算法原理
RNN(Recurrent Neural Networks,循环神经网络),他的最大特点是时序性,在每一个time step,神经元接收当前的输入Xt,以及上一个time step的神经元的输出状态St-1一起产生当前的输出Yt,以及当前的状态St(St默认情况下和输出Yt相同)。
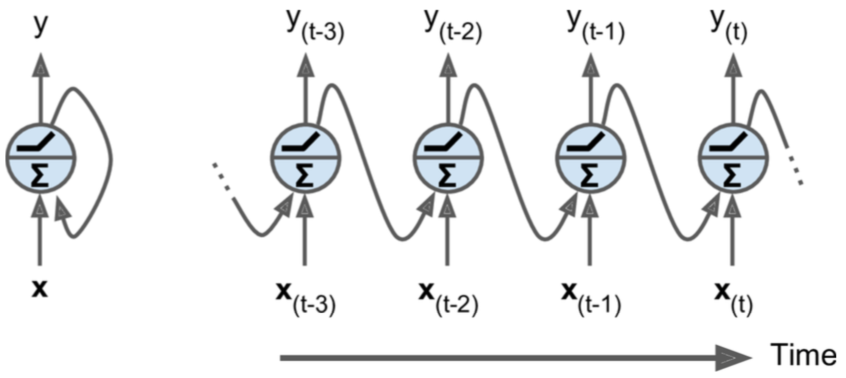 下面举个例子来说明,假设每个time step的状态是二维,并且输入输出都是一维,循环体中的权重矩阵W1=[[0.1,0.2],[0.3,0.4],[0.5,0.6]](两列代表有两个神经元),b1=[0.1,-0.1],输出的全连接层权重W2=[1.0,2.0],b2=[0.1],那么整个计算过程为:
下面举个例子来说明,假设每个time step的状态是二维,并且输入输出都是一维,循环体中的权重矩阵W1=[[0.1,0.2],[0.3,0.4],[0.5,0.6]](两列代表有两个神经元),b1=[0.1,-0.1],输出的全连接层权重W2=[1.0,2.0],b2=[0.1],那么整个计算过程为:
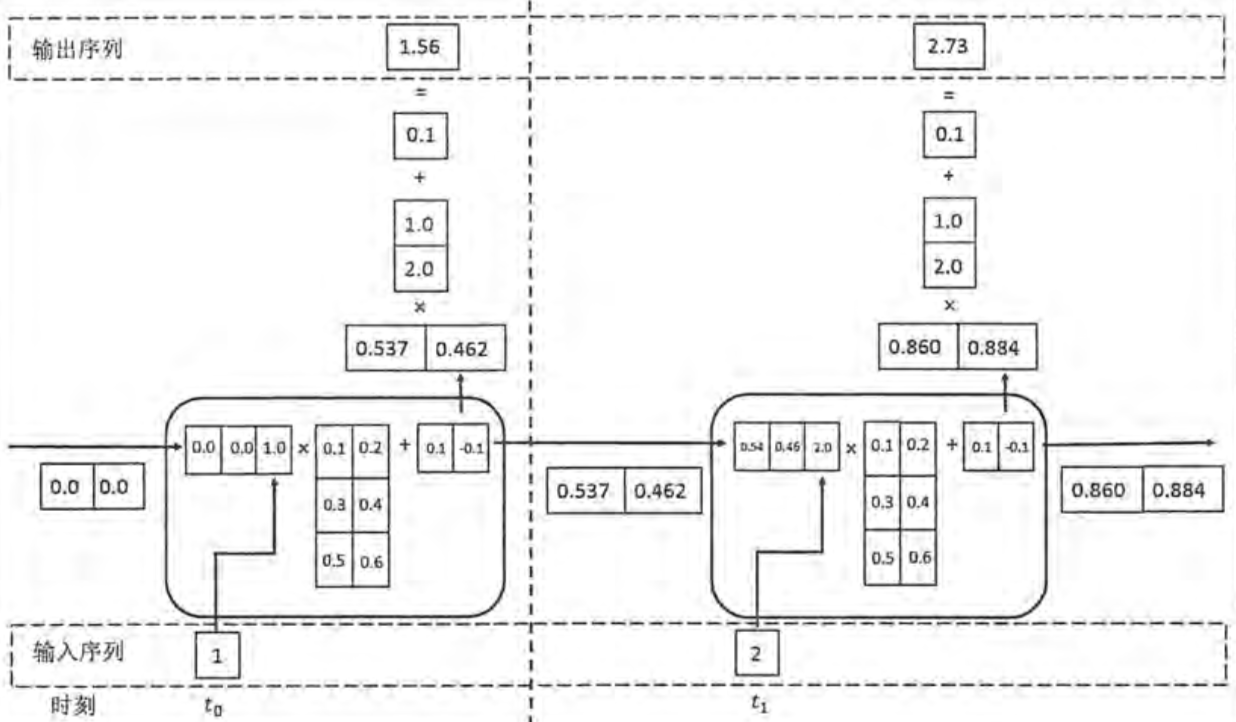 可以看到,两个神经元中,无论是循环体(又叫一个cell)中的权重矩阵,还是输出的全连接层权重矩阵也都是共享的。
可以看到,两个神经元中,无论是循环体(又叫一个cell)中的权重矩阵,还是输出的全连接层权重矩阵也都是共享的。
RNN的表现形式有很多种:
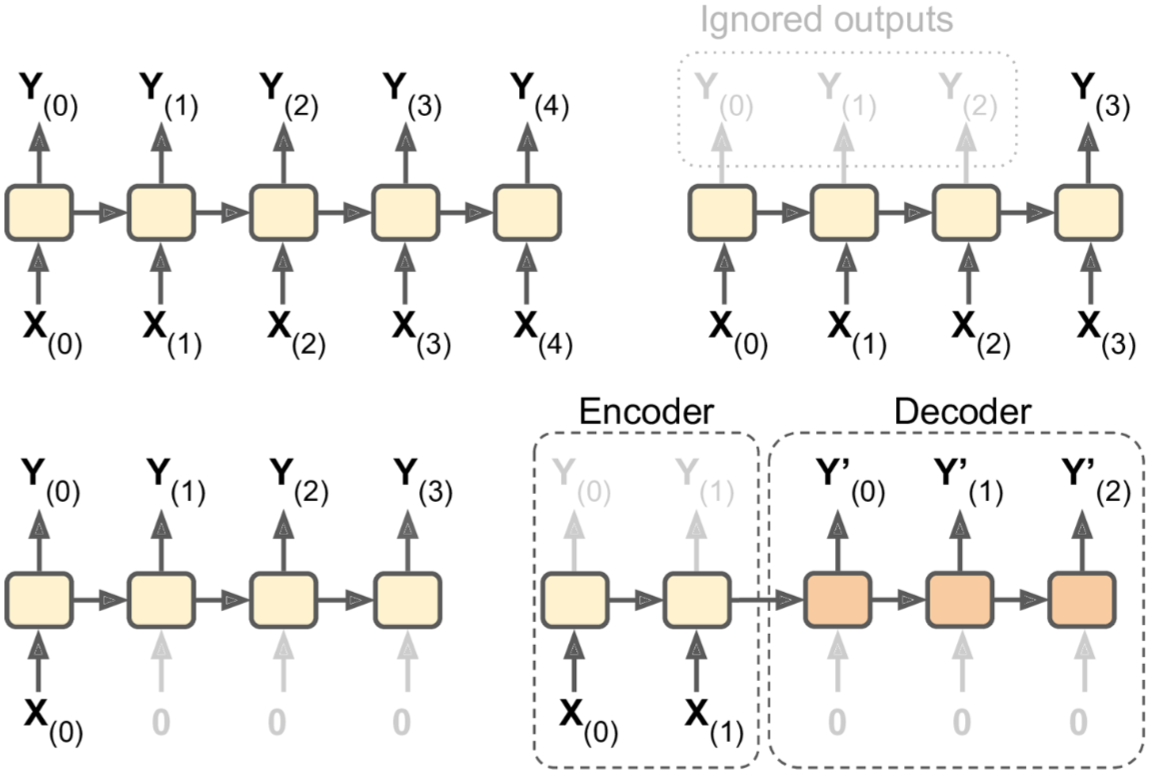 左上角为seq to seq:输入是一个序列,输出是一个序列。可以用来做股票预测,即输入过去N天的股票价格,输出明天到后N-1天的股票价格。在基于bi-LSTM和CRF的命名实体识别场景中,也用到了这种模型。
左上角为seq to seq:输入是一个序列,输出是一个序列。可以用来做股票预测,即输入过去N天的股票价格,输出明天到后N-1天的股票价格。在基于bi-LSTM和CRF的命名实体识别场景中,也用到了这种模型。
右上角为seq to vector:输入一个序列,但是只保留最后一个输出。可以用来做文本分类,输入文本序列,输出类别标签。
左下角为vector to seq:只在第一个time step输入真实数据,后面的time step输入0,输出为一个序列。比如看图说话,输入为一张图片,输出图片标题。还有一个重要应用场景就是我们后面要讲的端到端的OCR任务。
右下角为delayed seq to seq:又叫做Encoder–Decoder,典型的应用场景就是机器翻译。输入为一种语言的句子,encode模块先将输入转换为一个向量表示,decode模块再将该向量表示解码为另一种语言的句子。这种方式的效果比及时翻译(直接采用seq to seq)要好,因为后面的输入可能会影响先前的翻译结果,所以需要等到接收到整个输入句子再做翻译。
static rnn
X0 = tf.placeholder(tf.float32, [None, n_inputs])
X1 = tf.placeholder(tf.float32, [None, n_inputs])
# num_units就是循环体中的权重矩阵的列数
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons) # 这句话只是创建cell factory,并不产生实际的cell,但是会创建权重矩阵等参数
# 得到每个time step的输出和最终的状态
output_seqs, states = tf.contrib.rnn.static_rnn(basic_cell, [X0, X1], dtype=tf.float32)
# 输出的shape为[batch, num_units]
Y0, Y1 = output_seqs
有几点需要注意的是:
- 初始的状态矩阵初始化为全0。
- states为最终的状态矩阵,shape为(None, num_units),等于最终的输出值。
按照上面的做法,假如有50个time steps,你就需要定义50个input placeholders,过于复杂。所以一般是下面的简化方式:
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
# unstack表示将tensor在某一维度解包分裂
X_seqs = tf.unstack(tf.transpose(X, perm=[1, 0, 2]))
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
output_seqs, states = tf.contrib.rnn.static_rnn(basic_cell, X_seqs, dtype=tf.float32)
# stack表示将数组在某一维度压缩
outputs = tf.transpose(tf.stack(output_seqs), perm=[1, 0, 2]) # [None, n_steps, n_neurons]
上面的做法依然需要构建一张每一个time step一个RNN cell的大图(unstack后),而且在BP的过程中容易OOM,因为GPU的内存一般比CPU小得多。dynamic rnn可以解决这些问题。
dynamic rnn
- dynamic rnn内部使用一个while_loop()操作 to run over the cell with the appropriate number of times,也就是说每一个batch的time step数量可以不同(即text长度可变)。
- 你还可以设置swap_memory=True,当GPU内存不够时swap到CPU内存。
- 不再需要stack, unstack, transpose操作。
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs]) basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons) seq_length = tf.placeholder(tf.int32, [None]) # 可变的text长度 # outputs的shape:[None, n_steps, n_neurons] outputs, states = tf.nn.dynamic_rnn(basic_cell, X, dtype=tf.float32, sequence_length=seq_length)
注意:
- 对于长度不足sequence_length的text,后面的sequence_length - text_length部分的输出都是零向量。
- states取text_length位置的states作为最终的states。
- 其实输出也是可以有可变长度的,这时一般定义一个特殊的输出符EOS,所有EOS符之后的输出都将被忽略。
BPTT
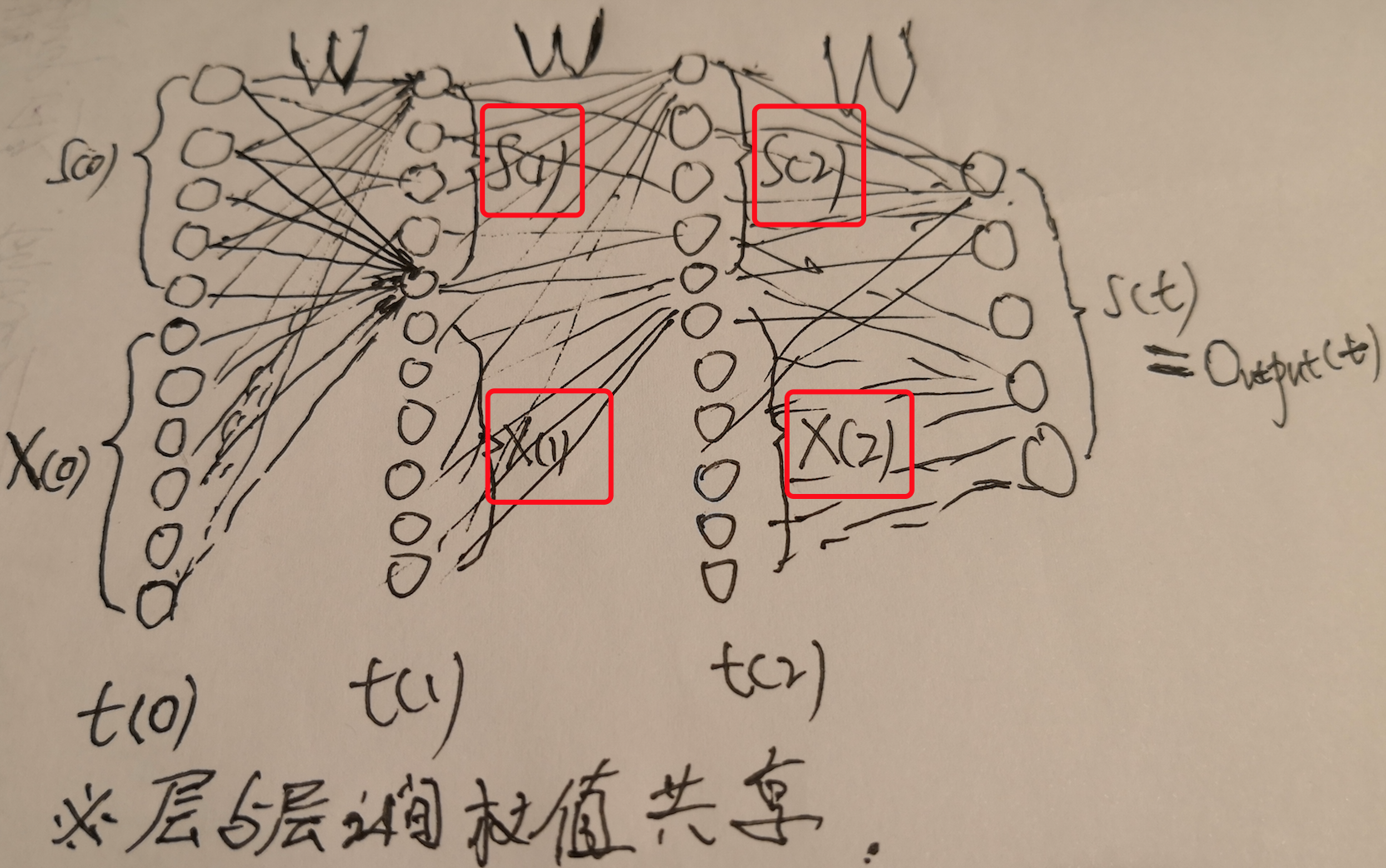 将RNN沿着time step展开后,其实就变成了DNN,每个time step是DNN的一层神经元,每层神经元的数目以及所有连接权重是共享的,而且每一层神经元的输入除了来自上一层神经元的输出外,还要接收当前time step的输入数据,这样展开后就可以通过传统的backpropagation来训练神经网络参数了,这种方式叫做BPTT(backpropagation through time)。
将RNN沿着time step展开后,其实就变成了DNN,每个time step是DNN的一层神经元,每层神经元的数目以及所有连接权重是共享的,而且每一层神经元的输入除了来自上一层神经元的输出外,还要接收当前time step的输入数据,这样展开后就可以通过传统的backpropagation来训练神经网络参数了,这种方式叫做BPTT(backpropagation through time)。
 注意:损失函数的计算依赖于每一个time step的输出结果,但是不包括忽略的输出(0输出)。
注意:损失函数的计算依赖于每一个time step的输出结果,但是不包括忽略的输出(0输出)。
RNN应用
文本分类
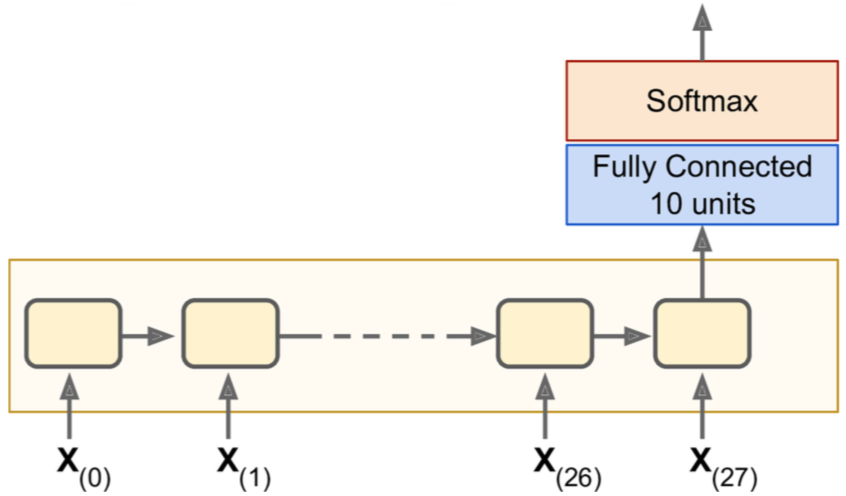 注意:全连接层是连接到最后的states tensor上(也等于最后一个cell的输出)。
注意:全连接层是连接到最后的states tensor上(也等于最后一个cell的输出)。
RNN也可以用来做图像分类,比如对于28x28的图像,只需要把每一行的28个像素点当成一个time step就可以了。
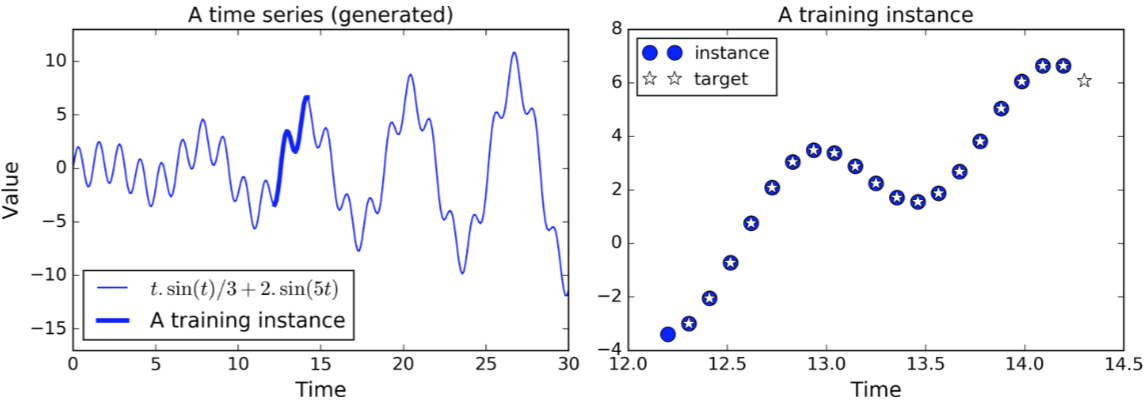
股票预测
RNN擅长对时序性序列做预测,也就是给定一个序列,预测其下一个值是多少。那么训练样本就是随机的从序列上摘出连续的20个值作为输入X(或者以时间滑动窗口的形式摘出一段时间内的值作为X,前一种为element-wised window,后一种为time-wised window),输出Y是往右shift一位后的20个值(和输入重叠了19个值)。
n_steps = 20
n_inputs = 1
n_neurons = 100
n_outputs = 1
# 输入输出都是一个值(输入可以是多个feature组成的输入向量)
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_steps, n_outputs])
# 因为输出是一个值,但是我们的BasicRNNCell的输出是100维的向量,所以需要将输出加一层不带激活函数的全连接层(也就是线性变换)
cell = tf.contrib.rnn.OutputProjectionWrapper(
tf.contrib.rnn.BasicRNNCell(num_units=n_neurons, activation=tf.nn.relu),
# 不带激活函数的全连接层(也就是线性变换)
output_size=n_outputs)
outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
# 使用均方误差作为损失函数
loss = tf.reduce_mean(tf.square(outputs - y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
training_op = optimizer.minimize(loss)
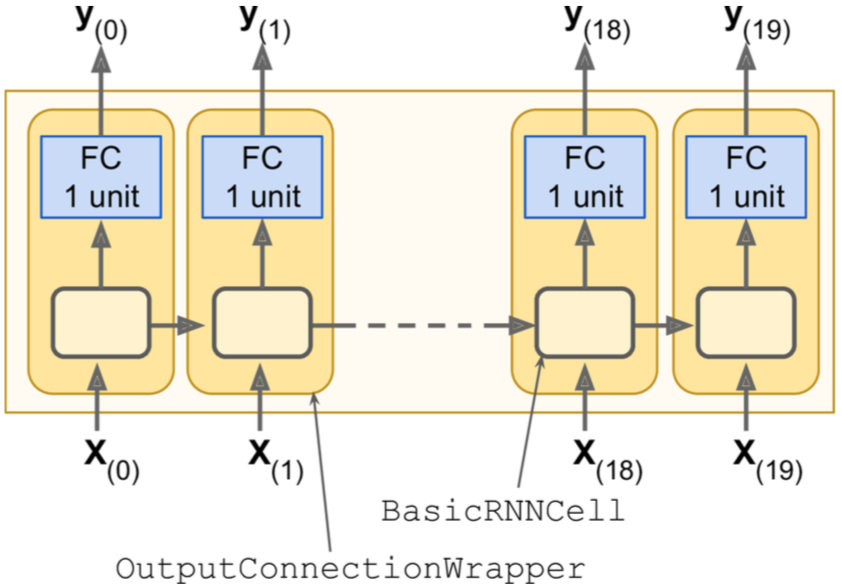 上面的做法虽然简单,但是比较低效,因为每一个输出都要加一层全连接,一共20次全连接。其实仅仅需要两次reshape操作就可以做到只使用一次全连接。
上面的做法虽然简单,但是比较低效,因为每一个输出都要加一层全连接,一共20次全连接。其实仅仅需要两次reshape操作就可以做到只使用一次全连接。
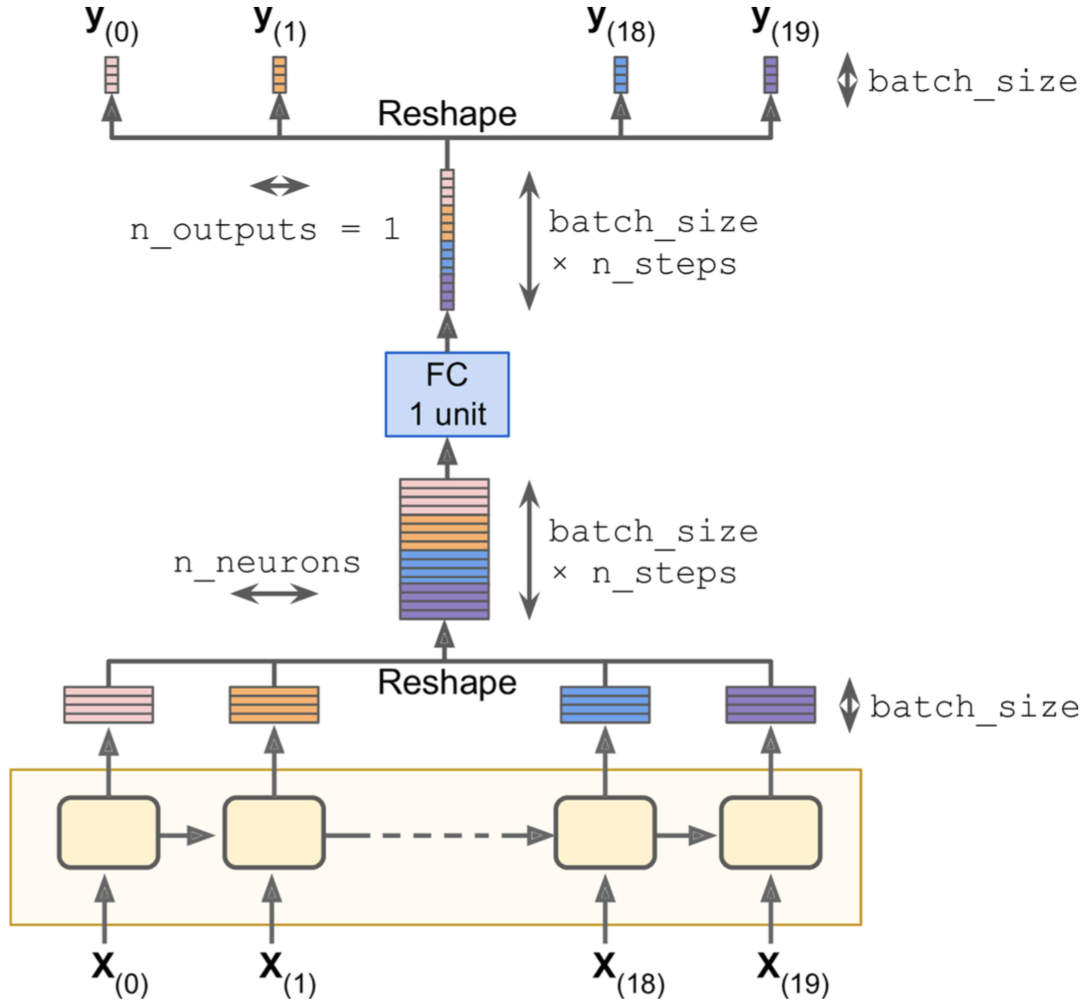
cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons, activation=tf.nn.relu)
rnn_outputs, states = tf.nn.dynamic_rnn(cell, X, dtype=tf.float32)
stacked_rnn_outputs = tf.reshape(rnn_outputs, [-1, n_neurons]) # [batch_size * n_steps, n_neurons]
stacked_outputs = fully_connected(stacked_rnn_outputs, n_outputs, activation_fn=None) # [batch_size * n_steps, n_outputs]
outputs = tf.reshape(stacked_outputs, [-1, n_steps, n_outputs]) # [batch_size, n_steps, n_outputs])
······
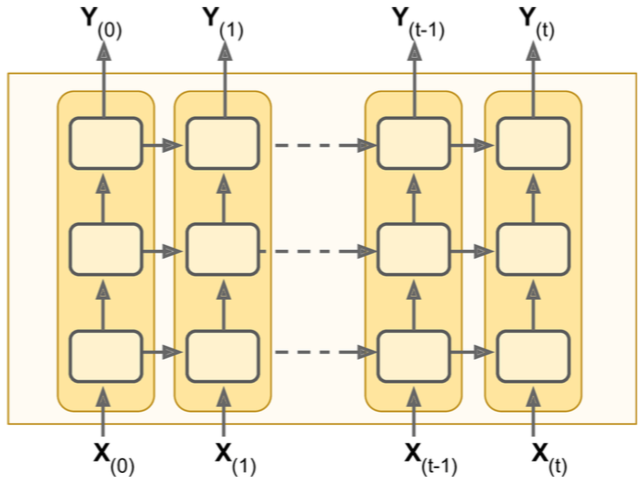
DRNN
DRNN(Deep RNN),深层循环神经网络。
n_neurons = 100
n_layers = 3
basic_cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
# multi_layer_cell = tf.contrib.rnn.MultiRNNCell([basic_cell] * n_layers) # 此方法已废弃
cells = [basic_cell for n in range(n_layers)] # 此方法同样废弃
multi_layer_cell = tf.contrib.rnn.MultiRNNCell(cells)
# 上面的方式使用同样的cell构建DRNN,会重用同一个cell,有时会因为参数重用而产生错误。下面的方式每层生成不同的cell。
def get_lstm(rnn_size):
lstm = tf.contrib.rnn.BasicLSTMCell(rnn_size)
return lstm
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([get_lstm(rnn_size) for _ in range(num_layers)])
outputs, states = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
注意:默认情况下,states返回值是一个tuple,每一个元素是每一层的final State(shape都是[batch_size, n_neu rons])。如果MultiRNNCell(state_is_tuple=False),那么states返回值shape为[batch_size, n_layers * n_neurons]),相当于在列上做了concat。
dropout
RNN可以在每一层的每一个cell内的输入(相当于输入dropout)和输出(相当于神经元dropout)做dropout。
cell_drop = tf.contrib.rnn.DropoutWrapper(basic_cell, input_keep_prob=keep_prob, output_keep_prob=keep_prob)
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([cell_drop] * n_layers) # 此方法已废弃
但是DropoutWrapper不提供is_training placeholder,也就是说在训练和测试的时候都会进行dropout,所以需要做一下改进:
is_training = (sys.argv[-1] == "train")
X = tf.placeholder(tf.float32, [None, n_steps, n_inputs])
y = tf.placeholder(tf.float32, [None, n_steps, n_outputs])
cell = tf.contrib.rnn.BasicRNNCell(num_units=n_neurons)
if is_training:
cell = tf.contrib.rnn.DropoutWrapper(cell, input_keep_prob=keep_prob)
multi_layer_cell = tf.contrib.rnn.MultiRNNCell([cell] * n_layers)
rnn_outputs, states = tf.nn.dynamic_rnn(multi_layer_cell, X, dtype=tf.float32)
[...] # build the rest of the graph
with tf.Session() as sess:
if is_training:
for iteration in range(n_iterations):
[...] # train the model
save_path = saver.save(sess, "/tmp/my_model.ckpt")
else:
saver.restore(sess, "/tmp/my_model.ckpt")
[...] # use the model
长距离依赖
由于将RNN沿着time step展开后,其实就变成了DNN,所以,当输入sequences(time steps)过多时,就相当于展开后的DNN过深,所以也会面临梯度消失和梯度爆炸问题。所有我们先前讨论过的方法都可以用来解决此问题,比如:good parameter initialization, nonsaturating activation functions (e.g., ReLU), Batch Normalization, Gradient Clipping, and faster optimizers.
还有一种粗暴的解决方案就是将输入截断为固定最大长度,也叫做truncated backpropagation through time。但是这样就导致了模型无法学习到长距离依赖,也就是无法提取全局特征,与RNN的初衷相违背。
还有一个严重问题是,对于较长的sequences,先前time step的memory会逐渐消失,并且距离越远越严重(因为state一步步传输的过程中经历了线性变换和激活函数的转换处理)。
为了解决BasicRNNCell带来的这两个严重问题,LSTM和GRU相继问世,后面我们会详细介绍。
LSTM
LSTM(Long Short-Term Memory,长短时记忆网络),它能够探测、保留和提取长距离依赖特征。该网络通过三个门装置:输入门(input gate)、输出门(output gate)、遗忘门(forget gate)能够自己学到long-term state记忆中应该存储什么信息,哪些信息是可以被遗忘的,哪些信息是要保留和传承的(筛选特征记忆)。
lstm_cell = tf.contrib.rnn.BasicLSTMCell(num_units=n_neurons)
内部结构如下图所示:
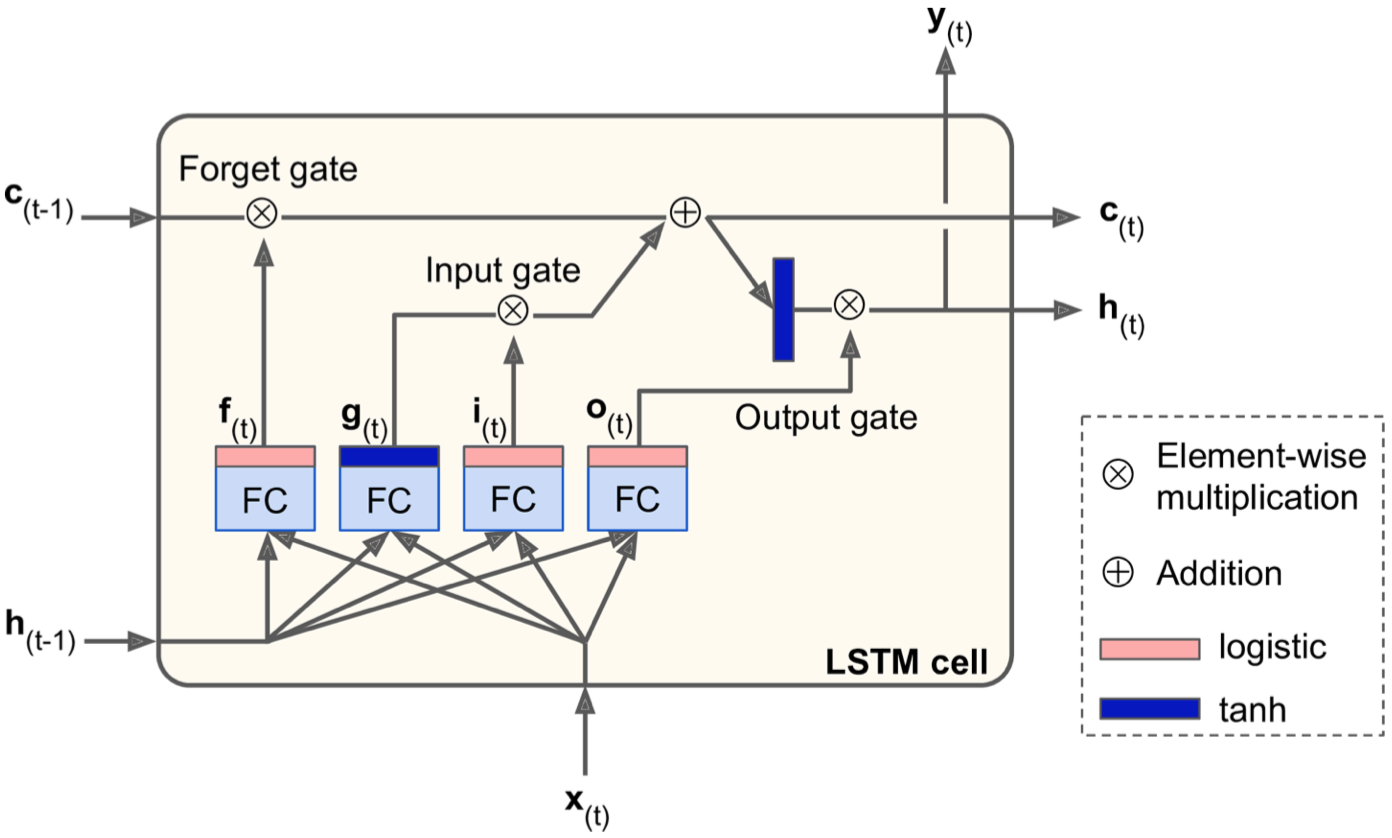
- 每一个LSTM cell管理着两个state(c和h,可以通过state_is_tuple=False参数合并为一个),c管理着long-term state(也就是长期记忆),h管理着short-term state(也就是当前cell的输出状态)。
- 对于g(t)这个装置,就相当于BasicRNNCell的输出;对于f(t),i(t),o(t),因为他们都使用Sigmoid激活函数,输出为0到1,并且结果都输送到element-wise multiplication操作,所以相当于守门人的作用,如果输出0,close the gate,输出1,open it。
- f(t)控制着forget gate,控制着long-term state应该保留和遗忘哪些信息。
- i(t)控制着input gate,控制着g(t)中的哪些信息应该被加入到long-term state。
- o(t)控制着output gate,控制着long-term state的哪些信息应该被读取出来并做输出(这里先做了一次tanh激活,相当于提取输出特征)。
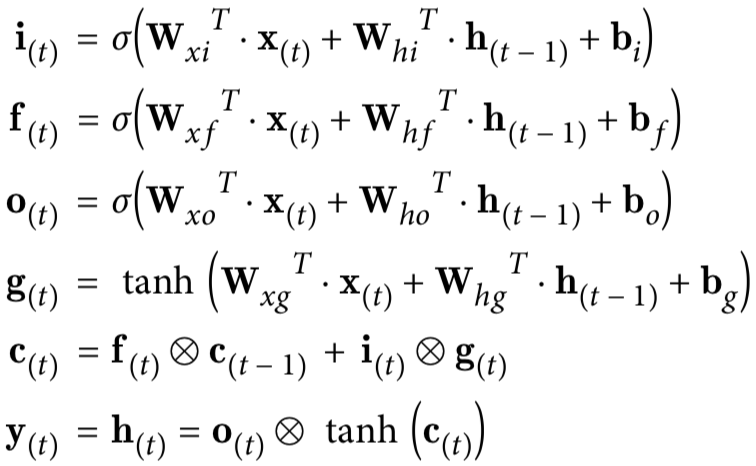 注意:f(t),i(t),o(t),g(t)的产出也应该受到c(t-1)的影响,而不光是h(t-1)和x(t),为达到此目的,可以这样来做:
注意:f(t),i(t),o(t),g(t)的产出也应该受到c(t-1)的影响,而不光是h(t-1)和x(t),为达到此目的,可以这样来做:
lstm_cell = tf.contrib.rnn.LSTMCell(num_units=n_neurons, use_peepholes=True)
GRU
GRU(Gated Recurrent Unit)其实是在LSTM的基础上得来的,是LSTM的简化版本。
gru_cell = tf.contrib.rnn.GRUCell(num_units=n_neurons)
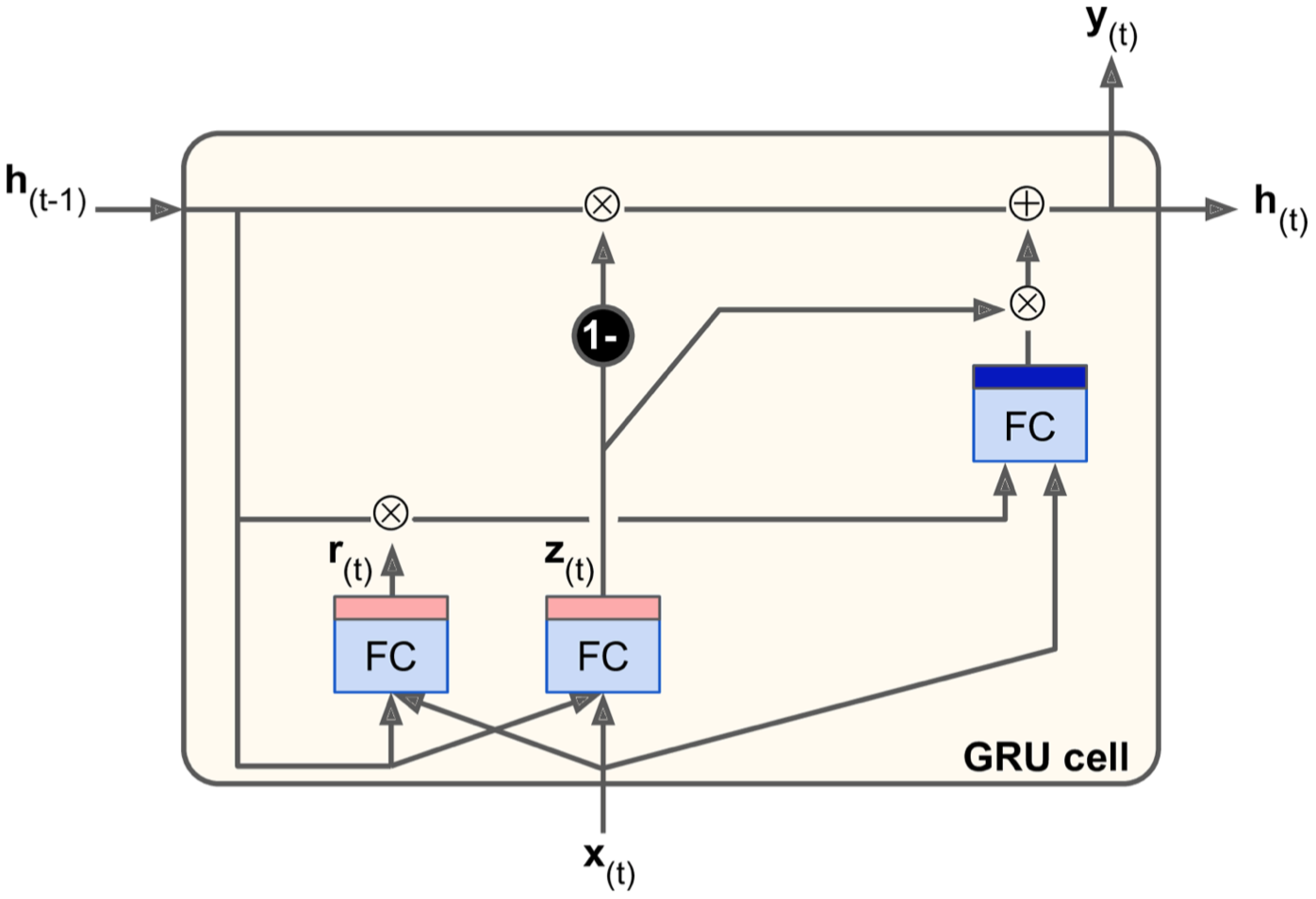
- 两个状态向量(long-term state和short-term state)合并为单个向量h(t)。
- z(t)控制着forget gate和input gate,如果输出为1,那么1-z(t)=0,即关闭forget gate,打开input gate,这时候的第一个门操作控制着state记忆的哪些信息应该被读取出来,然后和x(t)一起送入input gate;反之则反。
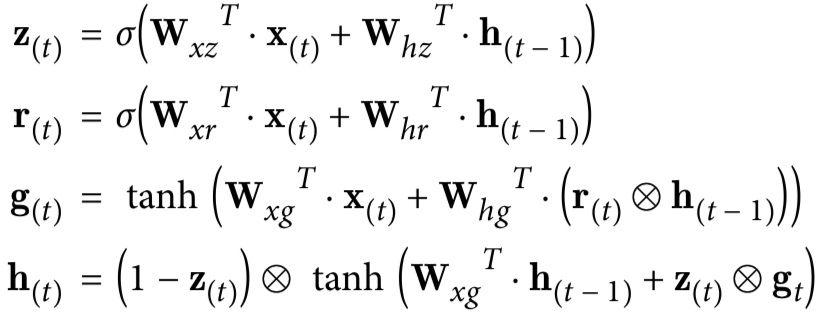
bi-RNN
bi-RNN(bi-directional Recurrent Neural Network,BRNN),双向RNN,指某一个中间状态及输出不仅仅依赖于其之前的所有输入,还依赖于其未来的所有输入上下文。这种结构提供给输出层输入序列中每一个点的完整的过去和未来的上下文信息,这对于NER及机器翻译这种对上下文敏感的业务场景非常有意义。
 常用的bi-RNN包括:bi-LSTM、bi-GRU。
常用的bi-RNN包括:bi-LSTM、bi-GRU。
# 前向的LSTM cell
fw_lstm_cell = tf.contrib.rnn.LSTMCell(int(rnn_size / 2))
# 后向的LSTM cell
bw_lstm_cell = tf.contrib.rnn.LSTMCell(int(rnn_size / 2))
(outputs, (fw_state, bw_state)) = tf.nn.bidirectional_dynamic_rnn(cell_fw=fw_lstm_cell,
cell_bw=bw_lstm_cell,
inputs=encoder_embed_input,
sequence_length=source_sequence_length,
dtype=tf.float32)
# 输出包括前向和后向的两个cell的输出
encoder_output = tf.concat(outputs, -1)
# c(t)和h(t)也分别包括前向和后向的两个cell的状态
encoder_final_state_c = tf.concat([fw_state.c, bw_state.c], -1)
encoder_final_state_h = tf.concat([fw_state.h, bw_state.h], -1)
encoder_state = tf.contrib.rnn.LSTMStateTuple(
c=encoder_final_state_c,
h=encoder_final_state_h
)
Hierarchical RNN
其实我们上节课跟大家讲的HierarchicalCNN模型中的两层CNN(第一层用来提取每个句子中词与词之间的N-gram特征,第二层用来提取每篇文章中句与句之间的N-gram特征),可以直接无缝替换为RNN,这样更加make sense。
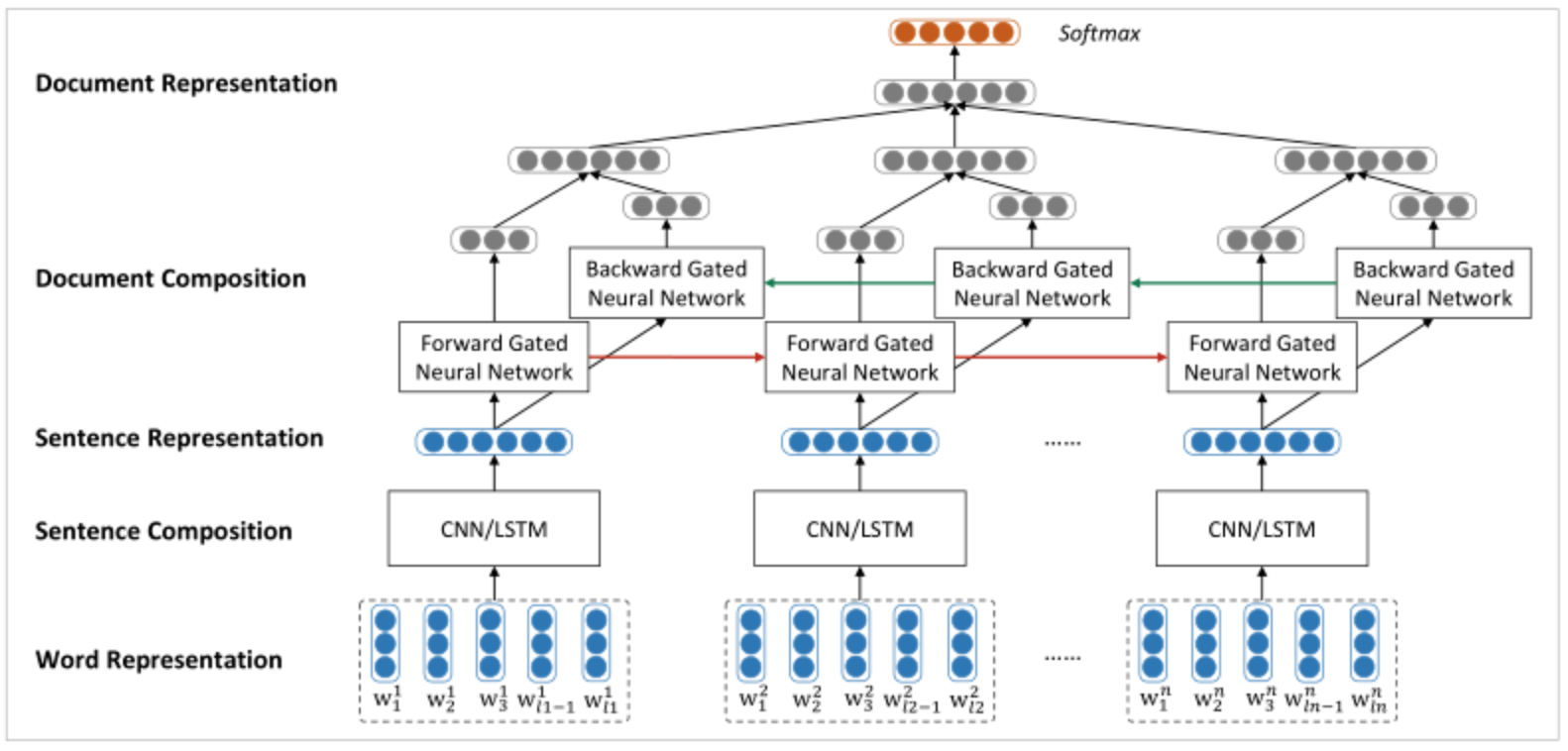 试构建该模型。
试构建该模型。
模型训练
RNN实现文本分类: 代码地址 https://github.com/qianshuang/dl-exp
class TextCNN(object):
"""文本分类,RNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder_with_default(1.0, shape=(), name='keep_prob')
self.seq_length = tf.placeholder(tf.int32, [None, ])
self.rnn()
def rnn(self):
"""rnn模型"""
def lstm_cell(): # lstm核
return tf.contrib.rnn.BasicLSTMCell(self.config.hidden_dim, state_is_tuple=True)
def gru_cell(): # gru核
return tf.contrib.rnn.GRUCell(self.config.hidden_dim)
def dropout(): # 为每一个rnn核后面加一个dropout层
if self.config.rnn == 'lstm':
cell = lstm_cell()
else:
cell = gru_cell()
return tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=self.keep_prob)
# 词向量映射
with tf.device('/cpu:0'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("rnn"):
# 多层rnn网络
cells = [dropout() for _ in range(self.config.num_layers)]
rnn_cell = tf.contrib.rnn.MultiRNNCell(cells, state_is_tuple=True)
_outputs, states = tf.nn.dynamic_rnn(cell=rnn_cell, inputs=embedding_inputs, dtype=tf.float32, sequence_length=self.seq_length)
# last = _outputs[:, -1, :] # 注意:不能取最后一个时序输出作为结果,因为Padding的输出是无意义的,而应该取最终状态
last = tf.concat(states, -1)
print(states)
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc = tf.layers.dense(last, self.config.hidden_dim * self.config.num_layers, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
运行结果:
Configuring model...
Loading training data...
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 5.4, Train Acc: 8.59%, Val Loss: 5.2, Val Acc: 10.40%, Time: 0:00:02 *
Iter: 10, Train Loss: 0.81, Train Acc: 72.66%, Val Loss: 0.92, Val Acc: 71.60%, Time: 0:00:05 *
Iter: 20, Train Loss: 0.61, Train Acc: 85.16%, Val Loss: 0.42, Val Acc: 87.90%, Time: 0:00:08 *
Iter: 30, Train Loss: 0.48, Train Acc: 85.16%, Val Loss: 0.37, Val Acc: 89.80%, Time: 0:00:12 *
Iter: 40, Train Loss: 0.37, Train Acc: 92.97%, Val Loss: 0.32, Val Acc: 91.60%, Time: 0:00:16 *
Iter: 50, Train Loss: 0.18, Train Acc: 94.53%, Val Loss: 0.23, Val Acc: 94.00%, Time: 0:00:18 *
Iter: 60, Train Loss: 0.17, Train Acc: 96.09%, Val Loss: 0.21, Val Acc: 94.10%, Time: 0:00:23 *
Iter: 70, Train Loss: 0.4, Train Acc: 92.50%, Val Loss: 0.18, Val Acc: 95.60%, Time: 0:00:26 *
Epoch: 2
Iter: 80, Train Loss: 0.026, Train Acc: 99.22%, Val Loss: 0.22, Val Acc: 93.90%, Time: 0:00:29
Iter: 90, Train Loss: 0.02, Train Acc: 100.00%, Val Loss: 0.18, Val Acc: 95.20%, Time: 0:00:31
Iter: 100, Train Loss: 0.02, Train Acc: 99.22%, Val Loss: 0.16, Val Acc: 95.80%, Time: 0:00:35 *
......
Epoch: 6
Iter: 360, Train Loss: 0.0017, Train Acc: 100.00%, Val Loss: 0.14, Val Acc: 96.20%, Time: 0:01:57
Iter: 370, Train Loss: 0.0016, Train Acc: 100.00%, Val Loss: 0.14, Val Acc: 96.10%, Time: 0:01:59
Iter: 380, Train Loss: 0.0016, Train Acc: 100.00%, Val Loss: 0.14, Val Acc: 96.10%, Time: 0:02:02
No optimization for a long time, auto-stopping...
Loading test data...
Testing...
Test Loss: 0.14, Test Acc: 96.30%
Precision, Recall and F1-Score...
precision recall f1-score support
财经 0.98 0.97 0.98 115
娱乐 1.00 0.98 0.99 89
时政 0.93 0.96 0.94 94
家居 0.90 0.93 0.92 89
游戏 1.00 0.97 0.99 104
教育 0.97 0.92 0.95 104
时尚 0.95 0.99 0.97 91
科技 0.99 0.99 0.99 94
房产 0.91 0.92 0.91 104
体育 1.00 0.99 1.00 116
avg / total 0.96 0.96 0.96 1000
Confusion Matrix...
[[112 0 1 1 0 0 0 0 1 0]
[ 0 87 1 0 0 0 1 0 0 0]
[ 1 0 90 0 0 0 0 0 3 0]
[ 1 0 0 83 0 1 0 0 4 0]
[ 0 0 0 0 101 1 1 1 0 0]
[ 0 0 1 3 0 96 2 0 2 0]
[ 0 0 0 0 0 1 90 0 0 0]
[ 0 0 0 1 0 0 0 93 0 0]
[ 0 0 3 4 0 0 1 0 96 0]
[ 0 0 1 0 0 0 0 0 0 115]]
社群
- 微信公众号
