算法原理
Attention机制的核心原理是,通过在输出target时,paying “attention” to relevant source content,在目标和源之间建立直接的快捷连接。因为source和target之间有一种隐式的对其关系(通过Attention刻画),我们可以在训练完成后将这种对其关系以矩阵的形式可视化出来:
 为什么Attention机制能够显著提升seq2seq的效果?原因有以下几点:
为什么Attention机制能够显著提升seq2seq的效果?原因有以下几点:
- Attention学习对其关系,实际上是学习一种统计规律,即当某几个字经常一起出现时,应该输出什么东西,哪个字对输出的作用最大。或者说decoder端生成位置i的词时,有多少程度受encoder端的位置j的词影响。试图让网络学出来对不同的输入区域加以不同关注度。
- 在上一节的seq2seq模型中,当decoding时,我们只传递了最后一个输入time step的state来作为decoder模块的初始state,但是对于长句子,单靠这一个最终状态可能会造成信息损失。
- Attention机制使用所有的输入time step状态,并把他们当做一个输入信息储存器,通过Attention计算权重来动态提取。
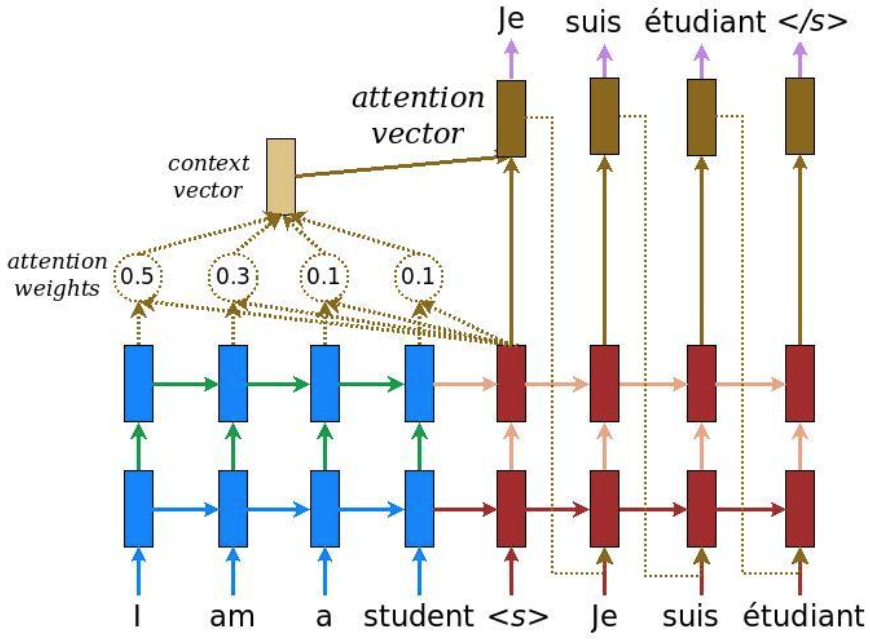
Attention机制的原理如下:
- decoding时,通过将current target hidden state与所有的source states进行比较,计算Attention weights。
- 根据Attention weights计算出一个context vector(source states的加权平均)。
- 将context vector和current target hidden state联合起来(直接concat)产生最终的attention vector。
- 将attention vector作为下一个time step的输入。
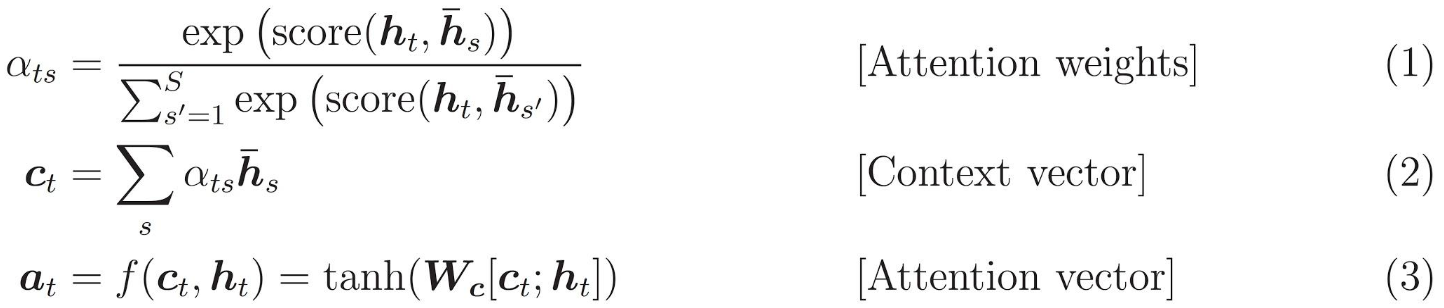 score function通常有以下几两种形式:
score function通常有以下几两种形式:
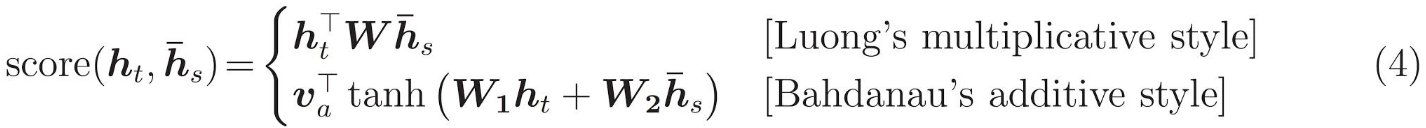
- 点乘(矩阵乘法),其实就是计算向量之间的cosine相似度,类似于matching network的做法。
- 基于全连接神经网络,类似于compare network的做法。
# attention
attention_mechanism = tf.contrib.seq2seq.LuongAttention(self.config.rnn_size, encoder_output, memory_sequence_length=self.source_sequence_length)
attention_decoder_cell = tf.contrib.seq2seq.AttentionWrapper(decoder_cell, attention_mechanism, attention_layer_size=self.config.rnn_size)
# initial_state
initial_state = attention_decoder_cell.zero_state(tf.shape(self.source)[0], tf.float32).clone(cell_state=encoder_state)
Attention类型
Global Attention与Local Attention
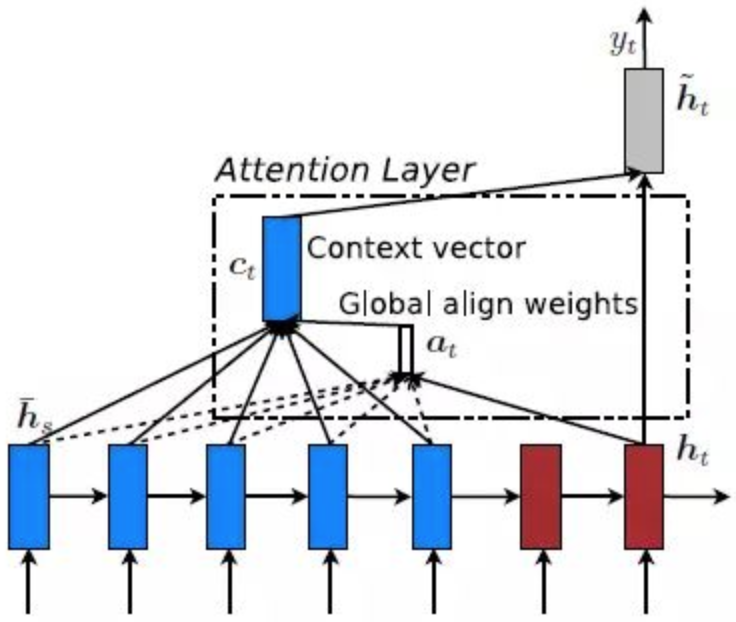 上面所讲到的方式就是Global Attention,即每一time step,encoder端的所有hidden state都要参与计算Attention weights,这样做计算开销会比较大,效率偏低,特别是当encoder的句子偏长,比如一段话或者一篇文章。基于此,Local Attention应运而生。
上面所讲到的方式就是Global Attention,即每一time step,encoder端的所有hidden state都要参与计算Attention weights,这样做计算开销会比较大,效率偏低,特别是当encoder的句子偏长,比如一段话或者一篇文章。基于此,Local Attention应运而生。
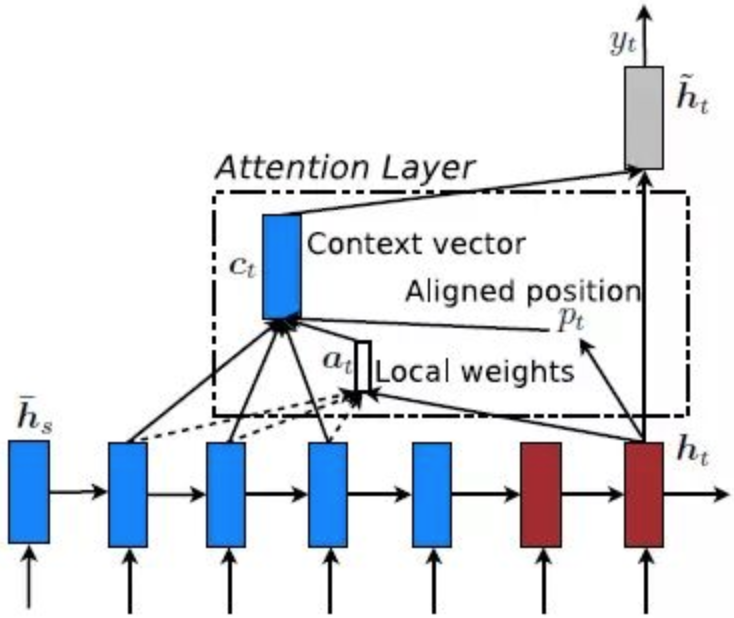 Local Attention首先会为decoder端当前的词,预测一个source端对齐位置(aligned position)Pt,然后基于Pt选择一个窗口,用于计算Context向量Ct。Pt的计算公式如下:
Local Attention首先会为decoder端当前的词,预测一个source端对齐位置(aligned position)Pt,然后基于Pt选择一个窗口,用于计算Context向量Ct。Pt的计算公式如下:
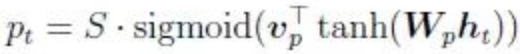 其中,S是encoder端句子长度,Vp和Wp是模型参数。
Global Attention和Local Attention各有优劣,在实际应用中,Global Attention应用更普遍,因为local Attention需要预测一个位置向量Pt,这就带来两个问题:1、当encoder句子不是很长时,相对Global Attention,计算量并没有明显减小;2、位置向量Pt的预测并不非常准确,这就直接影响到local Attention的准确率。
其中,S是encoder端句子长度,Vp和Wp是模型参数。
Global Attention和Local Attention各有优劣,在实际应用中,Global Attention应用更普遍,因为local Attention需要预测一个位置向量Pt,这就带来两个问题:1、当encoder句子不是很长时,相对Global Attention,计算量并没有明显减小;2、位置向量Pt的预测并不非常准确,这就直接影响到local Attention的准确率。
Self Attention
传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端的每个词与目标端每个词之间的对其关系。Self Attention是计算自身与自身相关的Self Attention,即捕捉自身的词与词之间的对其关系。并能更有效的捕捉句子内部的长距离依赖关系。
single-head Self Attention
single-head Self Attention比较简单直观,与传统的Attention机制计算方式相同,只不过Ht和Hs都变成了自身。
u_context = tf.Variable(tf.truncated_normal([self.config.hidden_size * 2]), name='u_context') #(100)
# 这里最好是W1Ht + W2Hs
h = tf.contrib.layers.fully_connected(inputs, self.config.hidden_size * 2, activation_fn=tf.nn.tanh) #(?, 20, 100)
alpha = tf.nn.softmax(tf.reduce_sum(tf.multiply(h, u_context), axis=2, keep_dims=True), dim=1) #(?, 20, 1)
atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1) #(?, 100)
# atten_output即为context vector,再与Hs做concat(或者concat之后再进行一次非线性变换)作为最终的Attention vector
multi-head Self Attention
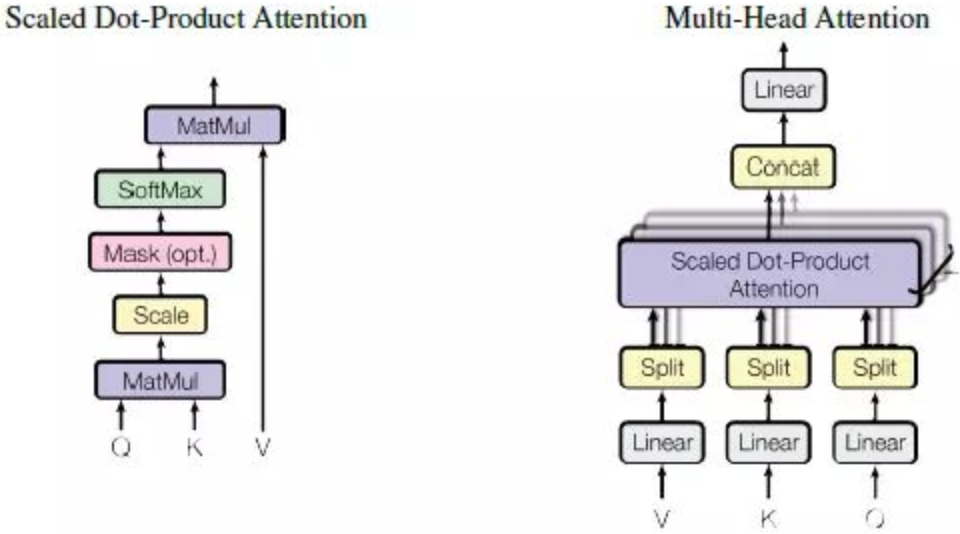 如上图左所示,首先把输入Input经过三个不同的线性变换分别得到Q、K、V,然后把Q和K做dot Product相乘(矩阵乘法),得到输入Input词与词之间的对其关系,然后经过尺度变换(scale)、掩码(mask)和softmax操作,得到最终的Self Attention矩阵。尺度变换是为了防止输入值过大导致训练不稳定,mask则是为了将Padding的内容过滤掉。(有点类似于LSTM的门操作)
如上图左所示,首先把输入Input经过三个不同的线性变换分别得到Q、K、V,然后把Q和K做dot Product相乘(矩阵乘法),得到输入Input词与词之间的对其关系,然后经过尺度变换(scale)、掩码(mask)和softmax操作,得到最终的Self Attention矩阵。尺度变换是为了防止输入值过大导致训练不稳定,mask则是为了将Padding的内容过滤掉。(有点类似于LSTM的门操作)
position embedding & Transformer
position embedding技术在很多任务上表现出了非常不错的效果,一般与CNN配合使用,将每个词出现的位置进行embedding,与Word embedding一起作为输入进行卷积操作,这样使CNN与RNN一样,能够表达位置关系和时序性。
Transformer编码器由Google发明,在其发表的论文《Attention is all you need》中进行了详细介绍,核心其实就是利用了position embedding和multi-head Self Attention,它完全舍弃了RNN的循环式网络结构,完全基于自注意力机制来对一段文本进行建模。Transformer所使用的注意力机制的核心思想是去计算一句话中的每个词对于这句话中所有词的相互关系,然后认为这些词与词之间的相互关系在一定程度上反应了这句话中不同词之间的关联性以及重要程度,因此再利用这些相互关系来调整每个词的重要性(权重)就可以获得每个词新的表达。这个新的表征不但蕴含了该词本身,还蕴含了其他词与这个词的关系,因此和单纯的词向量相比是一个更加全局的表达。Transformer通过对输入的文本不断进行这样的注意力机制层和普通的非线性层交叠来得到最终的文本表达。Transformer模型架构如下所示:
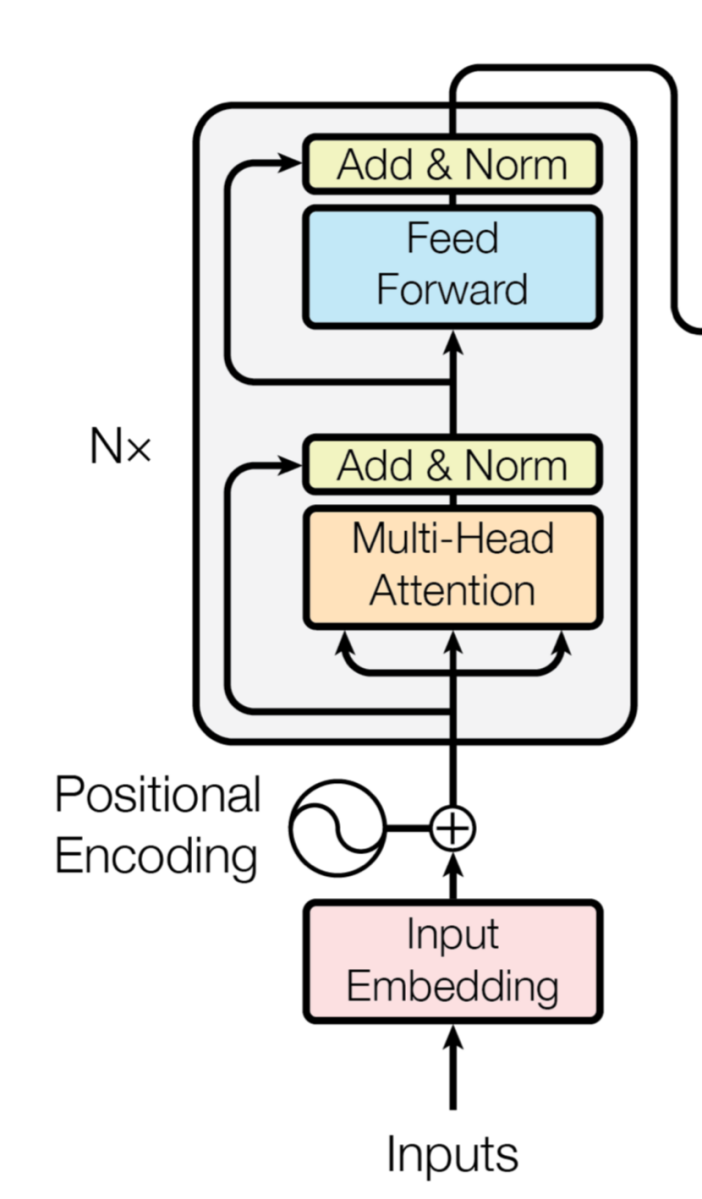
模型训练
代码地址 https://github.com/qianshuang/seq2seq
运行结果:
Configuring model...
Loading data...
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 3.4, Val Loss: 3.4, Time: 0:00:02 *
Epoch: 2
Iter: 10, Train Loss: 3.4, Val Loss: 3.4, Time: 0:00:04 *
Epoch: 3
Iter: 20, Train Loss: 3.3, Val Loss: 3.3, Time: 0:00:07 *
Epoch: 4
Iter: 30, Train Loss: 3.1, Val Loss: 3.1, Time: 0:00:10 *
Epoch: 5
Epoch: 6
Iter: 40, Train Loss: 3.0, Val Loss: 3.0, Time: 0:00:12 *
Epoch: 7
Iter: 50, Train Loss: 3.0, Val Loss: 3.0, Time: 0:00:15 *
Epoch: 8
Iter: 60, Train Loss: 2.8, Val Loss: 2.9, Time: 0:00:17 *
......
......
Epoch: 314
Iter: 2510, Train Loss: 0.091, Val Loss: 0.4, Time: 0:07:56
Epoch: 315
Epoch: 316
Iter: 2520, Train Loss: 0.078, Val Loss: 0.4, Time: 0:07:56
No optimization for a long time, auto-stopping...
Testing...
原始输入: common
输出: cmmmoo<EOS>
社群
- QQ交流群

- 微信交流群

- 微信公众号
