算法原理
在之前的课程中我们使用原生的CRF模型做完了NER任务,第一步就是特征工程,需要人工构建特征函数,最终效果也跟所选取的特征函数直接相关。 我们知道神经网络的一个重要作用就是特征学习,那么我们能不能用CNN或RNN来提取特征,然后将特征输入给CRF做最终的NER任务呢?答案是肯定的。
我们首先来看下直接用RNN如何做NER任务。
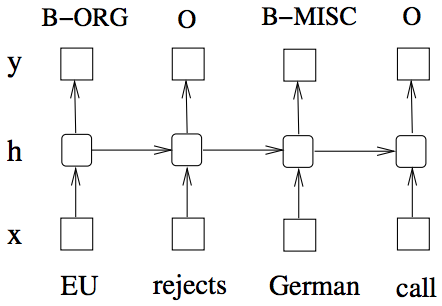
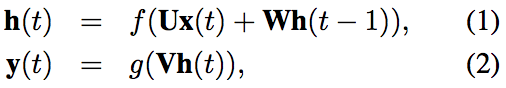
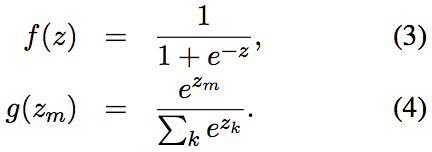 可以看到我们直接对每个cell的输出先做全连接Wrapper(无激活函数,只需拿到score),得到属于每个tag的score,然后计算所有可能的tag序列的score(直接每个tag的score加和),再通过softmax得到每个tag序列的概率,最后通过极大似然估计+随机梯度下降训练模型参数。其实更好的做法是用encoder-decoder。
可以看到我们直接对每个cell的输出先做全连接Wrapper(无激活函数,只需拿到score),得到属于每个tag的score,然后计算所有可能的tag序列的score(直接每个tag的score加和),再通过softmax得到每个tag序列的概率,最后通过极大似然估计+随机梯度下降训练模型参数。其实更好的做法是用encoder-decoder。
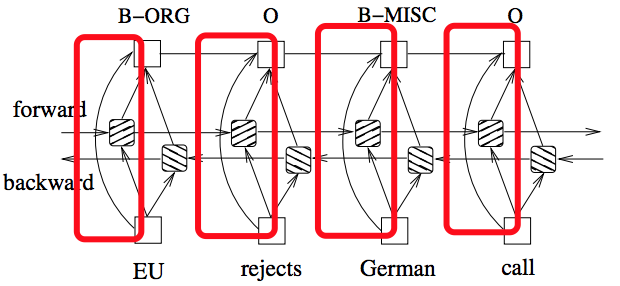
但是我们知道一个特定tag和其周围的tag是有关系的,上面的实现方式并没有利用到其周围tag的信息(虽然用bi-RNN可以利用特定输入的过去和未来的上下文信息,但是那是针对输入X的上下文,并不是tag的上下文)。CRF刚好可以cover住这个问题,那么很自然的想到应该两者结合,所以RNN-CRF模型应运而生。
bi-LSTM-CRF
我们假设状态转移概率矩阵为A(A先要进行初始化,A中的元素即为状态转移概率,随着模型一起训练出来),那么这时每个tag序列的score,就等于bi-LSTM的输出score加上状态转移矩阵作用在该序列上的score,然后通过softmax计算概率。
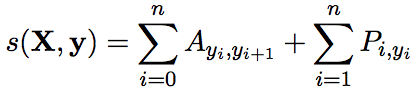
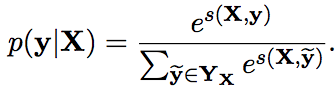 为了特征多样行,我们还可以加入通过特征工程构造的特征一起来得到输出score:
为了特征多样行,我们还可以加入通过特征工程构造的特征一起来得到输出score:
 每个cell的输出做全连接Wrapper时,全连接的输入为concat(bi-LSTM states, 人工feature)。
每个cell的输出做全连接Wrapper时,全连接的输入为concat(bi-LSTM states, 人工feature)。
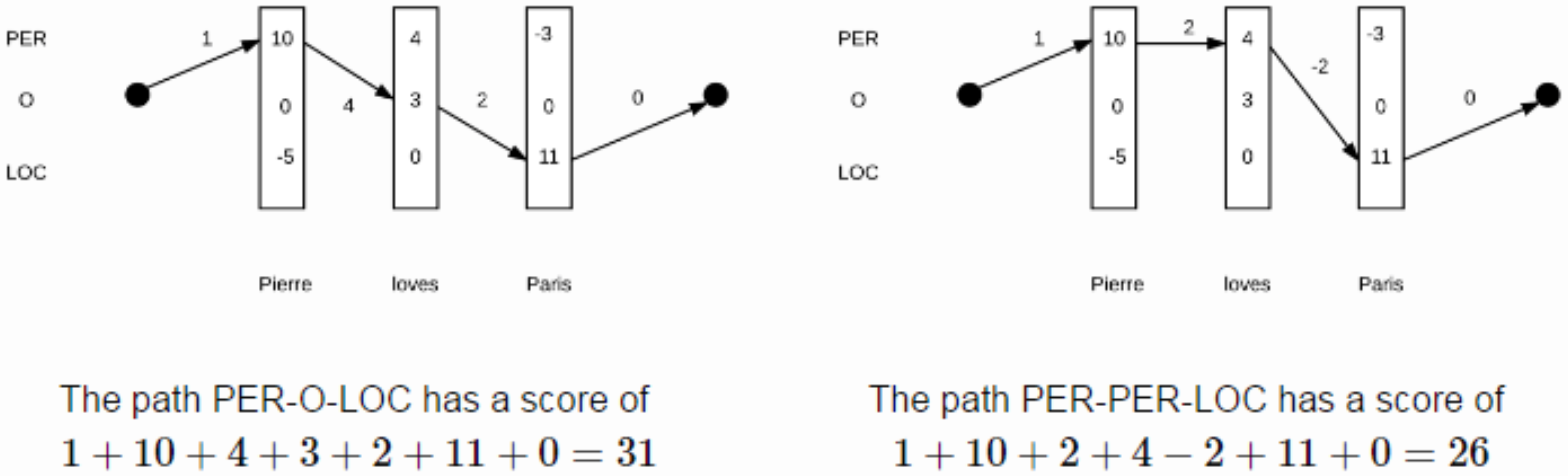
训练完成后,我们除了得到模型外,还得到了副产品转移概率矩阵,在预测时,我们需要用维特比解码得到最优标记序列。
class TextCNN(object):
"""文本分类,CNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_y')
self.keep_prob = tf.placeholder_with_default(1.0, shape=())
self.seq_length = tf.placeholder(tf.int32, [None, ])
self.cnn()
def cnn(self):
"""CNN模型"""
# 词向量映射
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("score"):
GRU_cell_fw = tf.contrib.rnn.GRUCell(300)
GRU_cell_bw = tf.contrib.rnn.GRUCell(300)
GRU_cell_fw = DropoutWrapper(GRU_cell_fw, input_keep_prob=1.0, output_keep_prob=self.keep_prob)
GRU_cell_bw = DropoutWrapper(GRU_cell_bw, input_keep_prob=1.0, output_keep_prob=self.keep_prob)
((fw_outputs, bw_outputs), (_, _)) = tf.nn.bidirectional_dynamic_rnn(cell_fw=GRU_cell_fw,
cell_bw=GRU_cell_bw,
inputs=embedding_inputs,
sequence_length=self.seq_length,
dtype=tf.float32)
outputs = tf.concat((fw_outputs, bw_outputs), 2) # ?, 50, 300 * 2
print(outputs)
h_pool1 = tf.reshape(outputs, [-1, 2 * 300])
W_fc1 = tf.Variable(tf.truncated_normal([2 * 300, 1024], stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1, shape=[1024]))
h_fc1 = tf.nn.relu(tf.matmul(h_pool1, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, self.keep_prob)
# 分类器
self.logits = tf.layers.dense(h_fc1_drop, self.config.num_classes, name='fc2')
# 再reshape回去
logits_in = tf.reshape(self.logits, [-1, self.config.seq_length, self.config.num_classes])
with tf.name_scope("optimize"):
self.log_likelihood, self.transition_params = tf.contrib.crf.crf_log_likelihood(logits_in, self.input_y, self.seq_length)
self.loss = tf.reduce_mean(-self.log_likelihood)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
CNN-CRF
如果我们将bi-LSTM-CRF模型中的bi-LSTM替换为CNN,就是我们的CNN-CRF模型。
class TextCNN(object):
"""文本分类,CNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_y')
self.keep_prob = tf.placeholder_with_default(1.0, shape=())
self.seq_length = tf.placeholder(tf.int32, [None, ])
self.cnn()
def conv_1d(self, x, gram, input_channel, output_channel):
filter_w_1 = tf.Variable(tf.truncated_normal([gram, input_channel, output_channel], stddev=0.1))
filter_b_1 = tf.Variable(tf.constant(0.1, shape=[output_channel]))
conv_1 = tf.nn.conv1d(x, filter_w_1, padding='SAME', stride=1) + filter_b_1
h_conv_1 = tf.nn.relu(conv_1)
# h_pool1_flat2 = tf.reduce_max(h_conv_1, reduction_indices=[1])
return h_conv_1
def network_bcnn(self, embedding_inputs):
flaten_1 = self.conv_1d(embedding_inputs, 1, self.config.embedding_dim, 128) # (-1, 100, 128)
flaten_2 = self.conv_1d(embedding_inputs, 2, self.config.embedding_dim, 128)
flaten_3 = self.conv_1d(embedding_inputs, 3, self.config.embedding_dim, 128)
flaten_4 = self.conv_1d(embedding_inputs, 4, self.config.embedding_dim, 128)
flaten_5 = self.conv_1d(embedding_inputs, 5, self.config.embedding_dim, 128)
h_pool1 = tf.concat([flaten_1, flaten_2, flaten_3, flaten_4, flaten_5], -1) # 列上做concat
return h_pool1
def cnn(self):
"""CNN模型"""
# 词向量映射
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("score"):
## CNN
outputs = self.network_bcnn(embedding_inputs) # [-1, 100, 128 * 5]
h_pool1 = tf.reshape(outputs, [-1, 128 * 5])
W_fc1 = tf.Variable(tf.truncated_normal([128 * 5, 1024], stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1, shape=[1024]))
h_fc1 = tf.nn.relu(tf.matmul(h_pool1, W_fc1) + b_fc1)
h_fc1_drop = tf.nn.dropout(h_fc1, self.keep_prob)
# 分类器
self.logits = tf.layers.dense(h_fc1_drop, self.config.num_classes, name='fc2')
# 再reshape回去
logits_in = tf.reshape(self.logits, [-1, self.config.seq_length, self.config.num_classes])
with tf.name_scope("optimize"):
self.log_likelihood, self.transition_params = tf.contrib.crf.crf_log_likelihood(logits_in, self.input_y, self.seq_length)
self.loss = tf.reduce_mean(-self.log_likelihood)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
模型训练
代码地址 https://github.com/qianshuang/NER
运行结果:
Configuring CNN model...
Loading training and val data...
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 2e+01, Train Acc: 0.00%, Val Loss: 1.7e+01, Val Acc: 11.79%, Time: 0:00:02 *
Epoch: 2
Iter: 10, Train Loss: 1e+01, Train Acc: 0.00%, Val Loss: 1.1e+01, Val Acc: 45.44%, Time: 0:00:15 *
Epoch: 3
Iter: 20, Train Loss: 6.0, Train Acc: 0.00%, Val Loss: 8.0, Val Acc: 63.17%, Time: 0:00:27 *
Epoch: 4
Epoch: 5
Iter: 30, Train Loss: 3.8, Train Acc: 0.00%, Val Loss: 6.0, Val Acc: 74.23%, Time: 0:00:39 *
Epoch: 6
Iter: 40, Train Loss: 2.5, Train Acc: 0.00%, Val Loss: 4.8, Val Acc: 79.00%, Time: 0:00:51 *
Epoch: 7
Epoch: 8
Iter: 50, Train Loss: 2.2, Train Acc: 0.00%, Val Loss: 4.1, Val Acc: 82.40%, Time: 0:01:03 *
Epoch: 9
Iter: 60, Train Loss: 1.5, Train Acc: 0.00%, Val Loss: 3.7, Val Acc: 84.18%, Time: 0:01:18 *
Epoch: 10
Epoch: 11
Iter: 70, Train Loss: 1.3, Train Acc: 0.00%, Val Loss: 3.5, Val Acc: 85.15%, Time: 0:01:30 *
Epoch: 12
Iter: 80, Train Loss: 1.0, Train Acc: 0.00%, Val Loss: 3.5, Val Acc: 86.03%, Time: 0:01:43 *
Epoch: 13
Iter: 90, Train Loss: 1.1, Train Acc: 0.00%, Val Loss: 3.5, Val Acc: 86.27%, Time: 0:01:58 *
社群
- QQ交流群

- 微信交流群

- 微信公众号
