知识图谱介绍
下面我们将从三个问题出发来帮助大家理解知识图谱:
- What,即什么是知识图谱?
- Where,即知识图谱的应用场景有哪些?
- How,怎样构建知识图谱?
What
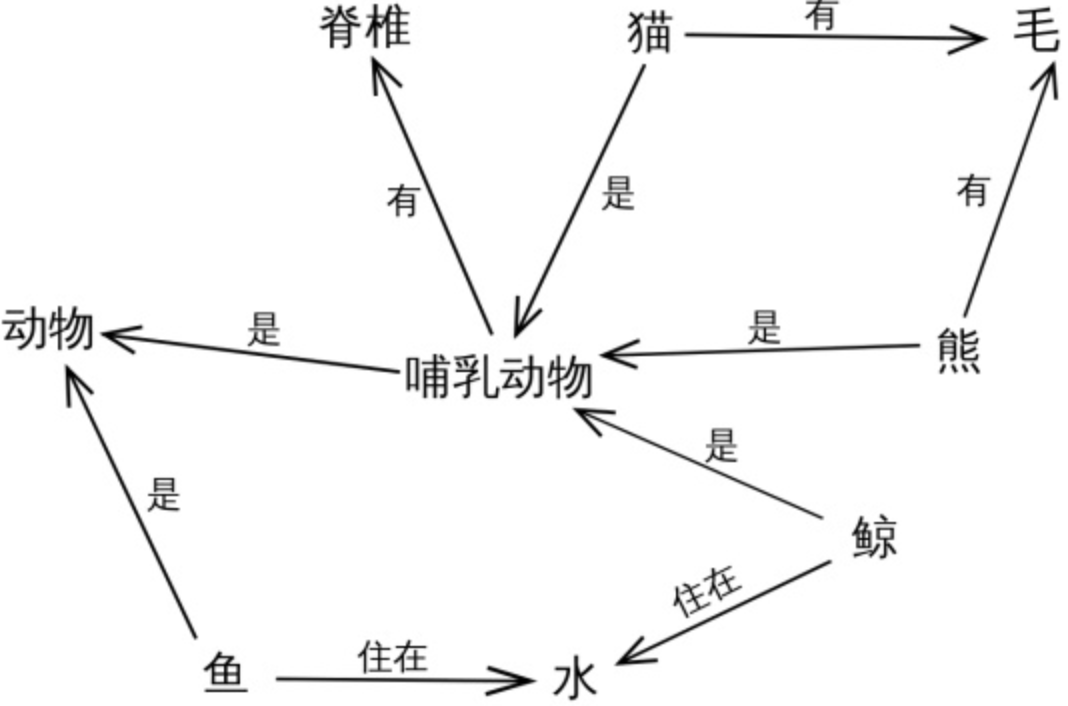
知识图谱(Knowledge Graph,KG)是NLP的一项技术领域。有人说关系型数据库的出现是人类社会的倒退,因为大千世界的信息并不是结构化存储和表示的,而是通过图来表示节点与节点之间关系的网状结构。
Where
- 语义搜索(智能搜索)。借助于知识图谱可以实现网页搜索到语义搜索的转变。
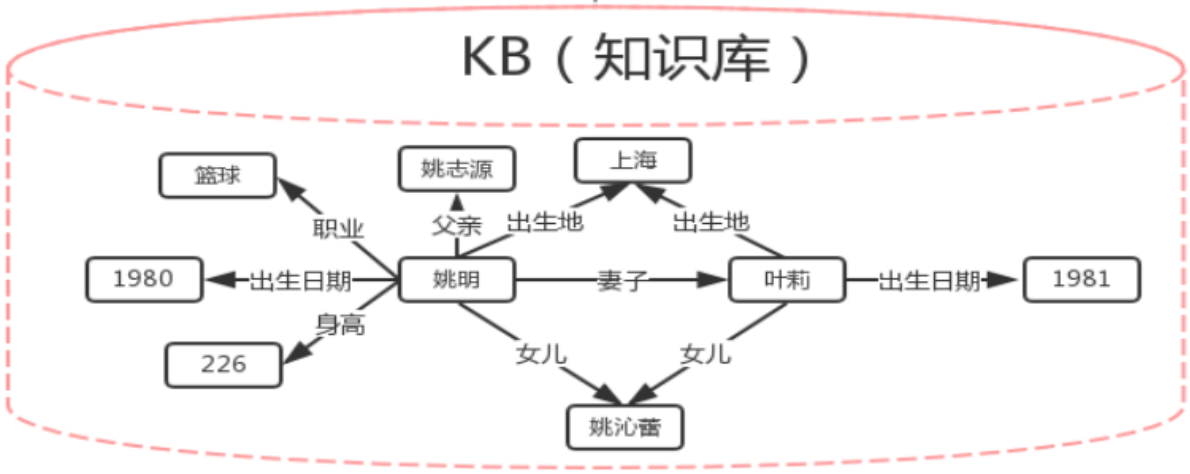
- 常识推理。比如通过知识图谱可以推断出,吴彦祖的老婆的孩子的母亲 –> Lisa S. 推理能力是机器智能的基础,当人在听到或看到一句话时,他能使用自己所有的常识(common sense)和知识去辅助理解,这些常识(common sense)和知识对于机器来说就必须通过知识图谱来实现。
- 智能问答。问答是搜索引擎的下一代交互形式,即输入是用户的问题,输出不再是包含答案的相关文档,而是直接返回精确的答案,这就必须通过知识图谱来实现。
- 推荐系统。将知识图谱应用到推荐系统,使推荐结果更加精准和个性化。
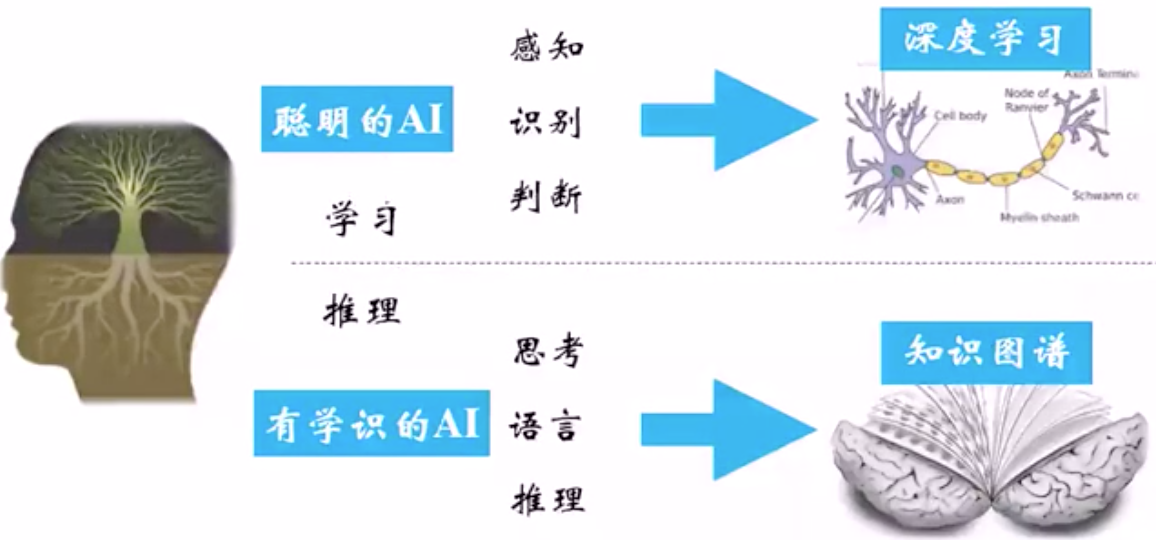
- 知识图谱结合深度学习。机器智能的发展其实包括4个阶段的能力:
- 辨别能力。目前的机器学习和深度学习都是通过海量样本去发现其中的统计概率学规律,这其实是浅层次的识别能力。
- 理解能力。要使机器具备语义理解能力,就必须向机器灌输常识和知识。
- 生成能力。在具备了辨别能力和理解能力后,还能够加以推断和博弈,从无到有的生成知识。
- 类人能力。真正做到像人一样,甚至超越人类。
How
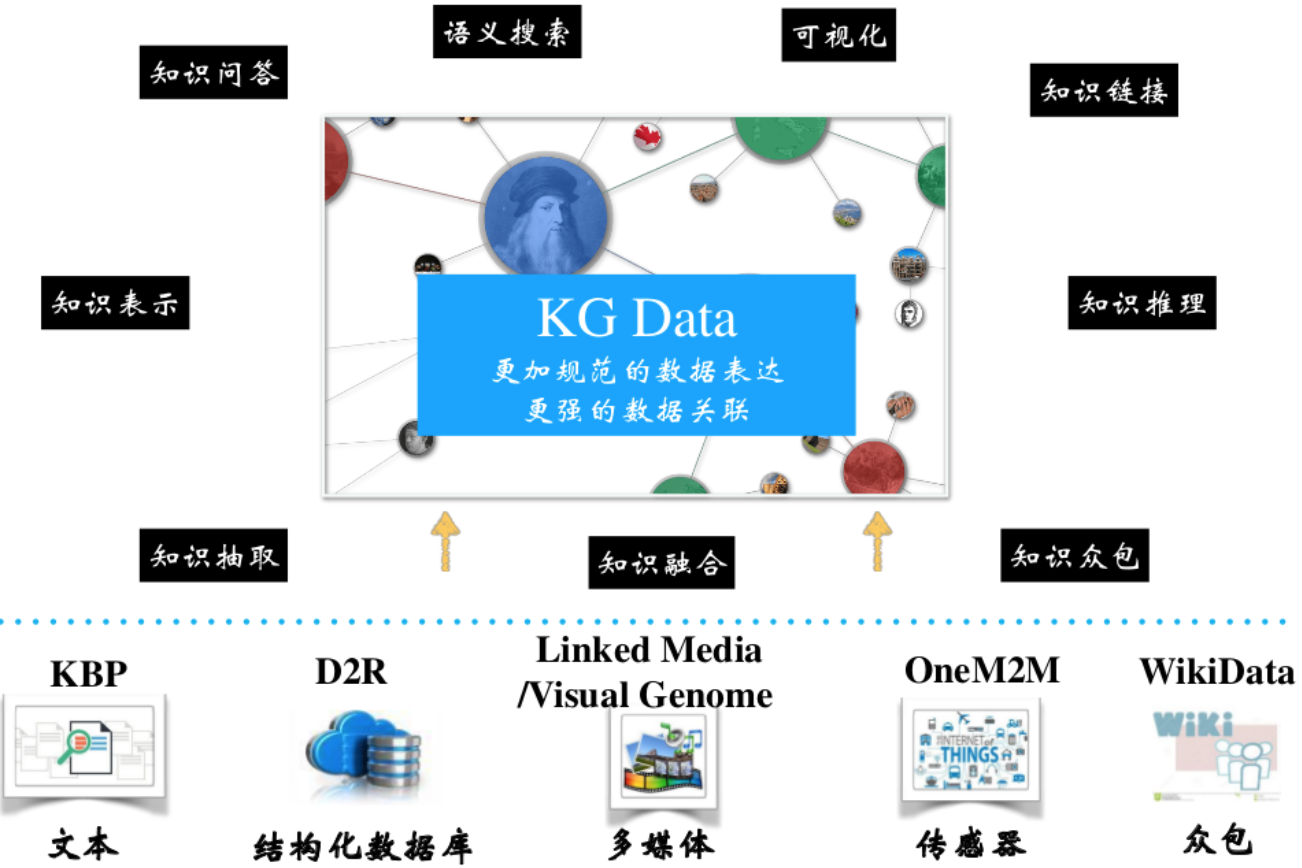 上图描述了知识图谱的技术体系。最底层我们有大量的文本数据、结构化数据、多媒体文件等数据来源,通过知识抽取、知识融合、知识众包等技术获取我们需要的知识,而后通过知识表示、知识推理、知识链接等技术将知识规范有序的组织在一起并存储起来(知识存储),最终用于知识问答、语义搜索、可视化等方面。下面我们将依次进行讲解。
上图描述了知识图谱的技术体系。最底层我们有大量的文本数据、结构化数据、多媒体文件等数据来源,通过知识抽取、知识融合、知识众包等技术获取我们需要的知识,而后通过知识表示、知识推理、知识链接等技术将知识规范有序的组织在一起并存储起来(知识存储),最终用于知识问答、语义搜索、可视化等方面。下面我们将依次进行讲解。
知识表示
知识表示就是对知识的一种描述,或者说是对知识的一组约定,一种计算机可以接受的用于描述知识的数据结构。它是机器通往智能的基础,使得机器可以像人一样运用知识。
本质上,知识图谱是一种揭示实体之间关系的语义网络,可以对现实世界的事物及其相互关系进行形式化地描述。
三元组是知识图谱的一种通用表示方式,即G=(E1,R,E2),其中:
- G:表示知识图谱
- E:表示知识图谱中的实体
- R:表示知识图谱中的关系。用来连接两个实体,刻画它们之间的关联
RDF和SPARQL是知识表示的核心技术。
RDF(Resource Description Framework,资源描述框架),将知识以三元组的形式呈现,即每一份知识都可以被分解为:(subject, predicate, object)。所以RDF具备一定的推理能力:
 SPARQL是RDF的查询语言,语法与SQL相近,同时还被所有主流的图数据库支持:
SPARQL是RDF的查询语言,语法与SQL相近,同时还被所有主流的图数据库支持:
 上面的查询语句表示:查询所有选修CS328课程的学生。
上面的查询语句表示:查询所有选修CS328课程的学生。
知识抽取
知识抽取,即从不同来源、不同结构的数据中进行知识提取,形成知识(链接数据)并存入到知识图谱。
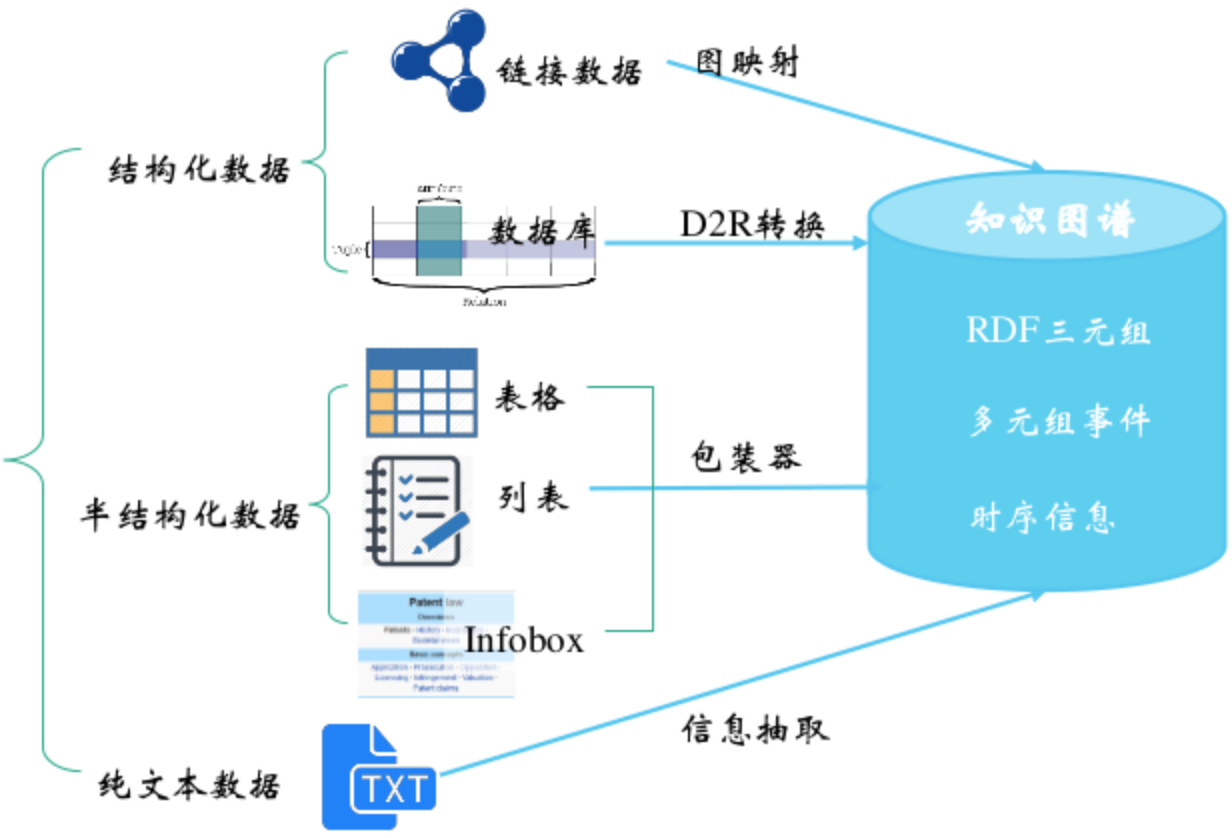 对于结构化数据的知识抽取,就是指类似于关系型数据库中的数据,他们往往各项之间存在明确的关系名称和对应关系,因此我们可以简单的将其转化为RDF或其他形式的知识库内容。一种常用的W3C推荐的映射语言及工具是R2RML(RDB2RDF)。
对于结构化数据的知识抽取,就是指类似于关系型数据库中的数据,他们往往各项之间存在明确的关系名称和对应关系,因此我们可以简单的将其转化为RDF或其他形式的知识库内容。一种常用的W3C推荐的映射语言及工具是R2RML(RDB2RDF)。
半结构化数据是指类似于百科、web商品列表等那种本身存在一定结构但需要进一步提取整理的数据。需要首先通过爬虫程序爬取网页内容,然后使用正则表达式的方式写出XPath和CSS选择器表达式来提取网页中的元素。但这样的通用性很差,也有一些自动抽取的办法,比如先对网页进行聚类,然后对每个聚簇生成一个包装器模板。
下面重点介绍非结构化数据的知识抽取,主要包括实体抽取、术语抽取、关系抽取、事件抽取、共指消解(指代消解)。下面我们将依次进行讲解。
实体抽取
实体抽取包括实体发现、实体链接。
实体发现:即我们在前面章节讲到的命名实体识别(NER)任务。
实体链接(实体链指):将识别到的实体映射到知识库中的对应实体,过程中需要做实体消歧,即排除有歧义的同名实体。
如“马云出席了2017年云栖大会”,首先实体发现识别出来马云是一个人名,实体链指就会将识别到的马云实体与知识库中的阿里巴巴董事长进行关联。
关系抽取
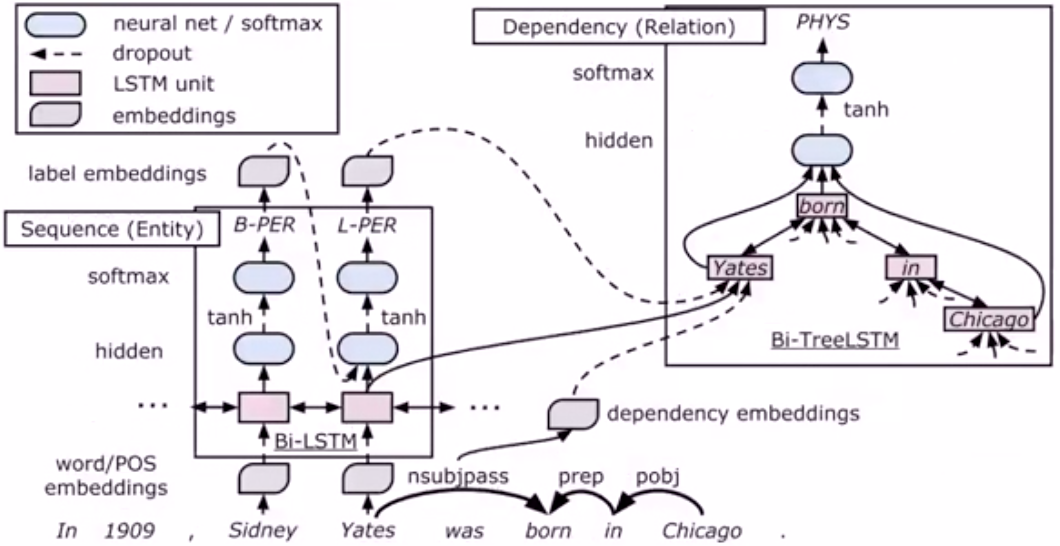 关系抽取:即从语料中发现实体与实体之间的语义关系。如王思聪是万达集团董事长王健林的独子 → [王健林] <父子关系> [王思聪]
关系抽取:即从语料中发现实体与实体之间的语义关系。如王思聪是万达集团董事长王健林的独子 → [王健林] <父子关系> [王思聪]
早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系,近几年以Deep Learning为代表的表示学习技术可以将实体及关系的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合及应用均具有重要的意义。有很多相关论文可以借鉴,最经典的是基于NER和关系抽取的多任务迁移学习模型,如上图所示。
术语抽取
术语抽取:即从语料中发现多个单词组成的相关术语。
事件抽取
 例如从一篇新闻报道中抽取出某事件发生的触发词(event trigger)、时间、地点等信息。
事件其实是一种多元关系,如上图的五元关系(多元关系),其实是4个三元组,每个三元组的主语都是触发词这个事件,谓语分别是时间、地点、攻击者、伤亡人数(又叫做slot,槽),宾语分别是抽取出来的值。
例如从一篇新闻报道中抽取出某事件发生的触发词(event trigger)、时间、地点等信息。
事件其实是一种多元关系,如上图的五元关系(多元关系),其实是4个三元组,每个三元组的主语都是触发词这个事件,谓语分别是时间、地点、攻击者、伤亡人数(又叫做slot,槽),宾语分别是抽取出来的值。
共指消解
 共指消解(Co-reference Resolution,CR),即弄清楚在一句话中的代词的指代对象。
共指消解(Co-reference Resolution,CR),即弄清楚在一句话中的代词的指代对象。
知识融合
知识融合,即合并两个知识图谱(本体),基本的问题都是研究怎样将来自多个来源的关于同一个实体或概念的描述信息融合起来。由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以需要进行知识的融合。知识融合是高层次的知识组织,使来自不同的知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。
不同知识图谱间的实体对齐是KG融合的主要工作。在不同文献中,知识融合有不同的叫法,如本体对齐、本体匹配、Record Linkage、Entity Resolution、实体对齐等。知识融合的主要技术挑战为两点:
- 数据质量的挑战:如命名模糊、数据输入错误、数据丢失、数据格式不一致、缩写等。
- 数据规模的挑战:数据量大(并行计算)、数据种类多样性、多种关系、更多链接、不能仅仅通过名字匹配。
实体对齐必然涉及到实体相似度的计算,假设两个实体的记录x和y,x和y在第i个属性上的值是xi,yi,那么需要通过两步计算:
- 属性相似度:综合单个属性相似度得到属性相似度向量[sim(x1,y1),sim(x2,y2),…,sim(xN,yN)]。
- 实体相似度:根据属性相似度向量得到实体的相似度。
属性相似度的计算有多种方法,常用的有编辑距离、集合相似度(Jaccard系数、Dice)、向量相似度(余弦相似度、欧氏距离)等。
实体相似度的计算有多种方法,比如聚合、聚类、表示学习等。
- 聚合。可以通过对属性相似度向量进行加权平均(w1∗sim(x1,y1)+…+wN∗sim(xN,yN))得到实体相似度,或者通过手动制定规则的方式(sim(x1,y1)>T1 and(or)…sim(xN,yN)>Ti)。
- 聚类。即先将实体聚类成簇,然后计算簇类实体之间的相似度,而不用两两计算相似度。
- 分类。人工标注一批实体match or not的训练数据,然后训练二分类模型。
- 表示学习。利用TransE模型将知识图谱中的实体和关系都映射到低维稠密空间向量,然后计算实体相似度。
TransE
正如NLP中通过Word embedding做词嵌入,知识图谱中通过TransE模型进行知识嵌入。TransE基于实体和关系的分布式向量表示,将每个三元组实例(head,relation,tail)中的关系relation看做从实体head到实体tail的翻译,通过不断调整h、r和t(head、relation和tail的embedding向量),使h + r = t,即最小化损失函数||h+r-t||,可以通过随机梯度下降进行训练。
那么怎样将两个知识图谱嵌入到同一向量空间中呢?必须通过预链接实体对(训练数据)。即将两个KG的三元组糅合在一起共同训练,并将预链接实体对视为具有SameAS关系的三元组,从而对两个KG的空间进行约束。
社群
- 微信公众号
