算法原理
前面我们说到,机器翻译是delayed seq to seq,又叫Encoder–Decoder。Encoder模块将原始输入sequence压缩成一个“有意义”的向量表示,Decoder模块将该向量解码为目标输出sequence。

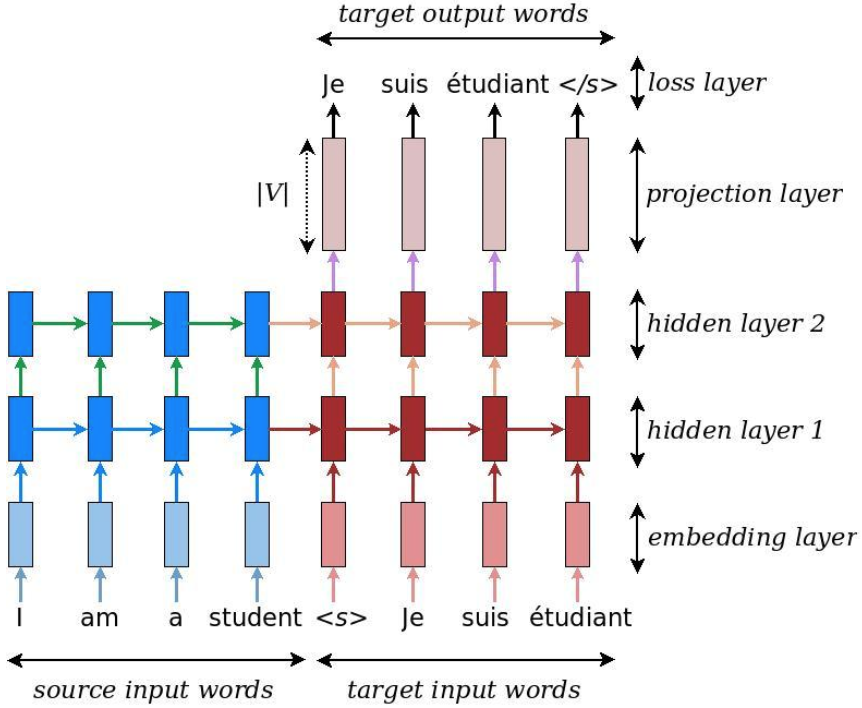 下面以一个实际例子来给大家详细介绍Encoder–Decoder模型的基本原理。该示例的目的是输入一个字符序列,输出这个字符序列的字典正序列,比如:输入“bsaqq”,输出“abqqs”。
下面以一个实际例子来给大家详细介绍Encoder–Decoder模型的基本原理。该示例的目的是输入一个字符序列,输出这个字符序列的字典正序列,比如:输入“bsaqq”,输出“abqqs”。
首先我们来看下encoder模块,是一个普通的多层RNN。
# 1. encoder
encoder_cell = get_multi_rnn_cell(self.config.rnn_size, self.config.num_layers)
source_embedding = tf.get_variable('source_embedding', [self.config.source_vocab_size, self.config.encoding_embedding_size])
source_embedding_inputs = tf.nn.embedding_lookup(source_embedding, self.source)
encoder_output, encoder_state = tf.nn.dynamic_rnn(
encoder_cell,
source_embedding_inputs,
sequence_length=self.source_sequence_length,
dtype=tf.float32)
然后是decoder模块,decoder本质上也是一个RNN,它使用encoder模块的输出状态来初始化states,并在每个cell的输出添加full connected wrapper,以得到每个目标翻译的概率(score)。
# cut掉最后的字符
ending = tf.strided_slice(self.target, [0, 0], [self.config.batch_size, -1], [1, 1])
# 最前面加上<GO>字符
decoder_input = tf.concat([tf.fill([tf.shape(self.target)[0], 1], self.config.target_letter_to_id['<GO>']), ending], 1)
target_embedding = tf.get_variable('target_embedding', [self.config.target_vocab_size, self.config.decoding_embedding_size])
target_embedding_inputs = tf.nn.embedding_lookup(target_embedding, decoder_input)
# decoder_cell可以使用encoder_cell代替,即共享权重,但是不共享权重可以得到更佳的性能
decoder_cell = get_multi_rnn_cell(self.config.rnn_size, self.config.num_layers)
output_layer = Dense(self.config.target_vocab_size, kernel_initializer=tf.truncated_normal_initializer(mean=0.0, stddev=0.1))
# 训练阶段
# def train():
# with tf.variable_scope("decode"):
training_helper = tf.contrib.seq2seq.TrainingHelper(inputs=target_embedding_inputs, sequence_length=self.target_sequence_length)
training_decoder = tf.contrib.seq2seq.BasicDecoder(
decoder_cell,
training_helper,
encoder_state, # # 使用encoder模块的输出状态来初始化states
# 在输出添加full connected wrapper,映射得到每个target_vocab的score
output_layer)
training_decoder_output, _, __ = tf.contrib.seq2seq.dynamic_decode(
training_decoder,
impute_finished=True, # 遇到EOS自动停止解码(EOS之后的所有time step的输出为0,输出状态为最后一个有效time step的输出状态)
maximum_iterations=None) # 设置最大decoding time steps数量,默认decode until the decoder is fully done,因为训练时会将target序列传入,所以可以为None
self.logits = training_decoder_output.rnn_output
# 测试阶段
# def predict():
# with tf.variable_scope("decode", reuse=True):
predicting_helper = tf.contrib.seq2seq.GreedyEmbeddingHelper(
target_embedding,
tf.fill([tf.shape(self.source)[0]], self.config.target_letter_to_id['<GO>']),
self.config.target_letter_to_id['<EOS>'])
predicting_decoder = tf.contrib.seq2seq.BasicDecoder(
decoder_cell,
predicting_helper,
encoder_state,
output_layer)
predicting_decoder_output, _, __ = tf.contrib.seq2seq.dynamic_decode(
predicting_decoder,
impute_finished=True, # 遇到EOS自动停止解码输出(停止输出,输出状态为最后一个有效time step的输出状态)
maximum_iterations=tf.round(tf.reduce_max(self.source_sequence_length) * 2)) # 预测时不知道什么时候输出EOS,所以要设置最大time step数量
self.result_ids = predicting_decoder_output.sample_id # 输出target vocab id
最后是模型训练(计算梯度、优化损失函数)阶段。
# 3. optimize
masks = tf.sequence_mask(self.target_sequence_length, tf.reduce_max(self.target_sequence_length), dtype=tf.float32)
# logits:[batch_size, 10, 30], targets:[batch_size, 10], masks:[batch_size, 10]
# 让mask的内容不计算损失,如果不做mask,即使impute_finished=True使得EOS之后的输出为0,但是targets的PAD会被误认为是一个正常的翻译结果而计算了损失
self.loss = tf.contrib.seq2seq.sequence_loss(self.logits, self.target, masks)
optimizer = tf.train.AdamOptimizer(self.config.learning_rate)
# 梯度裁剪
gradients = optimizer.compute_gradients(self.loss)
capped_gradients = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gradients if grad is not None]
self.train_op = optimizer.apply_gradients(capped_gradients)
可以将encoder模块的MultiRNNCell替换成Bidirectional-RNNCell能得到更好的效果(decoder模块不能做替换,原因显而易见,不存在反向)。
# bi-LSTM
fw_lstm_cell = tf.contrib.rnn.LSTMCell(int(self.config.rnn_size / 2), initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
bw_lstm_cell = tf.contrib.rnn.LSTMCell(int(self.config.rnn_size / 2), initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
(outputs, (fw_state, bw_state)) = tf.nn.bidirectional_dynamic_rnn(cell_fw=fw_lstm_cell,
cell_bw=bw_lstm_cell,
inputs=source_embedding_inputs,
sequence_length=self.source_sequence_length,
dtype=tf.float32)
encoder_output = tf.concat(outputs, -1)
encoder_final_state_c = tf.concat([fw_state.c, bw_state.c], -1)
encoder_final_state_h = tf.concat([fw_state.h, bw_state.h], -1)
encoder_state = tf.contrib.rnn.LSTMStateTuple(
c=encoder_final_state_c,
h=encoder_final_state_h
)
def get_multi_rnn_cell(rnn_size, num_layers):
# def lstm_cell():
# return tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
# return tf.contrib.rnn.MultiRNNCell([lstm_cell() for _ in range(num_layers)])
return tf.contrib.rnn.LSTMCell(rnn_size, initializer=tf.random_uniform_initializer(-0.1, 0.1, seed=2))
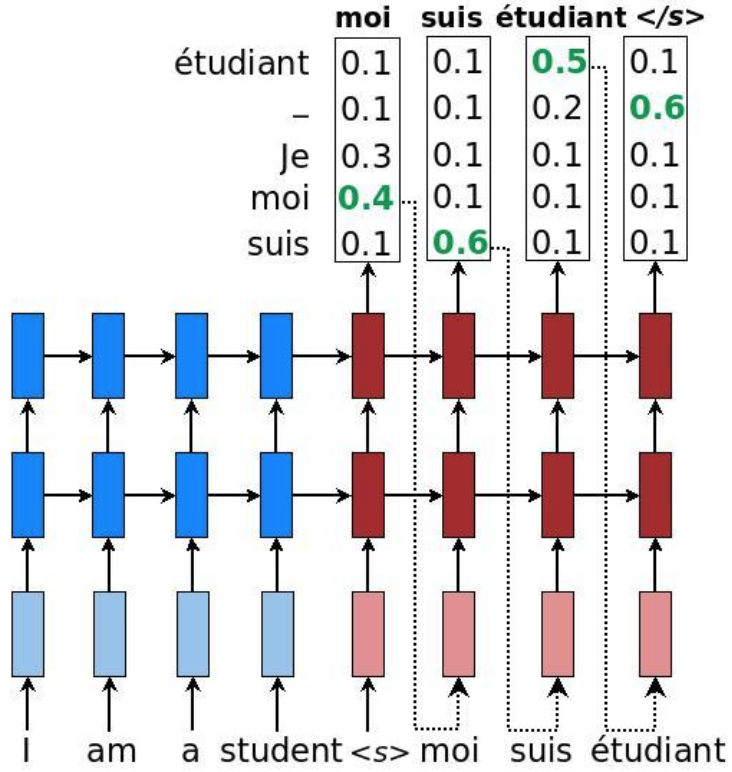
注意在训练和预测阶段有不同的形式,因为在预测阶段我们只有source sentence。在预测阶段我们有三种不同的decoding方式,greedy、sampling、beam-search,我们上面代码使用的是greedy策略,即每个time step选择得分最高的输出单词,并作为下一个time step的输入。
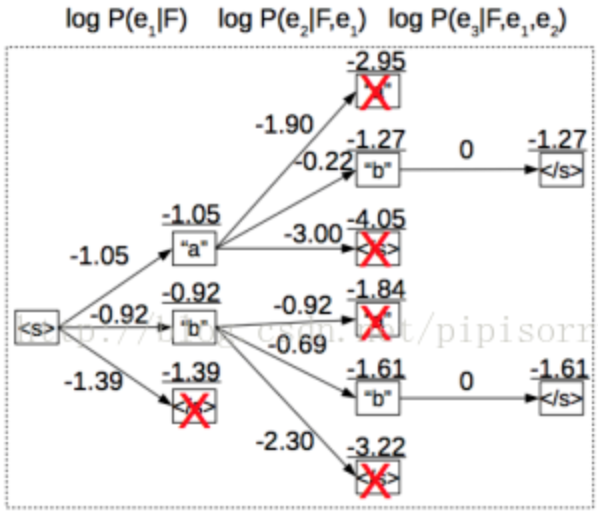
 beam search也能显著提升效果,它通过在decoding过程的每一time step保留top候选集,来探索更多可能的搜索空间,每一步保留的候选集的大小叫beam width(注意每一个time step的score计算是计算条件概率,即乘上前面所有time step的score,也有人说是加上前面所有的score,都是make sense的)。
beam search也能显著提升效果,它通过在decoding过程的每一time step保留top候选集,来探索更多可能的搜索空间,每一步保留的候选集的大小叫beam width(注意每一个time step的score计算是计算条件概率,即乘上前面所有time step的score,也有人说是加上前面所有的score,都是make sense的)。
# 测试阶段
with tf.variable_scope("decode", reuse=True):
# a. decoder_attention
bs_encoder_output = tf.contrib.seq2seq.tile_batch(encoder_output, multiplier=self.config.beam_width) # tile_batch等价于复制10份,然后concat(..., 0)
bs_sequence_length = tf.contrib.seq2seq.tile_batch(self.source_sequence_length, multiplier=self.config.beam_width)
bs_attention_mechanism = tf.contrib.seq2seq.LuongAttention(self.config.rnn_size, bs_encoder_output, memory_sequence_length=bs_sequence_length)
bs_attention_decoder_cell = tf.contrib.seq2seq.AttentionWrapper(decoder_cell, bs_attention_mechanism, attention_layer_size=self.config.rnn_size)
# b. decoder_initial_state
bs_cell_state = tf.contrib.seq2seq.tile_batch(encoder_state, multiplier=self.config.beam_width)
bs_initial_state = bs_attention_decoder_cell.zero_state(tf.shape(self.source)[0] * self.config.beam_width, tf.float32).clone(cell_state=bs_cell_state)
predicting_decoder = tf.contrib.seq2seq.BeamSearchDecoder(
cell=bs_attention_decoder_cell,
embedding=target_embedding,
start_tokens=tf.fill([tf.shape(self.source)[0]], self.config.target_letter_to_id['<GO>']),
end_token=self.config.target_letter_to_id['<EOS>'],
initial_state=bs_initial_state,
beam_width=self.config.beam_width,
output_layer=output_layer,
length_penalty_weight=0.0) # 对长度较短的生成结果施加惩罚,0.0表示不惩罚
predicting_decoder_output, _, __ = tf.contrib.seq2seq.dynamic_decode(
predicting_decoder,
impute_finished=False, # 遇到EOS自动停止解码输出(停止输出,输出状态为最后一个有效time step的输出状态)
maximum_iterations=tf.round(tf.reduce_max(self.source_sequence_length) * 2)) # 预测时不知道什么时候输出EOS,所以要设置最大time step数量
self.result_ids = tf.transpose(predicting_decoder_output.predicted_ids, perm=[0, 2, 1]) # 输出target vocab id:[batch_size, beam_width, max_time_step]
模型训练
代码地址 https://github.com/qianshuang/seq2seq
运行结果:
Configuring model...
Loading data...
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 3.4, Val Loss: 3.4, Time: 0:00:02 *
Epoch: 2
Iter: 10, Train Loss: 3.4, Val Loss: 3.4, Time: 0:00:04 *
Epoch: 3
Iter: 20, Train Loss: 3.3, Val Loss: 3.3, Time: 0:00:07 *
Epoch: 4
Iter: 30, Train Loss: 3.1, Val Loss: 3.1, Time: 0:00:10 *
Epoch: 5
Epoch: 6
Iter: 40, Train Loss: 3.0, Val Loss: 3.0, Time: 0:00:12 *
Epoch: 7
Iter: 50, Train Loss: 3.0, Val Loss: 3.0, Time: 0:00:15 *
Epoch: 8
Iter: 60, Train Loss: 2.8, Val Loss: 2.9, Time: 0:00:17 *
......
......
Epoch: 314
Iter: 2510, Train Loss: 0.091, Val Loss: 0.4, Time: 0:07:56
Epoch: 315
Epoch: 316
Iter: 2520, Train Loss: 0.078, Val Loss: 0.4, Time: 0:07:56
No optimization for a long time, auto-stopping...
Testing...
原始输入: common
输出: cmmmoo<EOS>
社群
- QQ交流群

- 微信交流群

- 微信公众号
