Reusing Pretrained Layers
在前面的章节我们曾经提到过迁移学习,假如现在我们已经训练好了一个人脸识别的深度学习模型,现在又来了一个新的业务让我们训练一个动物识别的模型,这时我们可以重用人脸识别模型所抽取的低级特征,即使用其前面几层隐藏层的权重初始化新模型,因为低级的细粒度特征大家都一样,可以共享(而且也因为使用了其他领域的样本而使得低级特征更加多样化),我们只需要学习高级的特征而不用从头开始学习所有层级的特征,它可以使训练更快并且只需少量的样本即可达到很好的效果。这种方式又叫做Finetune。
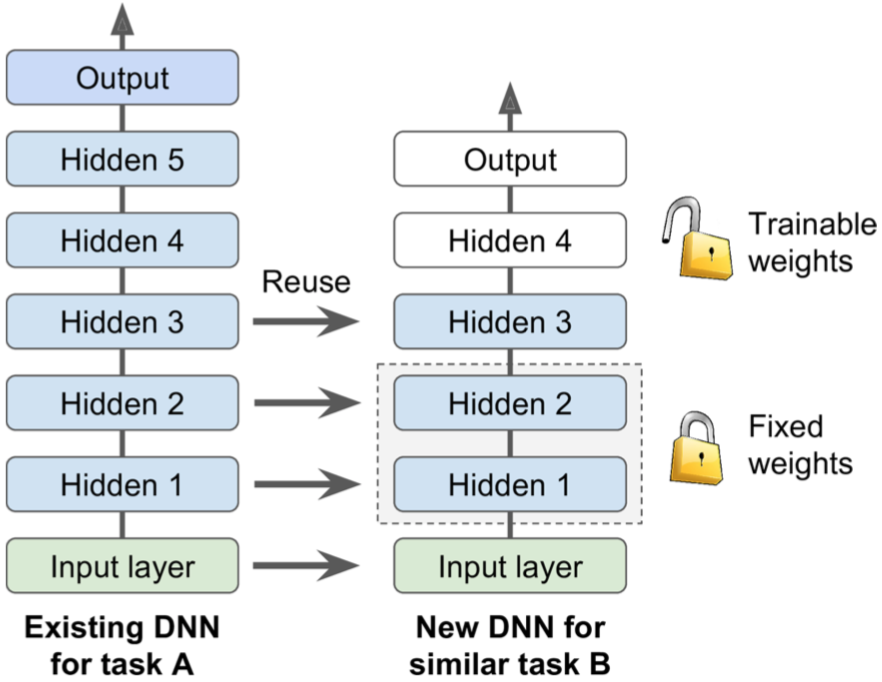 任务越相似,可重用的网络层数就越多。
任务越相似,可重用的网络层数就越多。
[...] # build new model with the same definition as before for hidden layers 1-3
# init = tf.global_variables_initializer()
# 通过scope取出隐藏层所有变量
reuse_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="hidden[123]")
reuse_vars_dict = dict([(var.name, var.name) for var in reuse_vars])
original_saver = tf.Saver(reuse_vars_dict) # saver to restore the selected variables within the original model
with tf.Session() as sess:
# sess.run(init)
original_saver.restore("./my_original_model.ckpt") # restore layers 1 to 3
[...] # train the new model
因为低层级特征是可以共享的,所以我们加载迁移过来的模型后,一般希望freeze住迁移模型的前几层weights和bias,而只训练后面层的参数。
# 让模型只训练后面层的参数
train_vars = tf.get_collection(tf.GraphKeys.TRAINABLE_VARIABLES, scope="hidden[34]|outputs")
training_op = optimizer.minimize(loss, var_list=train_vars)
zero-shot & one-shot & few-shot
我们知道,deep learning是一种data hungry的技术,需要大量的标注样本才能发挥作用,样本量少很容易发生过拟合(参数过多,很容易记住所有样本)。现实世界中,有很多问题是没有这么多的标注数据的,获取标注数据的成本也非常大,例如在医疗领域、安全领域等。
对于我们首节讲到的迁移学习类型,虽然样本量也可以少,但是好歹还有一些样本可以进行finetune,如果样本量继续少,只剩下几个甚至一个,甚至一个都没有的情况下,是否依然可以训练呢?当然答案是肯定的,这个时候的模型训练就叫做few-shot learning(如果只有一个标注样本,称为one-shot,一个样本都没有,叫做zero-shot,也就是将one-shot中的那唯一一个标注样本换成样本的文本描述)。小样本如果有C个类别,每类K个样本,就叫做C-way K-shot。
对于从未见过的新类,只能借助每类少数几个标注样本,这才更接近人类认识新事物的方式,我们教小孩识别苹果,只需要拿出一个或少数几个苹果样本让他学习,而不是拿一大堆苹果放在他面前。
我们把小样本(待迁移、待解决)上的分类问题定义为目标问题,海量样本(被迁移)上的分类问题定义为源问题。
对于C-way one-shot,我们每次在源问题上随机采样C个类别,每个类别随机采样一个样本,再在这C个类别随机抽取一个类别C1,在C1类的样本中随机采样一个不同样本,在源问题上训练match模型,训练完成后,将该match模型原封不动的迁移到目标问题(无需再训练)。
注意,开始训练之前还要将训练样本拆分成sample set和query set。
对于C-way K-shot,因为每次采样K个样本,所以encode后(即f(ϕ)变换),需要按位相加取平均,然后送入match模块。
对于C-way zero-shot,因为每个类别都有类别描述,所以每次采样C个类别和一个类别描述。
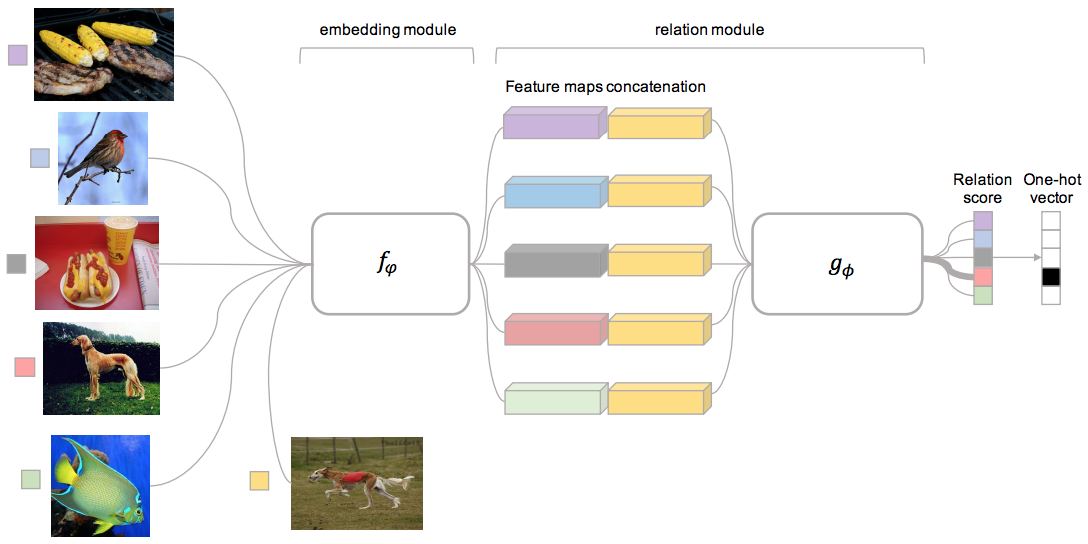 上面是relation network的模型图,论文地址:relation metwork
上面是relation network的模型图,论文地址:relation metwork
 这是matching network的模型图,论文地址:matching metwork
注意:
这是matching network的模型图,论文地址:matching metwork
注意:
- 对encode后的向量进行按位点乘,实际上就是计算距离(想象可以利用softmax与one-hot直接相乘计算接近程度),再用softmax激活后乘以原向量,实际上就是我们的Attention机制。
- 将encoder之后的向量直接concat然后做全连接,比向量直接相减或相乘,能够更好的表达向量之间的relation,因为向量元素之间不一定存在显示的对齐关系,而全连接相当于对向量元素两两进行对比。
据我们目前所知,其实我们有几种相对可行的解决方案:
- 我们知道SVM是对样本Unbalance不敏感的一种分类算法,但是SVM是一种线性分类器(即使通过核函数映射到高维空间,仍然是线性的),而且核函数的目的是进行特征变换,以得到更多高维特征,神经网络的激活函数是去线性化,并用很多神经元以及深层网络从根本上解决线性不可分问题。
- k-NN也可以用来解决此问题,对于one-shot,取k=2,直接计算距离做分类,但是k-NN还是过于简单粗暴,而且对样本Unbalance以及噪声点相对敏感。
multi-task leaning
多任务迁移学习,顾名思义,就是把多个相关(related)的任务放在一起学习,同时学习多个任务。
现在大多数机器学习任务都是单任务学习,即将一个复杂的问题,分解为简单且相互独立的子问题来单独解决,然后再合并结果得到最初复杂问题的结果。这样做看似合理,其实是不正确的,因为现实世界中很多问题不能分解为一个个独立的子问题,即使可以分解,各个子问题之间也是相互关联的,通过一些共享因素或共享表示(share representation)联系在一起。把现实问题当做一个个独立的单任务处理,忽略了问题之间所富含的丰富的关联信息。
举个例子,在人机交互中,用户向机器人发出一个问题query,机器人首先通过该query以及上下文对用户意图进行识别(task1),然后通过NER提取该query中的关键信息(task2)。这看似是两个独立的任务,一个做意图分类(Text Classification),一个做命名实体识别(NER),实际上两个任务之间存在紧密的联系,二者相互促进,如果在一起训练,两个任务的效果都会得到提升。比如当意图分类任务识别出这是一个订机票的意图,那么也就知道了NER任务将要提取出发地、目的地以及出发时间这三个关键slot;反之,当NER任务从用户query中识别出出发地、目的地以及出发时间这三个slot,这些信息对意图分类任务也有帮助(因为大概率知道这是一个订机票或火车票的意图)。这也叫信息窃取。
多个任务之间为什么能相互促进,因为任务与任务之间可以互相为我所用,也就是说我提取的特征可以共享给你,对你有用,但是只有一部分对你有用,另一部分是我这个任务专有的特征,对你来说是噪声。那么怎样把这两部分特征分别提取出来呢?
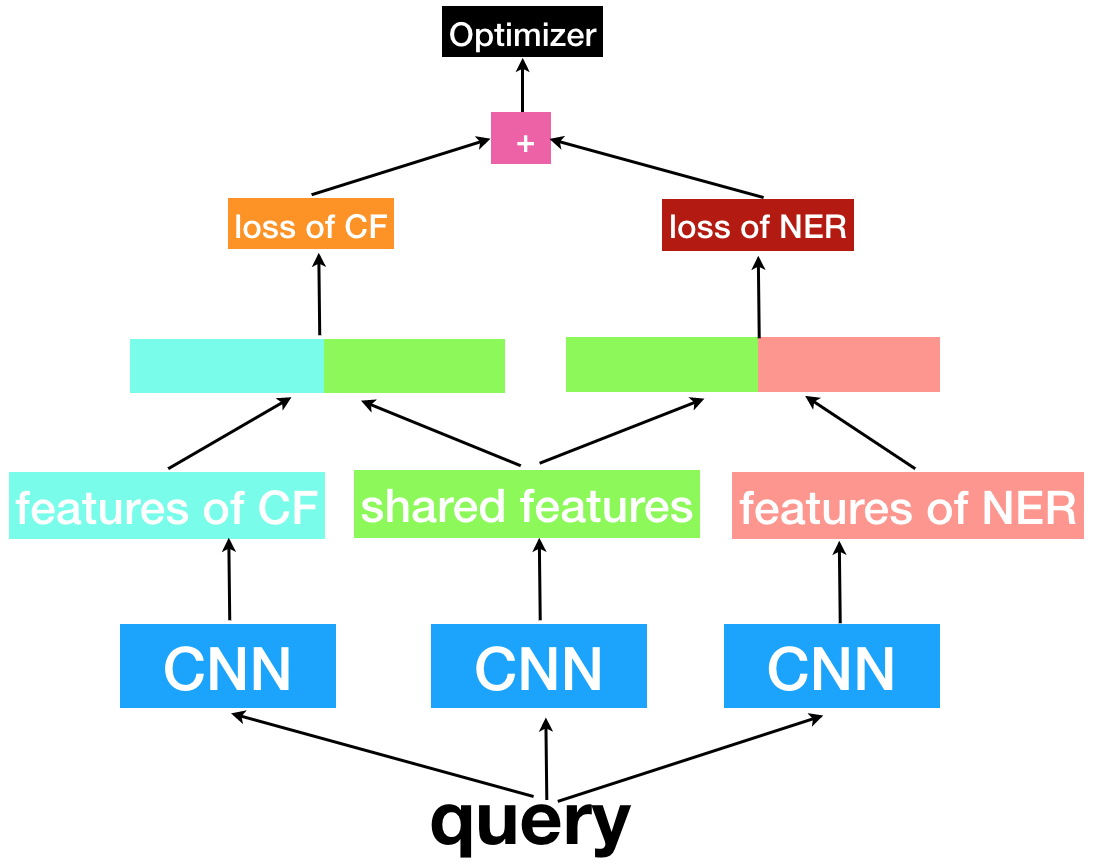 对同一个用户query,使用三个特征提取器,左右两个分别用来提取task-specific feature,中间的用来提取shared-feature,将task-specific feature和shared-feature组合起来(多种方式,一般直接concat),分别作为特定任务的输入特征。这样做之后一般不用做其他的约束,模型自己就可以学到task-specific feature以及shared-feature。
对同一个用户query,使用三个特征提取器,左右两个分别用来提取task-specific feature,中间的用来提取shared-feature,将task-specific feature和shared-feature组合起来(多种方式,一般直接concat),分别作为特定任务的输入特征。这样做之后一般不用做其他的约束,模型自己就可以学到task-specific feature以及shared-feature。
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("score"):
# classification-specific features
rep_fenlei = self.network_bcnn(embedding_inputs) # [-1, 100, 128 * 5]
# shared features
rep_share = self.network_bcnn(embedding_inputs) # [-1, 100, 128 * 5]
# NER-specific features
rep_ner = self.network_bcnn(embedding_inputs) # [-1, 100, 128 * 5]
## 分类任务
feature_cf = tf.concat([rep_fenlei, rep_share], axis=-1) # [-1, 100, 128 * 10]
feature_cf = tf.reduce_max(feature_cf, reduction_indices=[1]) # [-1, 128 * 10]
feature_cf = tf.nn.dropout(feature_cf, self.keep_prob)
feature_cf = self.fc(feature_cf, 128 * 10, 2048)
logits_cf = tf.layers.dense(feature_cf, self.config.num_labels, name='fc1')
self.y_pred_cls = tf.argmax(logits_cf, 1) # 预测类别
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=logits_cf, labels=self.input_label)
loss_cf = tf.reduce_mean(cross_entropy)
## NER任务
feature_ner = tf.concat([rep_share, rep_ner], axis=-1) # [-1, 100, 128 * 10]
feature_ner = tf.reshape(feature_ner, [-1, 128 * 10])
feature_ner = self.fc(feature_ner, 128 * 10, 2048)
feature_ner = tf.nn.dropout(feature_ner, self.keep_prob)
self.logits_in = tf.layers.dense(feature_ner, self.config.num_classes, name='fc2')
logits_ner = tf.reshape(self.logits_in, [-1, self.config.seq_length, self.config.num_classes])
log_likelihood, self.transition_params = tf.contrib.crf.crf_log_likelihood(logits_ner, self.input_y, self.seq_length)
loss_ner = tf.reduce_mean(-log_likelihood)
with tf.name_scope("optimize"):
# 两部分loss的加权求和,一般次要任务的权重降低
self.loss = 0.75 * loss_cf + 0.25 * loss_ner
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
代码地址 https://github.com/qianshuang/NER
multi-language learning
对于多语言迁移学习,一般是两种做法。一种是直接将源语言翻译到目标语言,然后借用目标语言已训练好的模型完成任务,但这种方式严重受限于翻译的误差和延时。另一种是将源语言和目标语言通过映射函数映射到统一空间维度,例如做词向量映射。 对于多语言的文本分类而言,label的数量和种类都是相同的,只是语言不同,也就是说只是文本的表现形式不同,文本代表的含义以及想要表达的意图都是那几种,既然如此,可以肯定不同的语言之间肯定存在某种shared feature,所以可以将多语言放在一起进行训练。
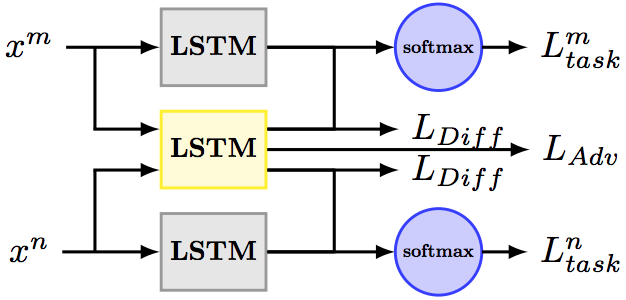
我们当然可以像训练NER & CF multi-task模型一样训练多语言模型,但是如果共享特征空间和语言特定特征空间相互干扰,会对模型的最终效果产生不良影响。我们可以通过对抗训练来保证共享特征空间仅包含多语言的共享信息,而通过正交约束来消除语言特定特征空间中掺杂的共享冗余特征。
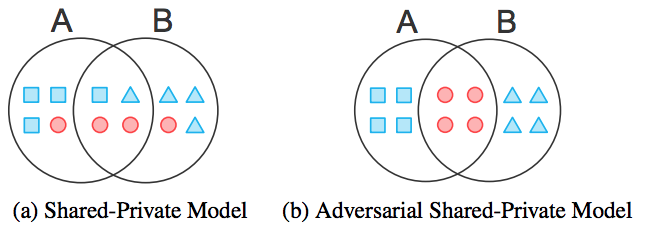 建模过程如下:
建模过程如下:
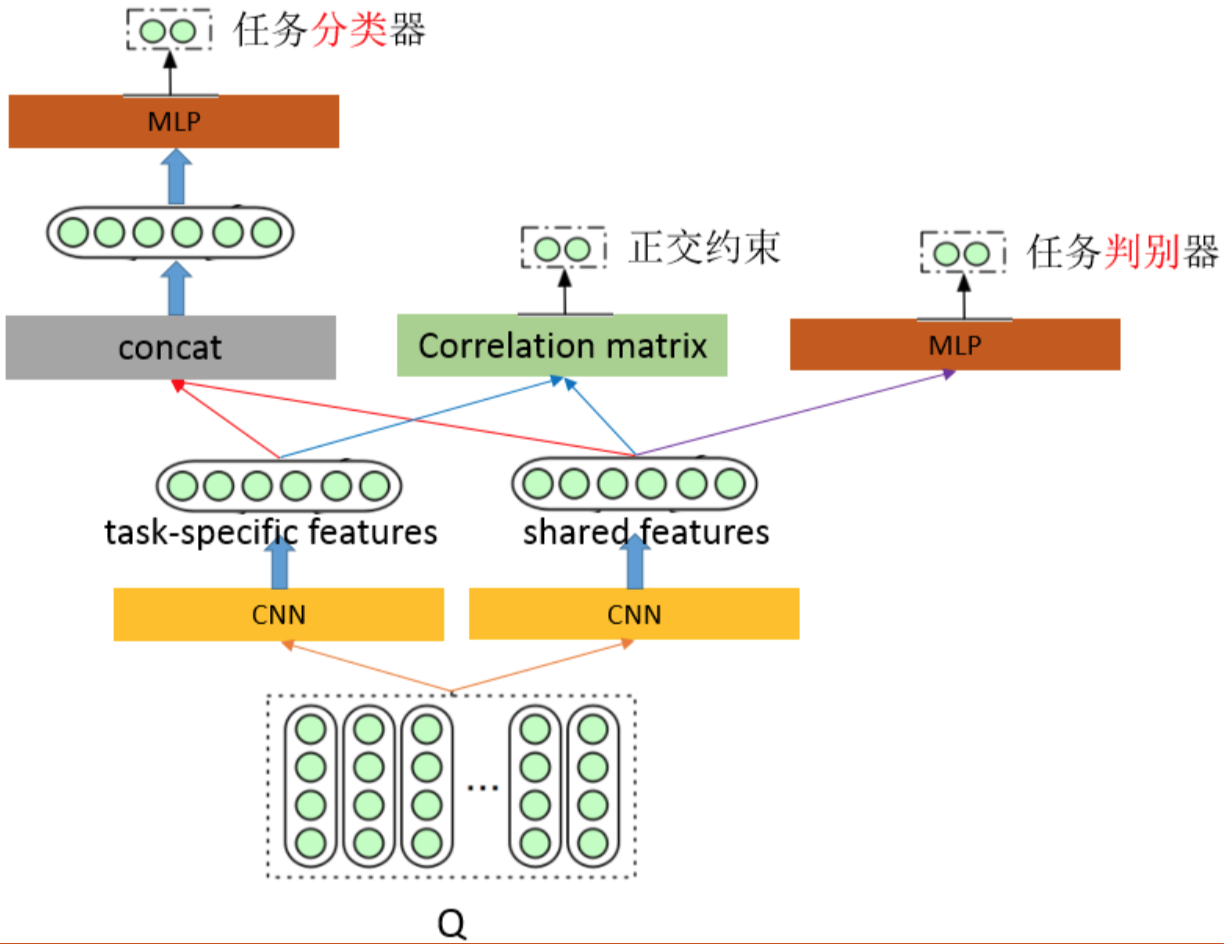
- GAN对抗训练:为了保证共享特征空间仅包含多语言的共享信息,而不会被来自特定语言的信息所污染,可以借鉴GAN的思想,使用一个分类器作为Discriminator,判断共享特征提取器所提取到的特征到底来自于哪种语言,所以这个分类器以language Id作为label,直到判别器最终被完全误导,无法分辨特征来源于哪种语言,那么就证明共享特征提取器所提取到的特征全部为shared feature。
- 正交约束:为了保证各语言私有的特征空间仅包含私有信息,而不会掺杂冗余的共享信息,可以对共享特征和私有特征进行正交约束。
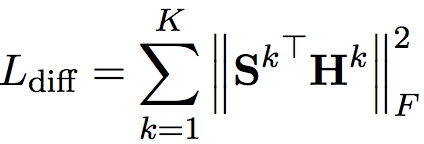
- 模型的最终Loss为:
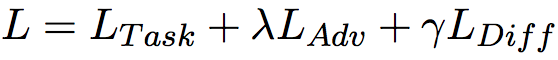 Ltask是主任务的loss,优化它是为了训练我们的主任务;
Ladv是语言判别器的loss,优化它是为了使shared feature尽量纯粹;
Ldiff是正交约束的loss,优化它是为了使lang-specific feature尽量纯粹。
Ltask是主任务的loss,优化它是为了训练我们的主任务;
Ladv是语言判别器的loss,优化它是为了使shared feature尽量纯粹;
Ldiff是正交约束的loss,优化它是为了使lang-specific feature尽量纯粹。
# 词向量映射
embedding_Q = tf.get_variable('embedding_Q', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs_Q = tf.nn.embedding_lookup(embedding_Q, self.input_Q)
# input dropout
embedding_inputs_Q = tf.nn.dropout(embedding_inputs_Q, self.keep_prob)
# BCNN
rep_Q_src = self.network_bcnn(embedding_inputs_Q) # [-1, 128 * 5]
fc_out_src = self.fc(rep_Q_src, 128 * 5, 100) # [-1, 100]
rep_Q_share = self.network_bcnn(embedding_inputs_Q) # [-1, 128 * 5]
fc_out_share = self.fc(rep_Q_share, 128 * 5, 100)
feature = tf.concat([fc_out_src, fc_out_share], axis=1)
feature = tf.nn.dropout(feature, self.keep_prob)
# 分类器
W_fc2 = tf.Variable(tf.truncated_normal([200, self.config.num_classes], stddev=0.1))
b_fc2 = tf.Variable(tf.constant(0.1, shape=[self.config.num_classes]))
y_conv = tf.matmul(feature, W_fc2) + b_fc2
self.y_pred_cls = tf.argmax(y_conv, 1) # 预测类别
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=y_conv, labels=self.input_label)
loss_src = tf.reduce_mean(cross_entropy)
# adversary loss
loss_adv = self.adversarial_loss(fc_out_share, self.input_task)
loss_diff = self.diff_loss(fc_out_share, fc_out_src)
self.loss = loss_src + 0.05 * loss_adv + loss_diff
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
# 准确率
self.correct_pred = tf.equal(tf.argmax(self.input_label, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(self.correct_pred, tf.float32))
代码地址 https://github.com/qianshuang/dl-exp
社群
- QQ交流群

- 微信交流群

- 微信公众号
