word2vec
word2vec,顾名思义就是word to vector,最早的词向量化方式是词袋模型,即将每个词打成一个one-hot向量,向量的维度就是词表的大小。这种粗糙处理方式的弊端显而易见的:
- 词表一般很大,所以这些词组合起来是一个高维的稀疏矩阵,计算时导致内存灾难。
- one-hot向量表示和词ID表示一样,没有任何的语义含义。词与词之间的编辑距离永远是2,及时他们之间有明显的相似性。
那么我们能不能想办法把自然语言中的每一个词,表示成统一语义空间内的统一维度的稠密向量,这时每个词不再是词典中无任何意义的ID表示,而是具有一定语义的词向量表示,语义相近的词,其向量也接近。
自然语言是人类智慧的结晶,所以每个词应该包含丰富的维度和特征,将每一维度上的特征数字化,就是word2vec的基本思想。
不光词可以用这样的分布式表示,分类的label也可以用label embedding表示,尤其是当label之间并不严格互斥时,可以用label embedding来表示他们之间复杂的相似性。
那么怎么得到每个词的稠密向量表示呢?当然是通过海量数据训练得到,训练word2vec的方式主要有两种:CBOW与Skip-Gram。
CBOW(Continuous Bag-of-Words),是指我们输入某一个特定词的上下文相关的词对应的one-hot向量作为输入特征X(注意与顺序无关并且出现多次只记一次),该特定词对应的one-hot向量作为label,通过DNN训练分类模型,得到word2vec。比如下面这段话,我们的上下文大小取值为4,特定的这个词是”Learning”,上下文对应的词有8个,前后各4个,这8个词所对应的bag of words向量是我们CBOW模型的输入特征X,”Learning”这个词的bag of words向量是我们的输入label。也就是说CBOW是利用特定词上下文的词来预测该词。

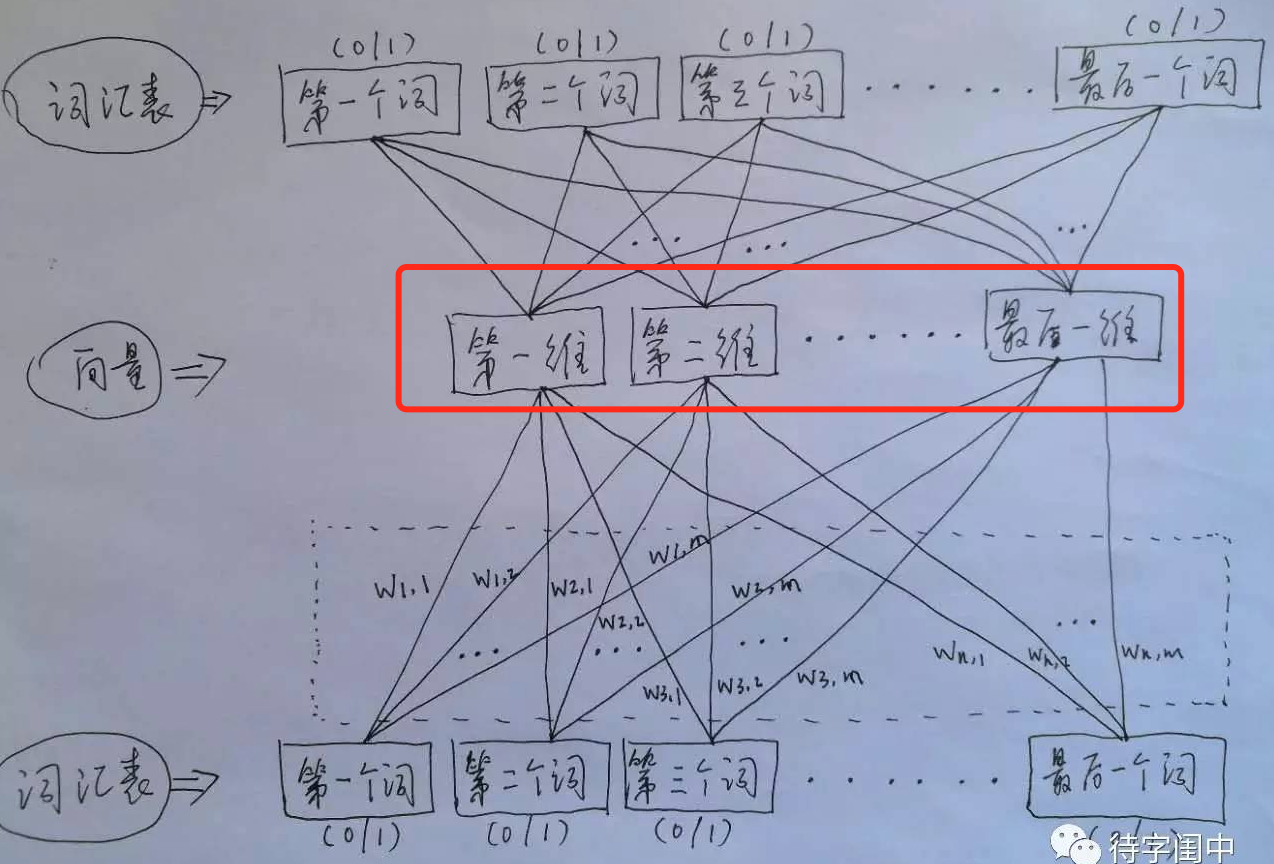 上图中红框内容就是所有词的词向量矩阵。
上图中红框内容就是所有词的词向量矩阵。
DNN计算图如下,W1矩阵就是我们要求的word2vec:
self.input_x = tf.placeholder(tf.float32, [None, self.config.vocab_size], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.vocab_size], name='input_y')
# hidden layer
W1 = tf.Variable(tf.truncated_normal([self.config.vocab_size, self.config.emb_size], stddev=0.1)) # 隐藏层64个神经元
b1 = tf.Variable(tf.constant(0.1, shape=[self.config.emb_size]))
y_conv_1 = tf.matmul(self.input_x, W1) + b1
layer_1 = tf.nn.relu(y_conv_1) # 激活函数
# output layer
W2 = tf.Variable(tf.truncated_normal([self.config.emb_size, self.config.vocab_size], stddev=0.1))
b2 = tf.Variable(tf.constant(0.1, shape=[self.config.vocab_size]))
y_conv = tf.matmul(layer_1, W2) + b2
self.y_pred_cls = tf.argmax(y_conv, 1) # 预测类别
可以发现第一个隐藏层的作用实际上就是将每个词的word2vec加和,如果将每个词的ont-hot向量加和,就是词频向量。
Skip-Gram则刚好相反,即输入特征是一个特定词的bag of words词向量,而输入label是该特定词对应的上下文词的bag of words词向量表示,所以这是一个多label的分类问题(其实仍然可以通过cross_entropy计算交叉熵损失作为损失函数)。还是上面的例子,我们的上下文大小取值为4,我们的输入是特定词”Learning”的bag of words词向量,预测结果是softmax概率排前8的8个词。也就是说Skip-Gram是利用特定词来预测其上下文的词。
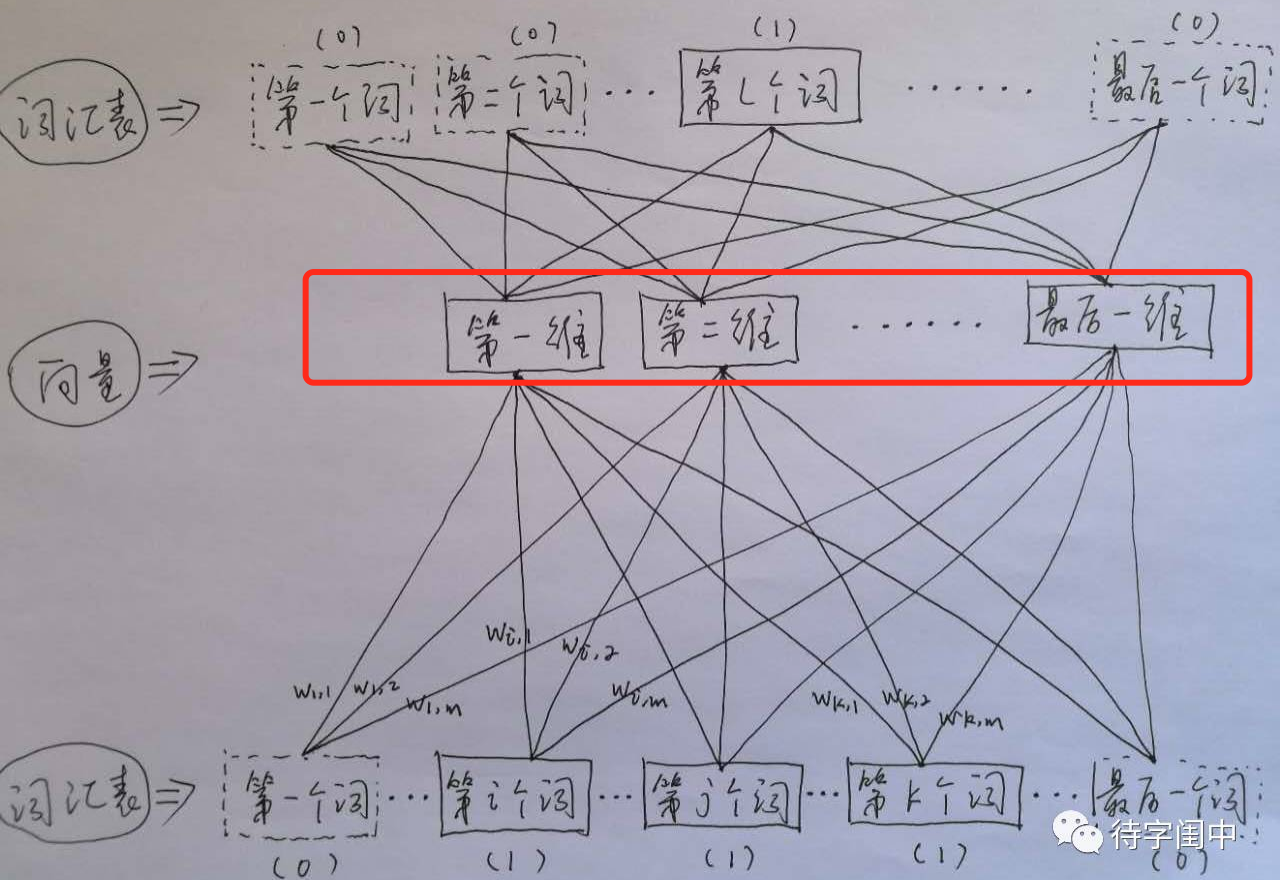 图中红框内容就是所有词的词向量矩阵。
图中红框内容就是所有词的词向量矩阵。
注意:word2vec的训练没有办法做early stopping和dropout,所以需要设置最大迭代步数。
负采样
不管是CBOW还是Skip-Gram,我们都需要输出层进行softmax输出每一个词汇表中的词可能出现的概率。这时的参数数量5000 * 64 + 64 * 5000,并且输出层有5000个输出值,导致训练过于缓慢。解决办法是通过负采样(Negative Sampling)。
对于CBOW我们怎么做负采样呢?比如我们有一个训练样本,中心词是w0,它周围上下文共有2c个词,记为context(w0)。由于这个中心词w0的确和context(w0)相关存在,因此我们把w0和context(w0)拼接起来作为一个真实的正例。通过Negative Sampling采样,我们得到neg个和w0不同的中心词wi,i=1,2,..neg,这样context(w0)和wi,i=1,2,..neg拼接就组成了neg个并不真实存在的负例。我们不停的进行这种负采样,直到产生足够多的样本后,对这些样本进行二分类,模型结构同上,只不过只有两个输出值。(其实我们也可以在模型的输出层做负采样,即先让模型输出5000个值,每个值代表每个输出单词得分,然后从这5000个中随机采样neg个得分,要包含正例,计算softmax_cross_entropy)
对于Skip-Gram,我们可以将中心词w0和上下文context(w0)的每个词两两组合作为正例,再通过负采样不在上下文context(w0)里面的词作为负例,同样的网络结构训练二分类模型。
最终都可以得到我们想要的词向量矩阵。
gensim训练word2vec
gensim是一个很好用的Python NLP的包,它封装了google的C语言版的word2vec,其实不光可以用来做word2vec,还有很多其他的方法可以使用。
from gensim.models import word2vec
sentences = word2vec.LineSentence('./train_data_segment.txt') # 分词后的文件
# 训练word2vec
model = word2vec.Word2Vec(sentences)
# 导出文本格式的word2vec
model.save("./text8.model")
# 导出二进制格式的word2vec
model.save_word2vec_format("./text8.model.bin", binary=True)
# 加载word2vec对象
model= word2vec.Word2Vec.load_word2vec_format("./text8.model.bin", binary=True)
加载预训练词向量
现在假设我们通过大规模语料训练完成了word2vec,那么怎样通过TensorFlow加载进模型使用呢?
首先来看下训练得到的词向量文件格式:第一行为词向量个数和词向量维度,剩下每一行为一个单词和其对应的词向量,以空格分隔。
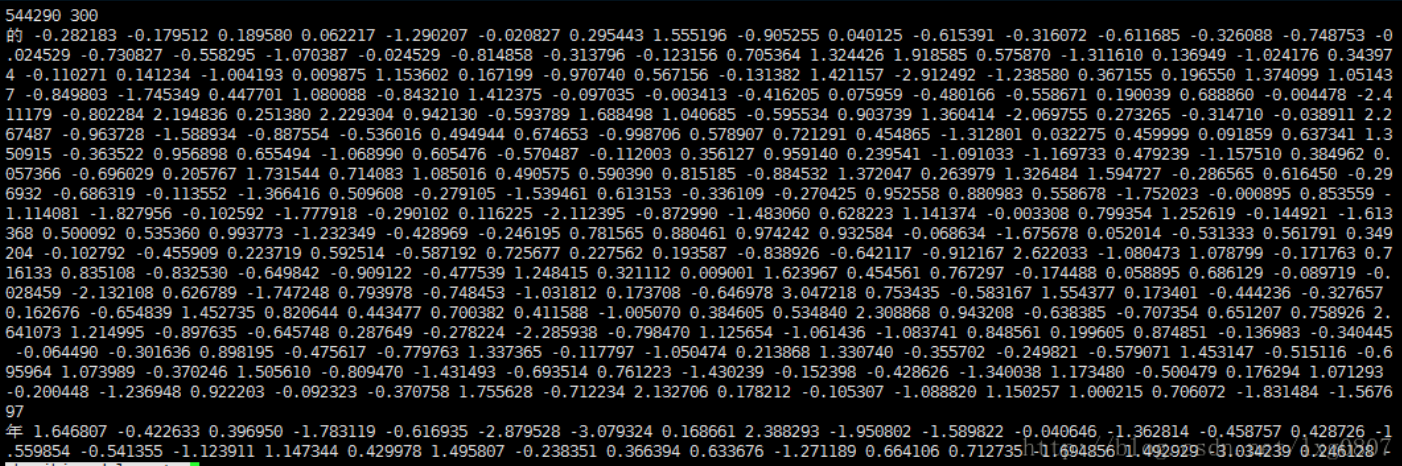
def loadWord2Vec(filename):
vocab = [] # 词典
embd = [] # Word embedding
cnt = 0
fr = open(filename,'r')
line = fr.readline().decode('utf-8').strip() # 读取第一行内容
word_dim = int(line.split(' ')[1]) # 词向量维度
vocab.append("unk") # 生僻字词向量为全0
embd.append([0]*word_dim)
for line in fr:
row = line.strip().split(' ')
vocab.append(row[0])
embd.append(row[1:])
fr.close()
return vocab,embd
vocab,embd = loadWord2Vec(filename)
vocab_size = len(vocab)
embedding_dim = len(embd[0])
embedding = np.asarray(embd)
# 需要先将embedding转为Variable或tensor,input_x为word id
emb_tensor = tf.Variable(embedding, trainable=False)
# emb_tensor = tf.convert_to_tensor(emb) # 转换为常量tensor
embedding_inputs = tf.nn.embedding_lookup(emb_tensor, input_x)
fasttext
Fasttext是Facebook2016年开源的文本分类和词训练工具,其最大的特点是模型简单,只有一层的隐层以及输出层,因此训练速度非常快,在普通的CPU上可以实现分钟级别的训练。同时,在多个标准的测试数据集上,Fasttext都有不错的表现。
Fasttext主要有两个功能,一个是训练词向量,另一个是文本分类。
词向量的训练,相对于word2vec来说,增加了subwords特性。subwords其实就是一个词的character-level的n-gram。比如单词”hello”,长度至少为3的char-level的ngram有”hel”,”ell”,”llo”,”hell”,”ello”以及本身”hello”,每个ngram都可以用一个稠密的向量Zg表示,于是整个单词”hello”就可以表示表示为所有subwords的加权求和:
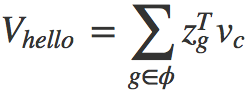 这样做有什么好处呢?无非就是丰富了词表示的层次,就像中文可以拆开成偏旁部首一样。
这样做有什么好处呢?无非就是丰富了词表示的层次,就像中文可以拆开成偏旁部首一样。
Fasttext的另一个功能是做文本分类,其模型结构和word2vec的CBOW模型非常类似:
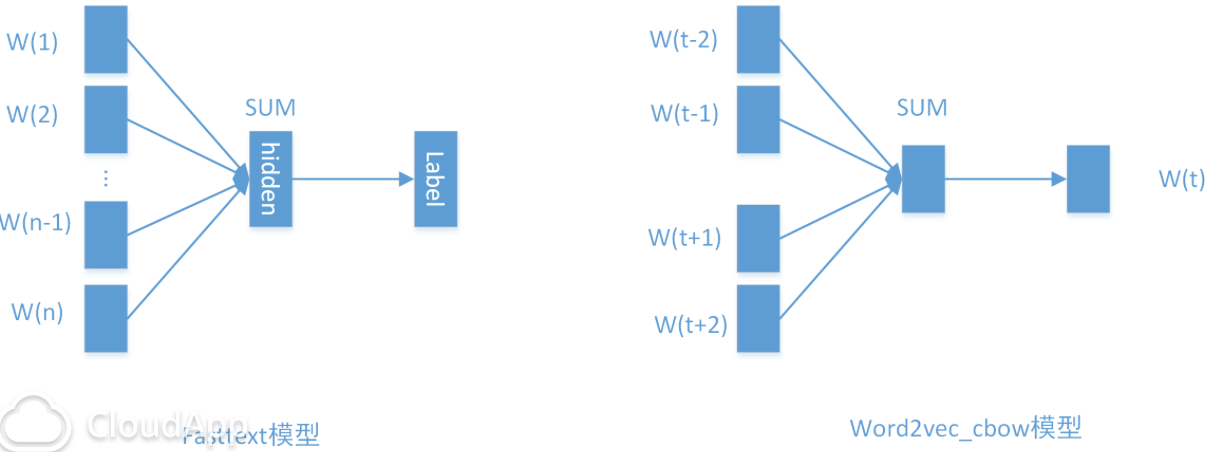 当类别数较少时,直接套用softmax层并没有效率问题,但是当类别很多时,softmax层的计算就比较费时了,所以fasttext也支持negative sampling(想当于基于label embedding的QA match)。
当类别数较少时,直接套用softmax层并没有效率问题,但是当类别很多时,softmax层的计算就比较费时了,所以fasttext也支持negative sampling(想当于基于label embedding的QA match)。
Fasttext模型有个致命的问题,就是丢失了词顺序的信息,因为隐层是通过简单的求和取平均得到的(注意这里考虑了词频),为了弥补这个不足,Fasttext增加了N-gram的特征。
具体做法是把N-gram当成一个词,也用embedding向量来表示,在计算隐层时,把N-gram的embedding向量也加进去求和取平均。举个例子来说,假设某篇文章只有3个词:W1、W2、W3,N-gram的N取2,w1、w2、w3以及w12、w23分别表示词W1、W2、W3和bigram W1W2,W2W3的embedding向量,那么文章的隐层可表示为:
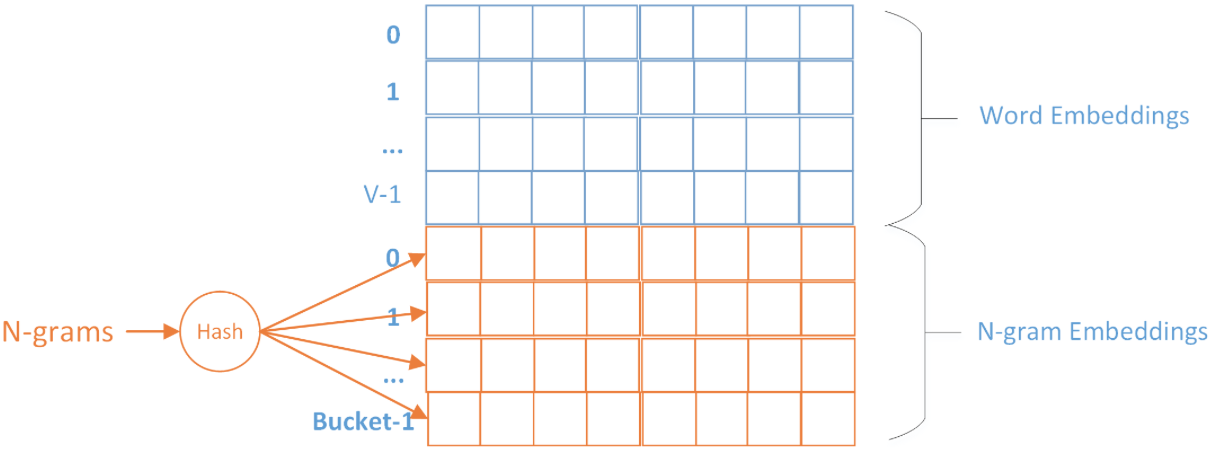
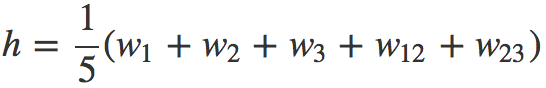 具体实现上,由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。Fasttext采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector。
具体实现上,由于n-gram的量远比word大的多,完全存下所有的n-gram也不现实。Fasttext采用了Hash桶的方式,把所有的n-gram都哈希到buckets个桶中,哈希到同一个桶的所有n-gram共享一个embedding vector。
模型训练
代码地址 https://github.com/qianshuang/ml-exp
print("start training...")
fasttext_train_file = process_fasttext_file(train_dir, True)
model = fasttext.supervised(fasttext_train_file, "model/fasttext.model", epoch=50)
print("start testing...")
fasttext_test_file = process_fasttext_file(test_dir, False)
# model = fasttext.load_model('model/fasttext.model', label_prefix='__label__')
result = model.test(fasttext_test_file)
# model.predict_proba()
print(result.precision)
运行结果:
start training...
start testing...
0.97
社群
- QQ交流群

- 微信交流群

- 微信公众号
