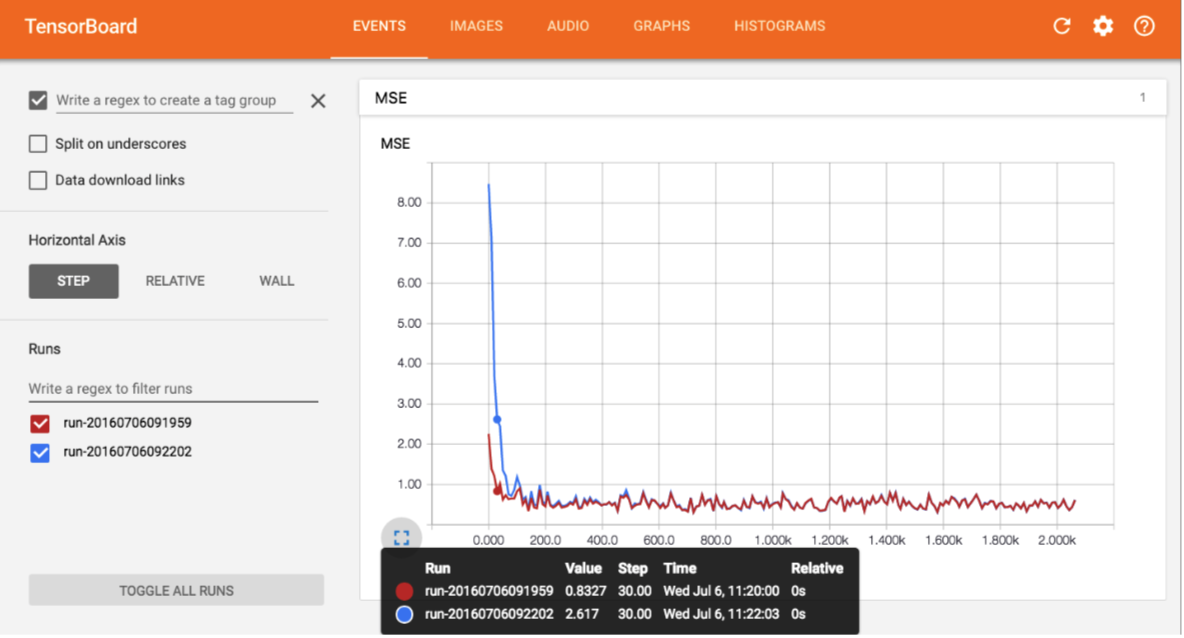 可以从上图看到损失函数MSE的训练曲线。
可以从上图看到损失函数MSE的训练曲线。
tensorflow实现逻辑回归:代码地址 logistic_regression_tensorflow
社群
- QQ交流群

- 微信交流群

- 微信公众号
