TensorFlow的并行分为操作间并行和操作内并行,二者同时发生,并且都是通过线程池技术实现的。操作间并行是指node与node之间可以并行执行,操作内并行是指每个node内的运算可以并行计算。
对于MLP,因为后一层的输入来自于上一层的输出,所以层与层之间无法并行,但是在每一层内部,不管是执行前向计算还是执行反向传播,都是可以并行计算的;对于RNN,我们前面讲过,将RNN沿着time step展开,其实就是一个特殊的全连接神经网络,所以层内也能并行计算;而对于CNN,每一层的卷积和pooling操作都可以完全并行。所以使用GPU,不管是在深度学习模型的训练阶段,还是模型的测试和预测阶段,都能得到数量级的加速效果。
那么怎样使用GPU服务呢?当然你可以购买一台GPU服务器,安装GPU驱动,但是这样成本较大,对于中小型企业来说,最合适的办法是使用云服务,有很多种选择,比如AWS云、Google云、阿里云等,他们都提供模型训练以及模型的部署和预测服务。
- AWS云 https://aws.amazon.com/cn/blogs/machine-learning/get-started-with-deep-learning-using-the-aws-deep-learning-ami/
- Google云 https://cloud.google.com/ml-engine/
- 阿里云 https://blog.csdn.net/Lo_Bamboo/article/details/78601328
enable GPU
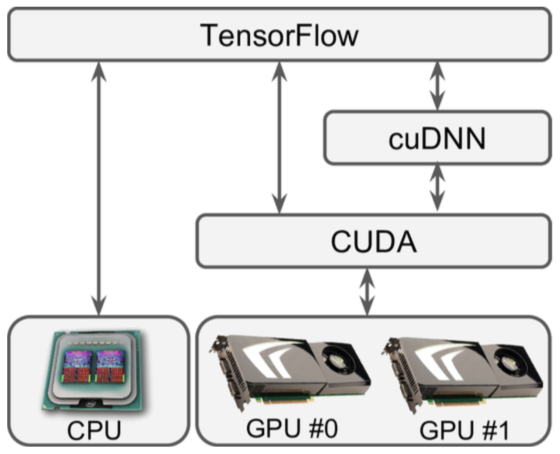 TensorFlow使用CUDA和cuDNN来控制GPU,可以使用nvidia-smi命令查看可用的GPU卡以及每张GPU卡上所运行的进程:
TensorFlow使用CUDA和cuDNN来控制GPU,可以使用nvidia-smi命令查看可用的GPU卡以及每张GPU卡上所运行的进程:
$ nvidia-smi
Wed Sep 16 09:50:03 2018
+------------------------------------------------------+
| NVIDIA-SMI 352.63 Driver Version: 352.63 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GRID K520 Off | 0000:00:03.0 Off | N/A |
| N/A 27C P8 17W / 125W | 11MiB / 4095MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
然后还需要安装GPU版本的TensorFlow:
pip3 install --upgrade tensorflow-gpu
现在我们来看一下TensorFlow是否能正确使用CUDA和cuDNN探测到所以的GPU卡:
>>> import tensorflow as tf
I [...]/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcudnn.so locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcuda.so.1 locally
I [...]/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally
>>> sess = tf.Session()
[...]
I [...]/gpu_init.cc:102] Found device 0 with properties:
name: GRID K520
major: 3 minor: 0 memoryClockRate (GHz) 0.797
pciBusID 0000:00:03.0
Total memory: 4.00GiB
Free memory: 3.95GiB
I [...]/gpu_init.cc:126] DMA: 0
I [...]/gpu_init.cc:136] 0: Y
I [...]/gpu_device.cc:839] Creating TensorFlow device
(/gpu:0) -> (device: 0, name: GRID K520, pci bus id: 0000:00:03.0)
管理GPU RAM
默认情况下,TensorFlow会在运行时自动抓取所有可用GPU中的所有RAM,因此当第一个TensorFlow程序仍在运行时,您将无法启动第二个TensorFlow程序。否则报错:
E [...]/cuda_driver.cc:965] failed to allocate 3.66G (3928915968 bytes) from device: CUDA_ERROR_OUT_OF_MEMORY
通常有三种解决办法:
- 设置CUDA_VISIBLE_DEVICES环境变量,让每个进程只能看到相应的GPU卡。
$ CUDA_VISIBLE_DEVICES=0,1 python3 program_1.py # and in another terminal: $ CUDA_VISIBLE_DEVICES=3,2 python3 program_2.py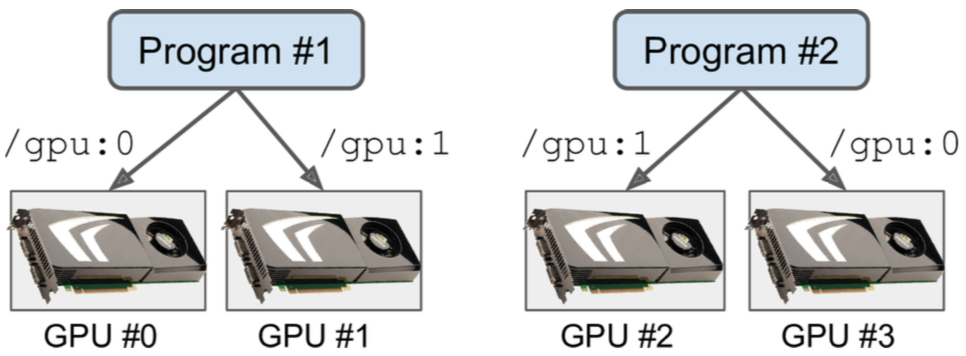
- 设置TensorFlow程序只占用每个GPU内存的一部分。
config = tf.ConfigProto() config.gpu_options.per_process_gpu_memory_fraction = 0.4 session = tf.Session(config=config) - 设置config.gpu_options.allow_growth=True,告诉TensorFlow仅在需要时才获取内存。但是这只是缓兵之计,因为TensorFlow一旦获取到就不会再释放内存(以避免内存碎片),所以一段时间后你可能仍会耗尽内存。
放置node到特定Device
TensorFlow可以在所有可用设备上自动分配ops和variable(统称为node),放置器的分配规则如下:
- 如果用户将node固定到设备(如下所述),则放置器将其放置在该设备上。
- 否则,默认为GPU,如果没有GPU,则默认为CPU。
例如,以下代码将变量a和常量b固定在CPU上,但乘法节点c未固定在任何设备上,因此它将被置于默认设备GPU#0上:
with tf.device("/cpu:0"): # /cpu:0设备聚合多CPU系统上的所有CPU,目前无法在特定CPU上固定node或仅使用所有CPU的子集
a = tf.Variable(3.0)
b = tf.constant(4.0)
c = a * b
config = tf.ConfigProto()
config.log_device_placement = True # 在放置节点时记录日志
sess = tf.Session(config=config)
I [...] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GRID K520, pci bus id: 0000:00:03.0)
[...]
a.initializer.run(session=sess)
I [...] a: /job:localhost/replica:0/task:0/cpu:0 # I表示Info
I [...] a/read: /job:localhost/replica:0/task:0/cpu:0
I [...] mul: /job:localhost/replica:0/task:0/gpu:0
I [...] a/Assign: /job:localhost/replica:0/task:0/cpu:0
I [...] b: /job:localhost/replica:0/task:0/cpu:0
I [...] a/initial_value: /job:localhost/replica:0/task:0/cpu:0
print(sess.run(c)) # 12
还可以使用动态放置策略:
def variables_on_cpu(op):
# 可以在这里实现复杂的round-robin策略
if op.type == "Variable":
return "/cpu:0"
else:
return "/gpu:0"
with tf.device(variables_on_cpu): # 对块内的所有node使用动态放置策略
a = tf.Variable(3.0)
b = tf.constant(4.0)
c = a * b
要使TensorFlow操作在特定设备上运行,该操作需要具有该设备的实现,这叫做内核kernel。许多操作都有kernel用于CPU和GPU,但不是全部,例如TensorFlow没有用于整数变量的GPU内核,因此当TensorFlow尝试将变量i放在GPU#0上时会报错:
with tf.device("/gpu:0"):
i = tf.Variable(3)
sess.run(i.initializer)
Traceback (most recent call last): # 报错
[...]
tensorflow.python.framework.errors.InvalidArgumentError: Cannot assign a device to node 'Variable': Could not satisfy explicit device specification
可以通过以下方式解决:
with tf.device("/gpu:0"):
i = tf.Variable(3)
config = tf.ConfigProto()
config.allow_soft_placement = True # the placer runs and falls back to /cpu:0 when /gpu:0 fails
sess = tf.Session(config=config)
sess.run(i.initializer)
Control Dependencies
在某些情况下,推迟对某些操作的计算是明智的,即使它所依赖的所有操作都已执行。例如,如果它使用大量内存,那么最好在最后一刻对其进行计算,以避免不必要地占用其他操作可能需要的RAM;另一个示例是一组依赖于位于外部设备的数据的操作,如果它们全部同时运行,可能会使设备的通信带宽饱和,那么其他需要传输数据的操作也将被停止,最终他们都会等待I/O,所以最好是顺序执行这些数据交换繁重的操作,允许设备并行执行其他操作。要推迟对某些node的计算,一个简单的解决方案是添加控制依赖项。
a = tf.constant(1.0)
b = a + 2.0
# 仅在计算a和b之后,再计算x和y,因为b又依赖a,所以可以直接用tf.control_dependencies([b])
with tf.control_dependencies([a, b]):
x = tf.constant(3.0)
y = tf.constant(4.0)
z = x + y
社群
- 微信公众号
