算法原理
Autoencoders是一种无监督学习,它通过神经网络来学习输入数据的有效表示。它的作用主要有以下几个方面:
- 降维。通过Autoencoders学习到输入数据的有效的稠密向量表达。
- 特征提取。Autoencoders是一个功能强大的特征探测器,它们可以用于深度神经网络的无监督预训练。
- 生成模型。可以利用Autoencoders生成与训练数据相似的新数据。
Autoencoders与seq2seq类似,也是由两部分组成,一个encoder(recognition network)将输入转换成一个内部表示,然后一个decoder(generative network)将该内部表示转换成output输出。因为是无监督的,所以decoder阶段没有target,或者说decoder阶段的target是它自身,所以训练的目的是让模型学习输入数据中最重要的特征,并剔除不重要的特征。
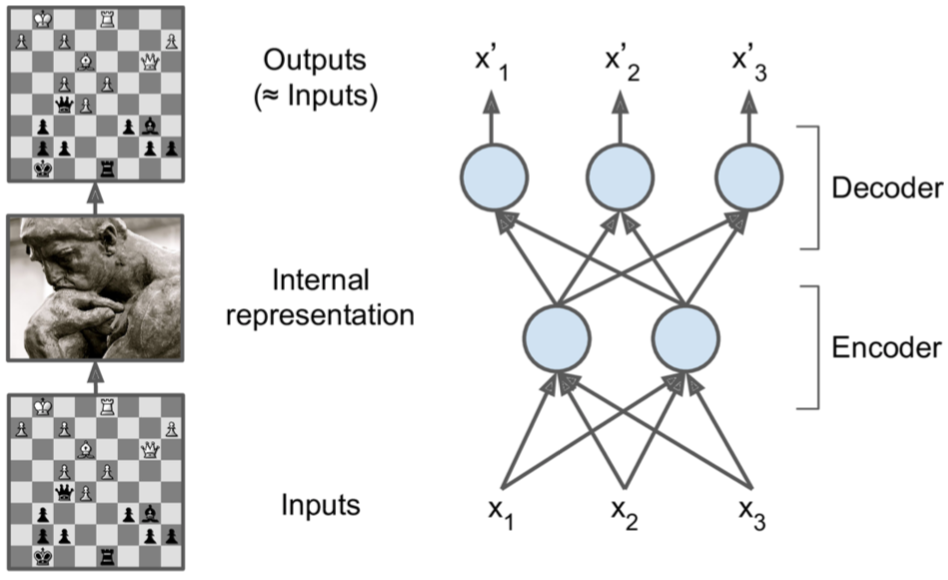
PCA & data representation
如果Autoencoders使用线性激活函数,并且损失函数使用MSE(均方误差),可以证明它最终就是在执行PCA。下面使用Autoencoders实现PCA,将3D输入数据投射到2D。
# 3D输入数据
n_inputs = 3
# 2D投影
n_hidden = 2
n_outputs = n_inputs
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
# hidden就是最终的降维结果
hidden = fully_connected(X, n_hidden, activation_fn=None)
outputs = fully_connected(hidden, n_outputs, activation_fn=None)
# MSE
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X))
training_op = tf.train.AdamOptimizer(learning_rate=0.01).minimize(reconstruction_loss)
当然Autoencoders也可以使用带激活函数的多层神经网络,这被称为stacked autoencoders或deep autoencoders,更多的隐藏层可以让Autoencoders学到更加复杂的表示,但是也不能使Autoencoders过于强大,否则学到的表示可能并无用处,也不能在新的实例上有很好的泛化能力,即过拟合,就相当于GAN能够将随机生成的数据转换为生成图片,但是这个随机数据的中间表示并无用处。
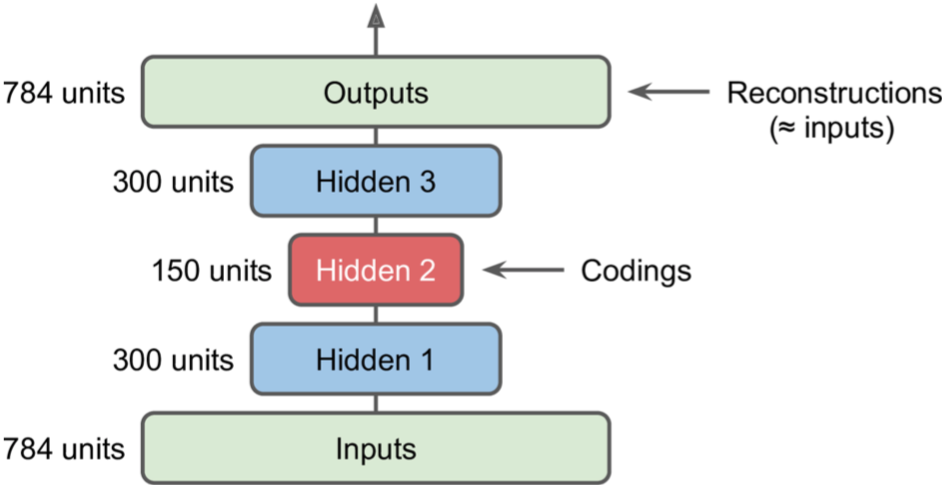 可以发现网络是整齐对称的,所以Codings后的层可以reuse其之前层的参数(transpose一下即可),这样参数减半加速了训练过程,并能有效防止过拟合。
可以发现网络是整齐对称的,所以Codings后的层可以reuse其之前层的参数(transpose一下即可),这样参数减半加速了训练过程,并能有效防止过拟合。
其实我们还可以先训练单隐层的Autoencoders得到的data representation为hidden1,然后将hidden1作为输入输出再训练一个Autoencoders得到hidden1的data representation为hidden2,这个hidden2就是我们最终的data representation。
特征可视化
一旦你的autoencoder模型能够学到一些feature(data representation),你可能想看看它到底学出来什么东西,对于图像来说,你可以创建一个图像,其中像素的强度对应于给定神经元的连接的权重。举个例子,下面的代码画出了第一个隐藏层的前五个神经元所学到的特征表示:
with tf.Session() as sess:
[...] # train autoencoder
weights1_val = weights1.eval()
for i in range(5): # 前五个神经元
# weights1_val的每一列代表一个神经元权重,T()取转置
plot_image(weights1_val.T[i])
 输出隐藏层的每个神经元的输出值,即可知道哪些神经元被激活。然后通过上面的代码分别查看这些神经元学到了哪些特征。
输出隐藏层的每个神经元的输出值,即可知道哪些神经元被激活。然后通过上面的代码分别查看这些神经元学到了哪些特征。
迁移学习
有了Autoencoders,现在可以通过无监督的方式来做pretrain了。
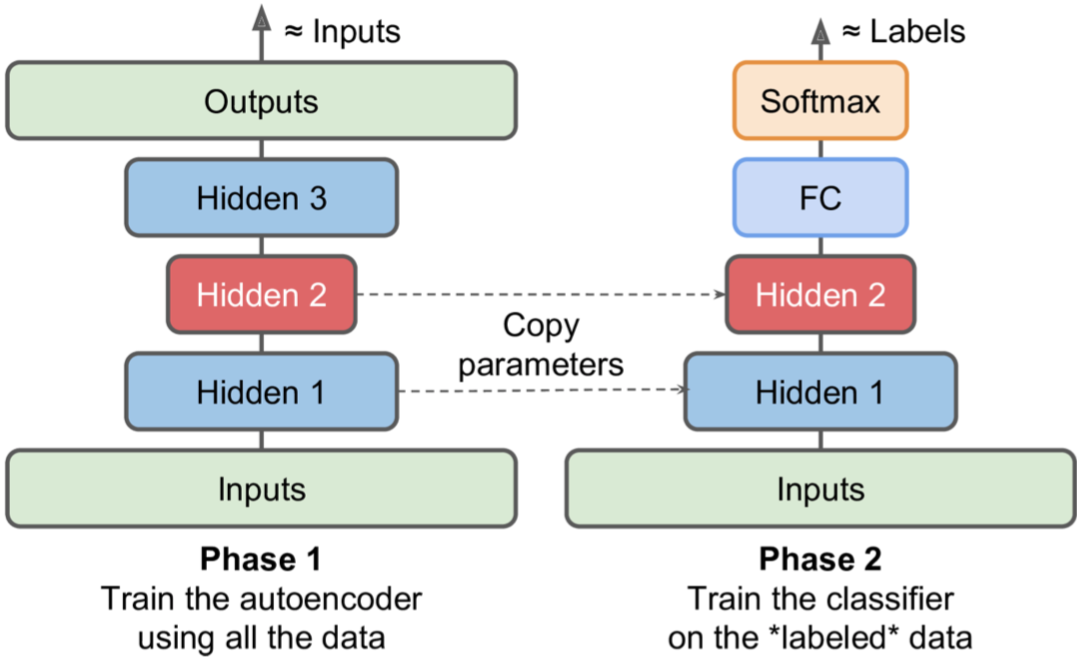
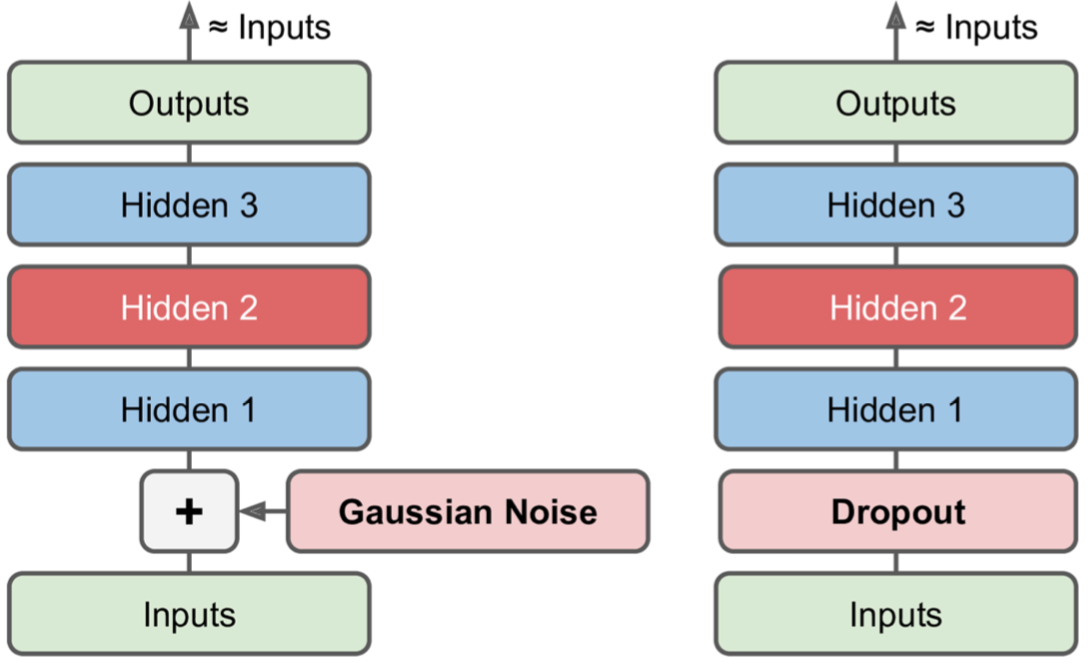
Denoising Autoencoders
Denoising Autoencoders,去噪自动编码机,即向其输入添加噪声,训练它以恢复原始的无噪声输入。这可以防止自动编码器将其输入简单地复制到其输出。加噪声的方式可以是高斯噪声,也可以通过对输入进行dropout。
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
X_noisy = X + tf.random_normal(tf.shape(X)) # 高斯噪声,注意只有在训练的时候才加入
hidden1 = activation(tf.matmul(X_noisy, weights1) + biases1)
[...]
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
from tensorflow.contrib.layers import dropout
keep_prob = 0.7
is_training = tf.placeholder_with_default(False, shape=(), name='is_training')
X = tf.placeholder(tf.float32, shape=[None, n_inputs])
X_drop = dropout(X, keep_prob, is_training=is_training)
hidden1 = activation(tf.matmul(X_drop, weights1) + biases1)
[...]
reconstruction_loss = tf.reduce_mean(tf.square(outputs - X)) # MSE
Sparse Autoencoders
Sparse Autoencoders,稀疏自动编码机。它的核心思想是,在训练时,限制codings层的神经元大部分时间都是处于抑制状态,也就是说减少codings层被激活的神经元数量。追求的是一个少而精,其功能类似于dropout。
# 计算p、q的接近程度
def kl_divergence(p, q):
return p * tf.log(p / q) + (1 - p) * tf.log((1 - p) / (1 - q))
sparsity_target = 0.1
# codings层
hidden1 = tf.nn.sigmoid(tf.matmul(X, weights1) + biases1)
# 计算codings层每个神经元的平均激活程度(0代表完全抑制,1代表完全激活)
hidden1_mean = tf.reduce_mean(hidden1, axis=0)
# sparsity_loss,sparsity_target为超参数
sparsity_loss = tf.reduce_sum(kl_divergence(sparsity_target, hidden1_mean))
# reconstruction_loss
logits = tf.matmul(hidden1, weights2) + biases2)
outputs = tf.nn.sigmoid(logits)
# X和logits分别先计算sigmoid值,然后计算cross_entropy
reconstruction_loss = tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits))
loss = reconstruction_loss + 0.2 * sparsity_loss # 加权和
training_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
Variational Autoencoders
Variational Autoencoders,变分自动编码器。
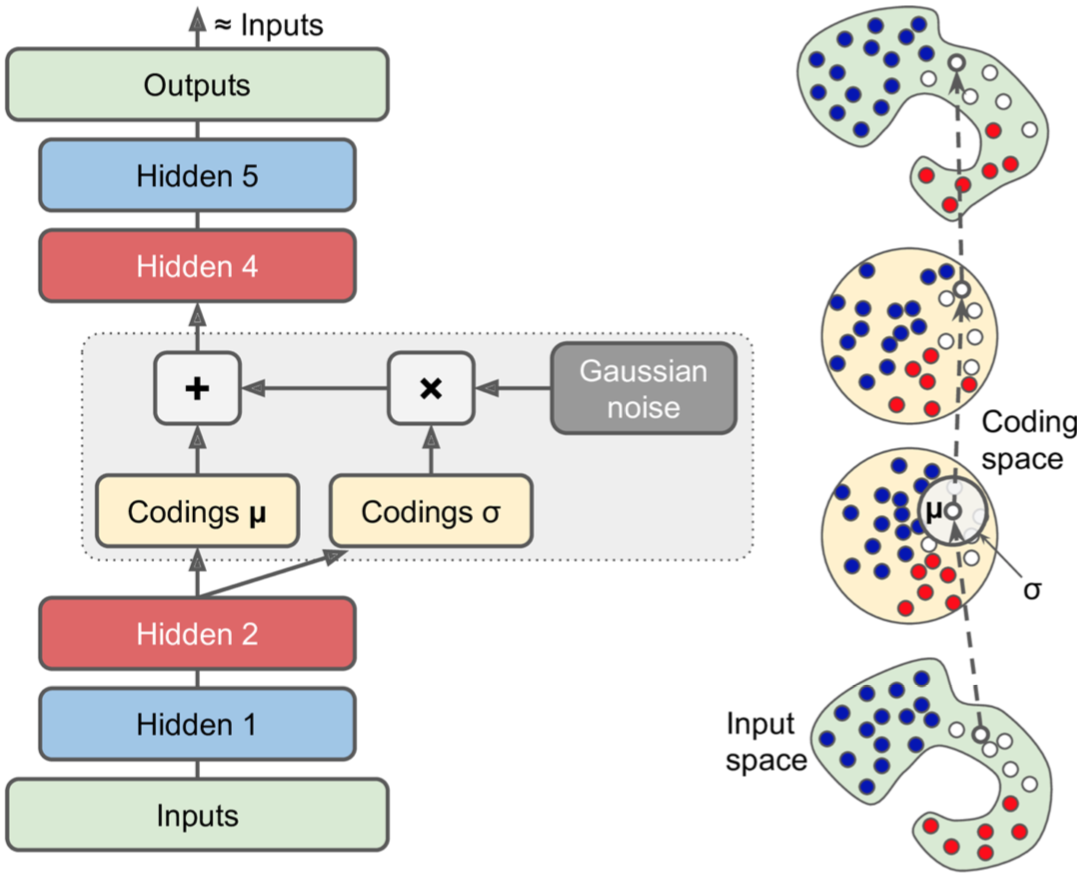
- 从hidden2生成两个hidden3,一个表示均值μ,另一个表示方差σ。
- 从均值μ、方差σ的高斯分布中随机采样得到实际的coding。
- 在训练期间,损失函数推动输入数据向编码空间(也称为潜在空间)逐渐迁移,最终形成高斯分布。
n_inputs = 28 * 28 # for MNIST
n_hidden1 = 500
n_hidden2 = 500
n_hidden3 = 20 # codings
n_hidden4 = n_hidden2
n_hidden5 = n_hidden1
n_outputs = n_inputs
with tf.contrib.framework.arg_scope([fully_connected],
activation_fn=tf.nn.elu,
weights_initializer=tf.contrib.layers.variance_scaling_initializer()):
X = tf.placeholder(tf.float32, [None, n_inputs])
hidden1 = fully_connected(X, n_hidden1)
hidden2 = fully_connected(hidden1, n_hidden2)
# 高斯均值
hidden3_mean = fully_connected(hidden2, n_hidden3, activation_fn=None)
# 高私方差
hidden3_gamma = fully_connected(hidden2, n_hidden3, activation_fn=None)
# 生成高斯分布
hidden3_sigma = tf.exp(0.5 * hidden3_gamma)
noise = tf.random_normal(tf.shape(hidden3_sigma), dtype=tf.float32)
# 得到codings,均值为0,方差为1
hidden3 = hidden3_mean + hidden3_sigma * noise
hidden4 = fully_connected(hidden3, n_hidden4)
hidden5 = fully_connected(hidden4, n_hidden5)
logits = fully_connected(hidden5, n_outputs, activation_fn=None)
outputs = tf.sigmoid(logits)
reconstruction_loss = tf.reduce_sum(
tf.nn.sigmoid_cross_entropy_with_logits(labels=X, logits=logits))
# 高斯损失
latent_loss = 0.5 * tf.reduce_sum(
tf.exp(hidden3_gamma) + tf.square(hidden3_mean) - 1 - hidden3_gamma)
cost = reconstruction_loss + latent_loss
training_op = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
注意:
- tf.random_normal()方法以均值为0方差为1初始化矩阵的每一个元素值,那么每个instance的所有维度值也组成高斯分布,batch个训练样本同样组成高斯分布。
- 你可以很容易地生成一个新的实例,只需从高斯分布中抽样codings,解码它即可。
n_digits = 60
n_epochs = 50
batch_size = 150
with tf.Session() as sess:
init.run()
for epoch in range(n_epochs):
for iteration in range(n_batches):
X_batch, y_batch = mnist.train.next_batch(batch_size)
sess.run(training_op, feed_dict={X: X_batch})
codings_rnd = np.random.normal(size=[n_digits, n_hidden3])
# 直接feed hidden3
outputs_val = outputs.eval(feed_dict={hidden3: codings_rnd})
推荐系统
Autoencoders最常应用于推荐系统模型,有很多种实现方式:
- 首先构建user-item-rate评分矩阵,Autoencoders模型的输入为评分矩阵R中的一行(User-based)或者一列(Item-based),其目标函数通过计算输入与输出(只计算有值的部分)的均方误差损失,而R中missing的评分值通过模型的输出来预测,进而给用户做推荐。
- 回忆我们之前的矩阵分解MF算法,R = U X I,R就是用户打分矩阵,U就是user embedding,I就是item embedding。这其实就是PCA的过程,亦即线性Autoencoders。
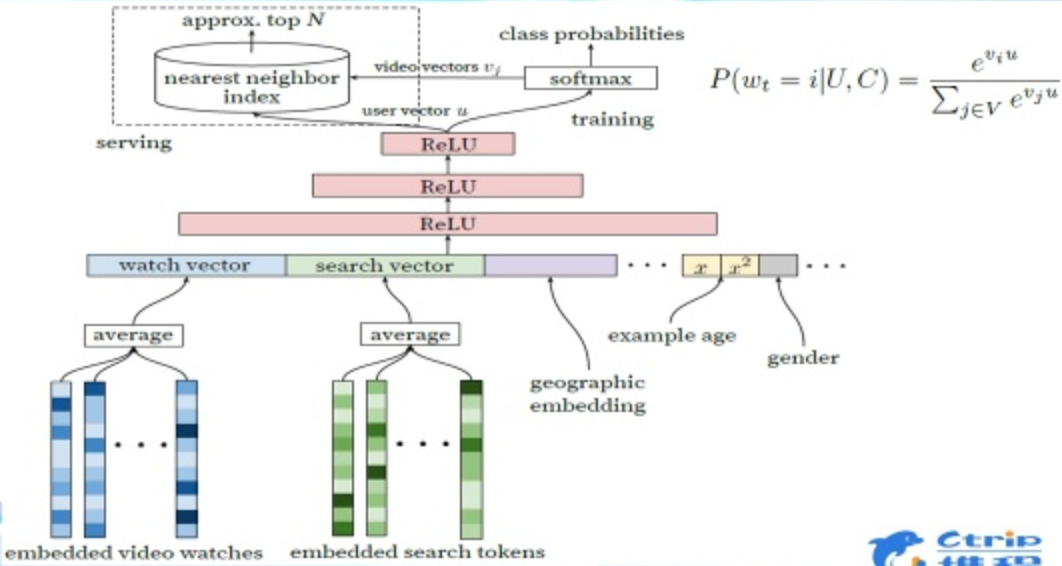
- 最常用还是Google的wide & deep模型,模型融入了user embedding和side information(用户画像特征、商品属性信息、商品内容信息等),这是一个有监督的训练过程,输入label是用户对视频的喜好分类,损失函数的计算只取有打分记录的值。
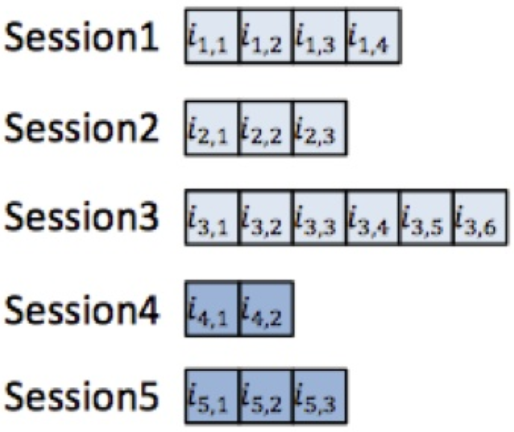
- 如果还记录了session信息,还可以在3的基础上借助于HAN即Hierarchical RNN模型,进行评分预测。
社群
- QQ交流群

- 微信交流群

- 微信公众号
