算法原理
今天我想带着大家一起来探讨两个基于CNN的经典架构,一个是ContextCNN,一个是HierarchicalCNN,这两个架构都是工业界常用的CNN模型。 我们上节课说到的TextCNN模型,都是要先将Text做Flatten,然后在打平之后的Text上做一维卷积,这样简单粗暴的做法其实打乱了文本内部的Context信息,试想一下我们的文章除了字与字之间存在N-gram的关系,句子与句子之间也存在N-gram的关系,而这种上下文关系对于最终任务是非常有意义的。尤其像对对话机器人这种应用,需要结合上下文(多轮对话)才能理解用户的真正意图。
ContextCNN
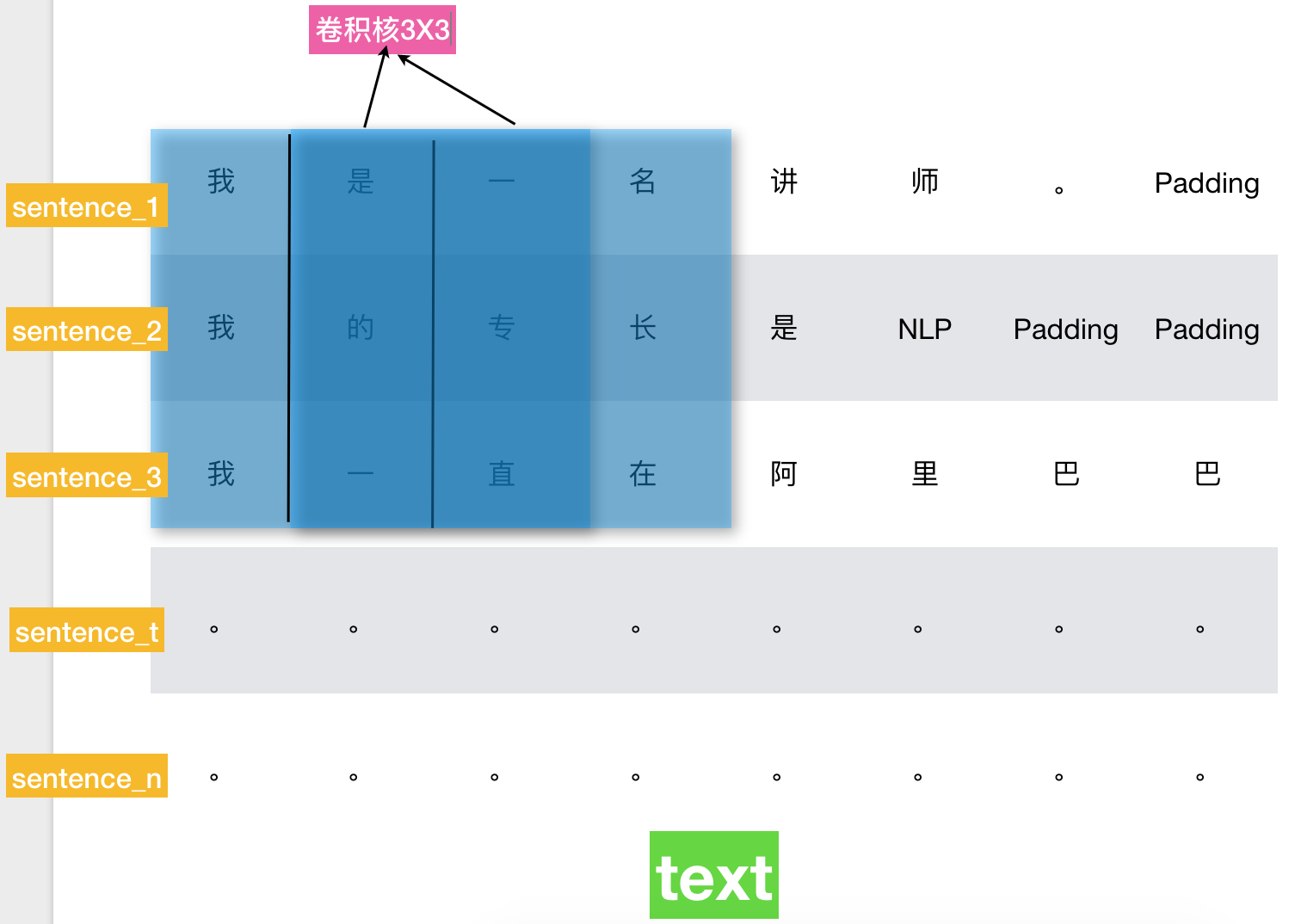
ContextCNN模型是一种非常简单但是非常有效的基于上下文的文本处理模型,它不需要做文本Flatten,而是先将文本拆成一个个语义完整的句子,把原本只有一维的文章变成text_length * sentence_length的二维矩阵(text_length为一篇文章的句子数量,sentence_length为每个句子的词数量,不足则做Padding),然后在此矩阵上做二维卷积操作。
input_x = tf.placeholder(tf.int32, [None, self.config.text_length, self.config.sentence_length], name='input_x')
input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
# 词向量映射
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
# 卷积核为3X3X64,第一个3代表提取句与句之间的3-gram特征,第二个3代表提取每一句的词与词之间的3-gram特征,64为word embedding维数。
# 当然可以使用不同size的卷积核以提取不同层次的N-gram特征。
filter_w_1 = tf.Variable(tf.truncated_normal([3, 3, 64, 128], stddev=0.1))
filter_b_1 = tf.Variable(tf.constant(0.1, shape=[128]))
conv_1 = tf.nn.conv2d(embedding_inputs, filter_w_1, strides=[1, 1, 1, 1], padding='SAME') + filter_b_1
h_conv_1 = tf.nn.relu(conv_1)
HierarchicalCNN
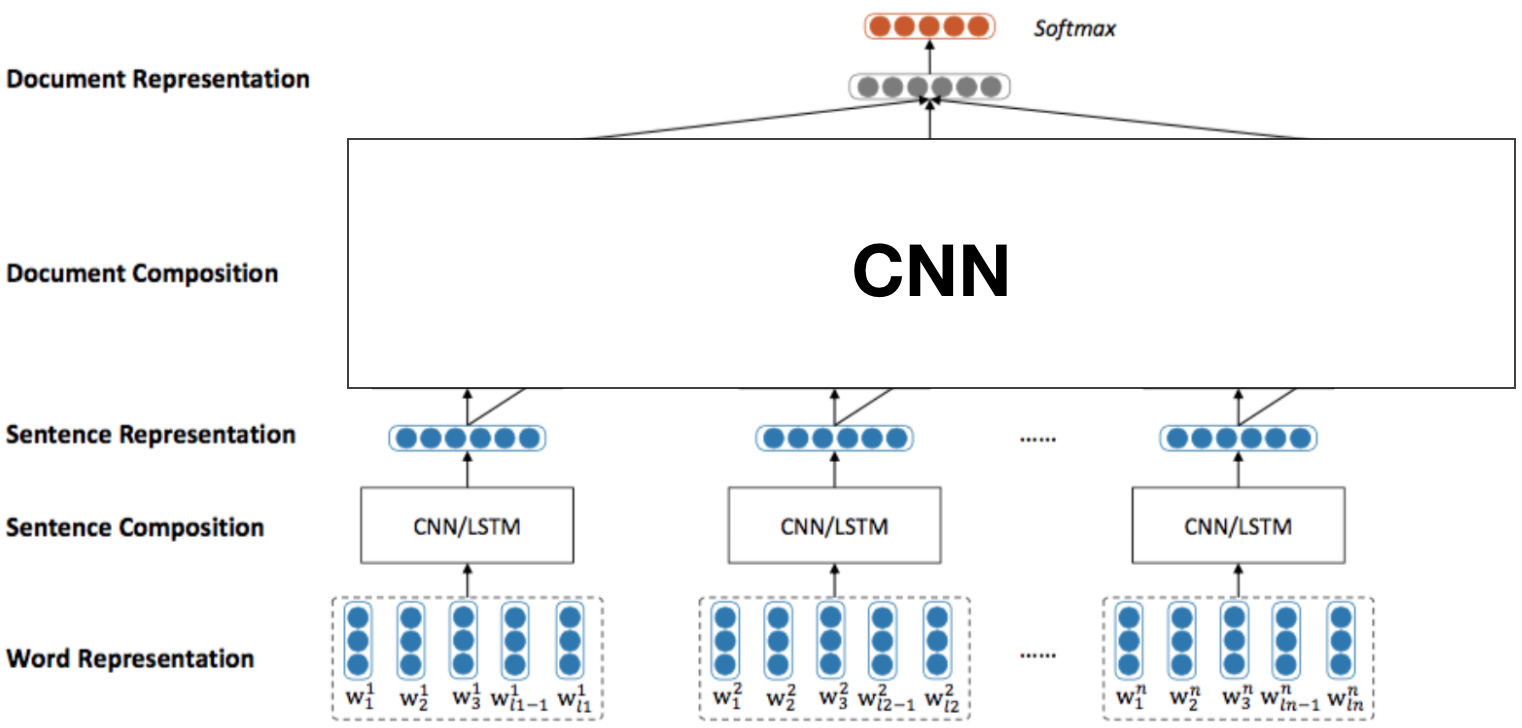
HierarchicalCNN即分层的CNN模型,它也是一种效果不错的基于上下文的CNN模型,它也是先将文本拆成一个个语义完整的句子,然后先在每个句子上做卷积操作,提取每个句子中词与词之间的N-gram特征,最终得到每个句子的representation,然后再将每个句子的representation做stack,组成每一篇文章,继续使用CNN操作提取每篇文章中句与句之间的N-gram特征,最终得到每篇文章的representation。简单来说,底层CNN提取更多的是syntax特征,顶层CNN提取更多的是semantics特征。
input_x = tf.placeholder(tf.int32, [None, self.config.text_length, self.config.sentence_length], name='input_x')
input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
# 词向量映射
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
# 1、单词级卷积
# 这一步很关键,首先需要reshape为[batch_size * sent_in_doc, word_in_sent, embedding_size]
embedding_inputs_word = tf.reshape(embedding_inputs, [-1, self.config.sentence_length, self.config.embedding_dim])
filter_w_1 = tf.Variable(tf.truncated_normal([self.config.kernel_size, self.config.embedding_dim, self.config.num_filters], stddev=0.1))
conv_1 = tf.nn.conv1d(embedding_inputs_word, filter_w, 1, padding='SAME')
h_conv_1 = tf.nn.relu(conv_1)
# 得到每个句子的representation,维度为self.config.num_filters
batch_sentence_representation = tf.reduce_max(h_conv_1, reduction_indices=[1])
# 2、句子级卷积
# 将输入还原为[batch_size, sent_in_doc, self.config.num_filters]
sent_input = tf.reshape(batch_sentence_representation, [-1, self.config.text_length, self.config.num_filters])
filter_w_2 = tf.Variable(tf.truncated_normal([self.config.kernel_size, self.config.num_filters, self.config.num_filters], stddev=0.1))
conv_2 = tf.nn.conv1d(sent_input, filter_w_2, 1, padding='SAME')
# 得到每篇文章的representation,维度为self.config.num_filters
batch_text_representation = tf.reduce_max(conv_2, reduction_indices=[1])
显然,ContextCNN与HierarchicalCNN都是基于上下文的CNN模型,ContextCNN只需要一次二维卷积就能提取到字与字、句与句之间的N-gram特征,而HierarchicalCNN则是通过分层的方式分别提取,进而能够得到更加细粒度的分层特征。
社群
- QQ交流群

- 微信交流群

- 微信公众号
