算法原理
以搜索引擎和搜索广告为例,最重要的也最难解决的问题是语义相似度,这里主要体现在两个方面:召回和排序。 在召回时,传统的以全文检索的方式计算文本相似性的方法,比如TF-IDF,无法有效发现语义类query-doc结果对,如”从北京到上海的机票”与”携程网”的相似性、”快递软件”与”菜鸟裹裹”的相似性。 在排序时,一些细微的语言变化往往带来巨大的语义变化,如”小宝宝生病怎么办”和”狗宝宝生病怎么办”、”深度学习”和”学习深度”。 DSSM(Deep Structured Semantic Models)为计算语义相似度提供了一种思路。
DSSM的原理很简单,通过搜索引擎里Query和Title的海量点击曝光日志,用DNN把Query和Title表达为低维语义向量,并通过cosine距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得句子的低维语义向量表达。
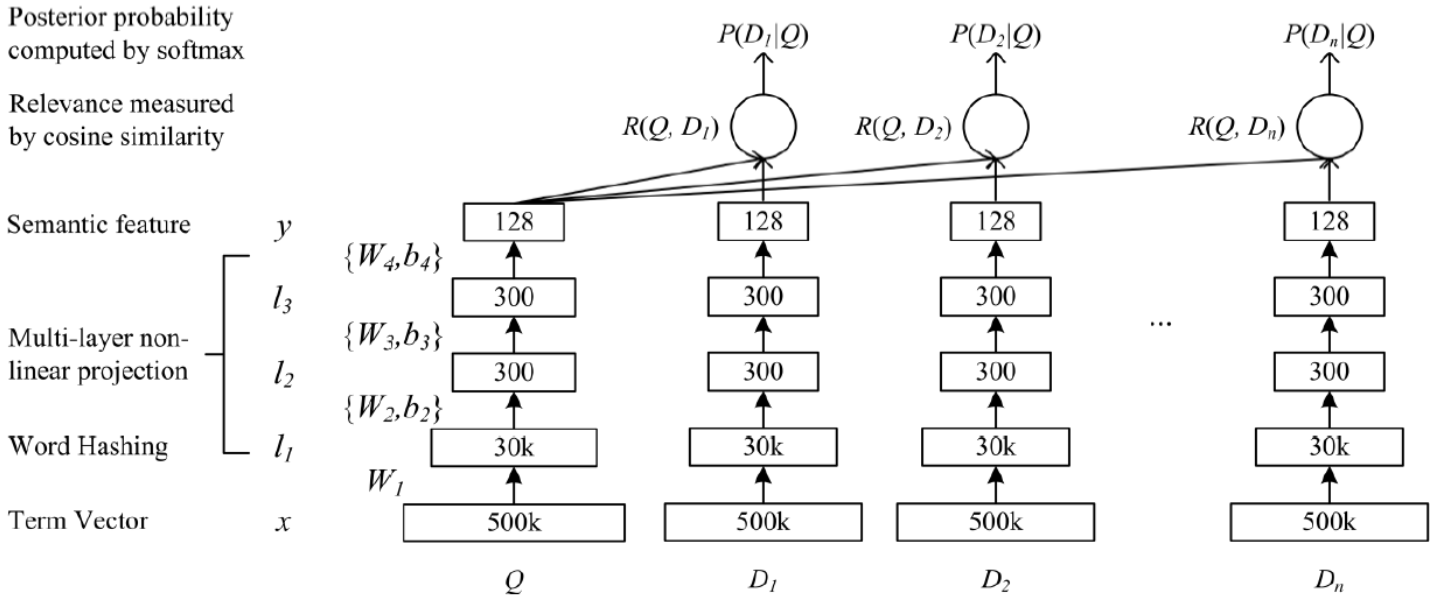
- 原始DSSM的输入是Word的one-hot向量,即出现为1,不出现为0(不是词频)。当然推荐使用word embedding。
- l1,l2,l3是三层全连接神经网络,输出层使用tanh激活函数,得到128维语义向量表达。
- Query和Doc的语义相似度可以用这两个语义向量的cosine距离来表示,然后通过softmax做归一化处理。
- 将第3步得到的结果与groudtruth(点击为1,未点击为0)做cross_entropy损失,进行模型训练。
可以看到,DSSM与QQ-match模型非常类似,解决的问题领域也差不多,只不过QQ-match的输入是QQ pair(一对一),判断用户query与doc是否match。而DSSM的输入是一对多,即一个query,多篇doc,相当于直接做语义检索,一个模型既做召回也做ranking。
DSSM模型特点:
- DSSM类的模型在最后一步计算相似度的时候使用cosine similarity,其实换成MLP效果会更好,因为cosine similarity是完全无参的,而且是按位点乘,但是向量间不一定有这样的对其关系。
- DSSM使用用户的点击数据作为训练数据。即假设Ds表示对于一个查询Q的所有候选文档,那么D^+表示以用户点击的文档作为正例,D^-表示以没有点击的作为负例。
CNN-DSSM & LSTM-DSSM & MV-DSSM
CNN-DSSM只不过是将原始DSSM模型的三层全连接神经网络换成了CNN,即使用CNN得到query和doc的语义向量表达。同样的,LSTM-DSSM也只不过是换成了LSTM而已。
原始DSSM中,全连接神经网络的参数对于query和doc是共享的,所以又有了MV-DSSM(muity-view DSSM),即query和doc分别使用相同结构但不同参数的神经网络(所有的doc依然共享神经网络参数)。
社群
- QQ交流群

- 微信交流群

- 微信公众号
