知识存储
知识图谱的知识(数据)通常存储在图数据库中,图数据库的基本含义是以“图”这种数据结构存储和查询数据。它的数据模型主要是以节点和关系(边)来体现,也可以处理键值对。它的优点是能快速解决复杂的关系问题。
图数据库的种类很多,其中开源的如Apache Jena、RDF4j、gStore等,商业数据库如Virtuoso、AllegroGraph、Stardog等,原生图数据库如Neo4j、OrientDB、Titan等。
Jena
Apache Jena是一个免费开源的支持构建语义网络和数据连接应用(知识图谱)的Java框架,其架构如下:
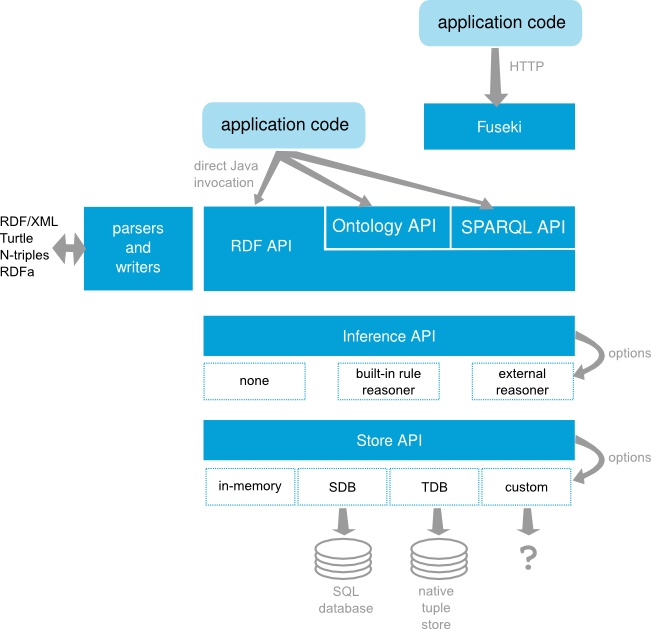 其中,从下往上分别是知识存储层、知识推理层、知识表示层。最上方有一个Fuseki模块,它相当于Apache Jena的客户端,我们的很多操作都是在它提供的各种工具和接口上进行的。
其中,从下往上分别是知识存储层、知识推理层、知识表示层。最上方有一个Fuseki模块,它相当于Apache Jena的客户端,我们的很多操作都是在它提供的各种工具和接口上进行的。
Neo4j
Neo4j是一个高性能的NOSQL图形数据库,直接将数据存储在网络(图)中,并且是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎。
 Neo4j具有以下特性:
Neo4j具有以下特性:
- 支持Lucene索引
- 支持属性图:图中包含两种基本数据类型——节点和边,所有的节点和边都可以定义它上面的属性,不同节点之间通过关系(边)进行关联形成关系型网络结构,节点和边的属性通过key-value表示和存储,这样边(关系)跟节点(实体)一样,都是一等公民。
- 支持ACID
- 高可用性
Jena构建知识图谱实例
下面通过一个构建音乐知识图谱的示例,并结合Apache Jena来具体给大家讲解。
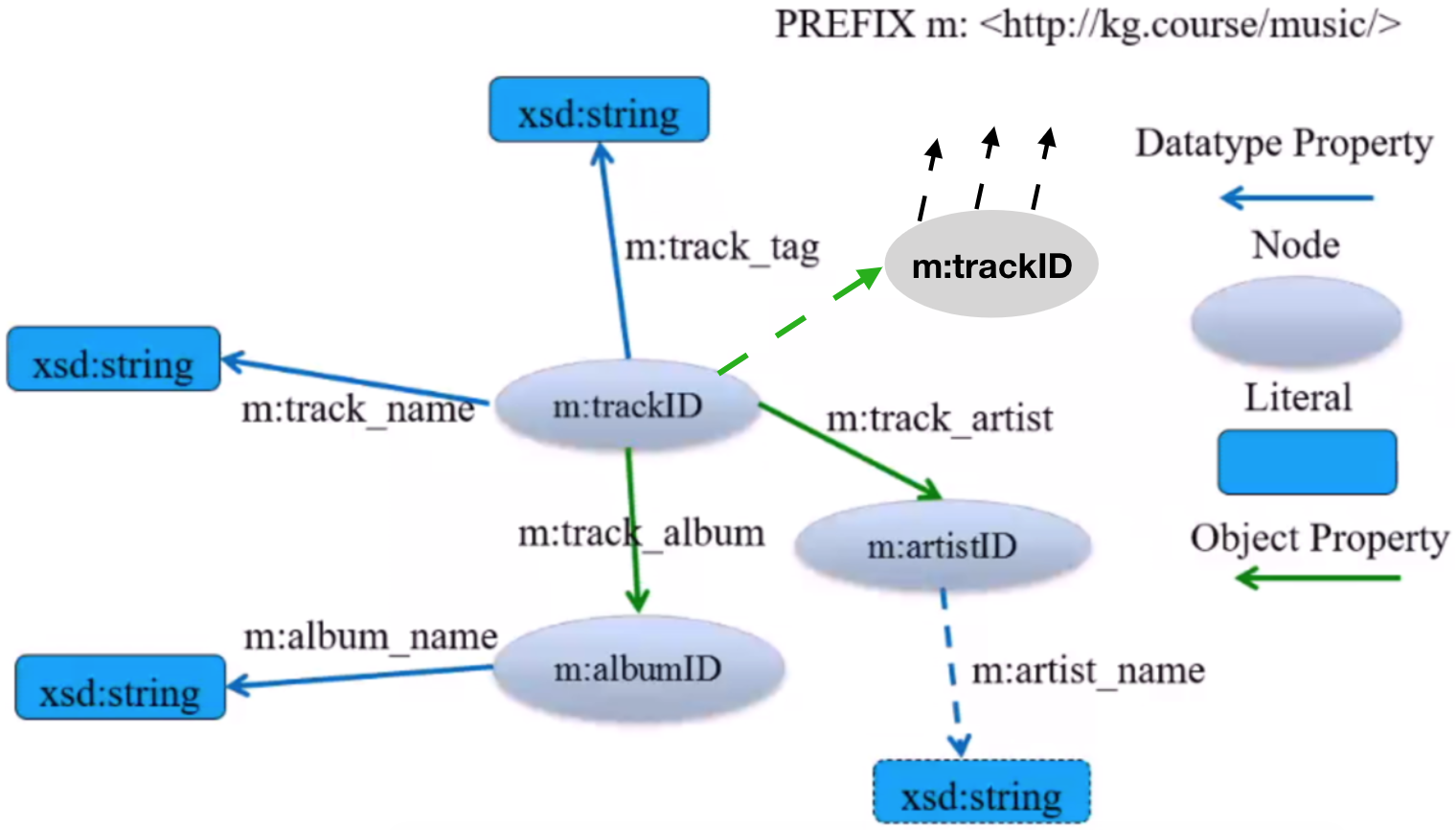 track是歌曲,歌曲与歌曲之间通过某种关系进行关联,进而将所有音乐实体组织成这种网状结构,虚线表示可以动态添加的内容,更加说明了知识图谱是一种schemaless的数据组织形式。
track是歌曲,歌曲与歌曲之间通过某种关系进行关联,进而将所有音乐实体组织成这种网状结构,虚线表示可以动态添加的内容,更加说明了知识图谱是一种schemaless的数据组织形式。
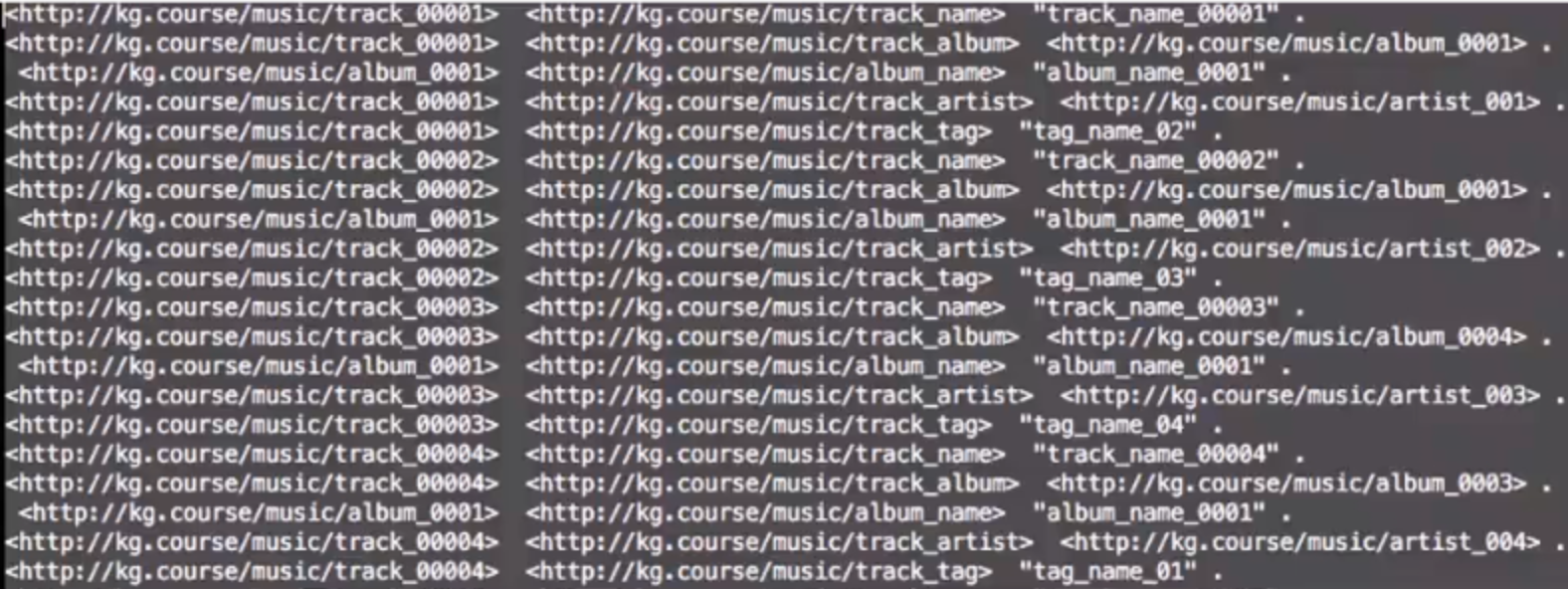 数据以RDF三元组的形式进行导入和底层存储,属性和关系都通过三元组的形式组织(区别于Neo4j)。
数据以RDF三元组的形式进行导入和底层存储,属性和关系都通过三元组的形式组织(区别于Neo4j)。
- 数据导入:
/jena-fuseki/tdbloader --loc=/jena-fuseki/data filenamefilename为上图中的三元组文件路径。
- 启动Fuseki服务:
/jena-fuseki/fuseki-server --loc=/jena-fuseki/data --update /musicmusic为图数据库name。启动后,服务会监听本地的3030端口。
- 数据CRUD操作:数据的增删改查有两种方式,一种是直接通过Fuseki界面执行(http://localhost:3030):
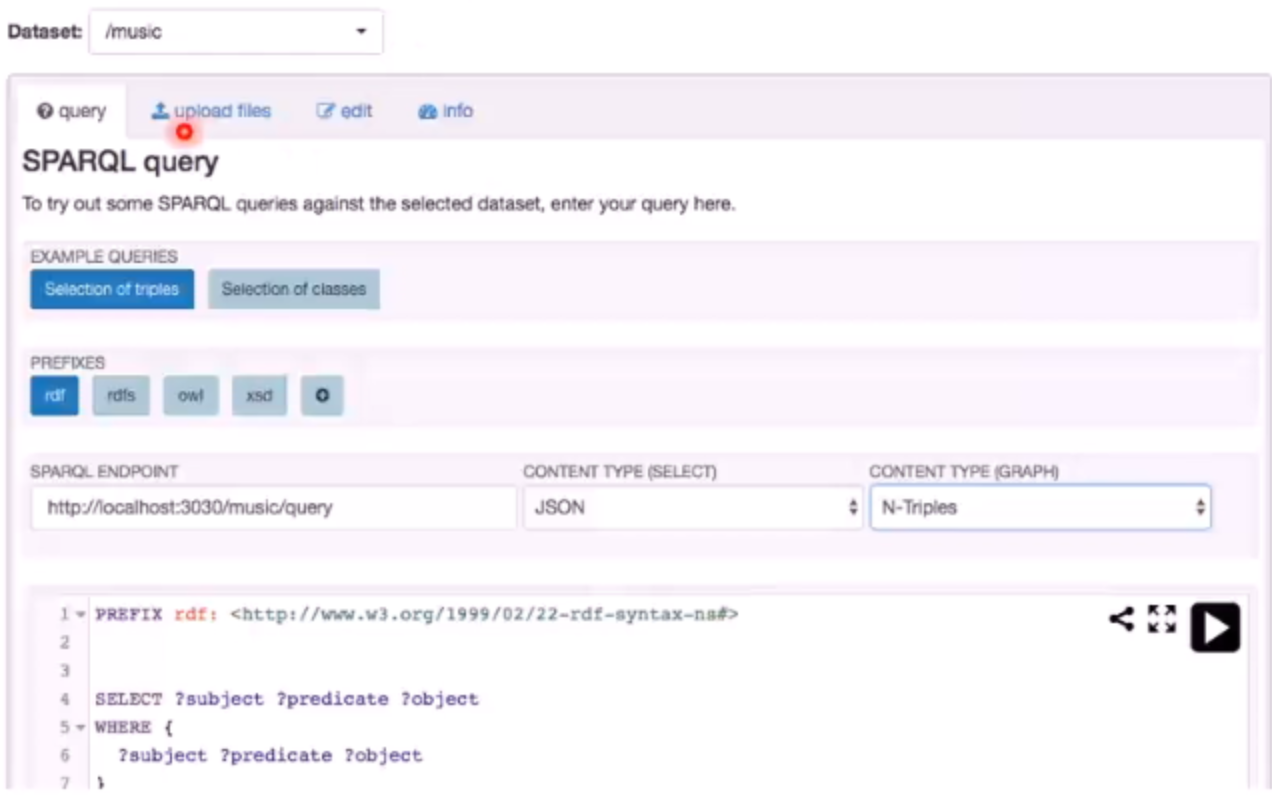 另一种是使用endpoint接口执行:
另一种是使用endpoint接口执行:
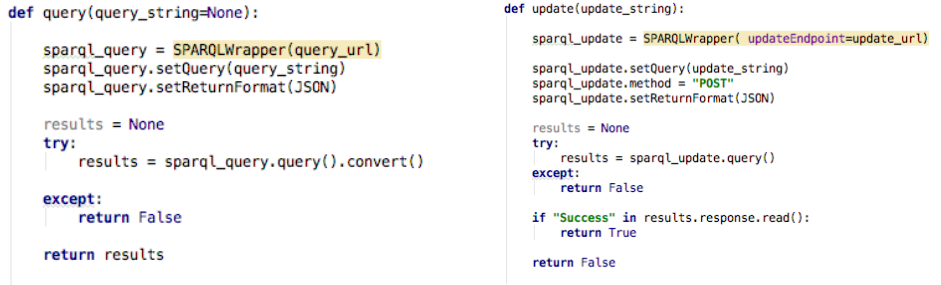 query_url:http://localhost:3030/music/query,update_url:http://localhost:3030/music/update。(需要先通过pip安装SPARQLWrapper)
对于更多的SPARQL和Jena用法请参见官方文档。
query_url:http://localhost:3030/music/query,update_url:http://localhost:3030/music/update。(需要先通过pip安装SPARQLWrapper)
对于更多的SPARQL和Jena用法请参见官方文档。
知识推理
上一节讲到的知识查询,就是利用图结构进行语义查询,其核心是一个子图匹配的过程,可能还会用到图计算(PageRank、最短路径等)和图挖掘的技术(Apache Giraph、Spark GraphX),这些其实都是浅层次的知识推理。
所谓推理就是通过各种方法获取新的知识或者结论,这些知识和结论满足语义。知识推理就是在已有的知识库的基础上,进一步挖掘隐含的知识,从而丰富、扩展知识库。
知识推理的常用方法有基于Tableaux运算的方法、基于逻辑编程改写的方法、基于一阶查询重写的方法、基于产生式规则的方法等。
基于Tableaux运算适用于检查某一本体的可满足性(TRUE or FALSE),以及实例检测。
 可以得出Allen不在Woman的结论。
可以得出Allen不在Woman的结论。
本体推理具有一定的局限性,如仅支持预定义的本体公理上的推理,无法针对自定义的词汇支持灵活推理,用户无法定义自己的推理过程等。因此引入规则推理,它可以根据特定的场景定制规则,以实现用户自定义的推理过程。
这里引入Datalog语言,它可以结合本体推理和规则推理。
基于逻辑编程改写的方法可以根据特定的场景定制规则,以实现用户自定义的推理过程。

基于一阶查询重写的方法可以高效的结合不同数据格式的数据源,重写方法关联起了不同的查询语言,以Datalog语言为中间语言,首先重写SPARQL语言为Datalog,再将Datalog重写为SQL查询。上一节讲到的知识查询其实就是这种方式。
基于产生式规则的方法是一种前向推理系统,可以按照一定机制执行规则从而达到某些目标。通常被应用于自动规划、专家系统上。 产生式系统由事实集合(Working Memory)、产生式/规则集合、推理引擎组成。
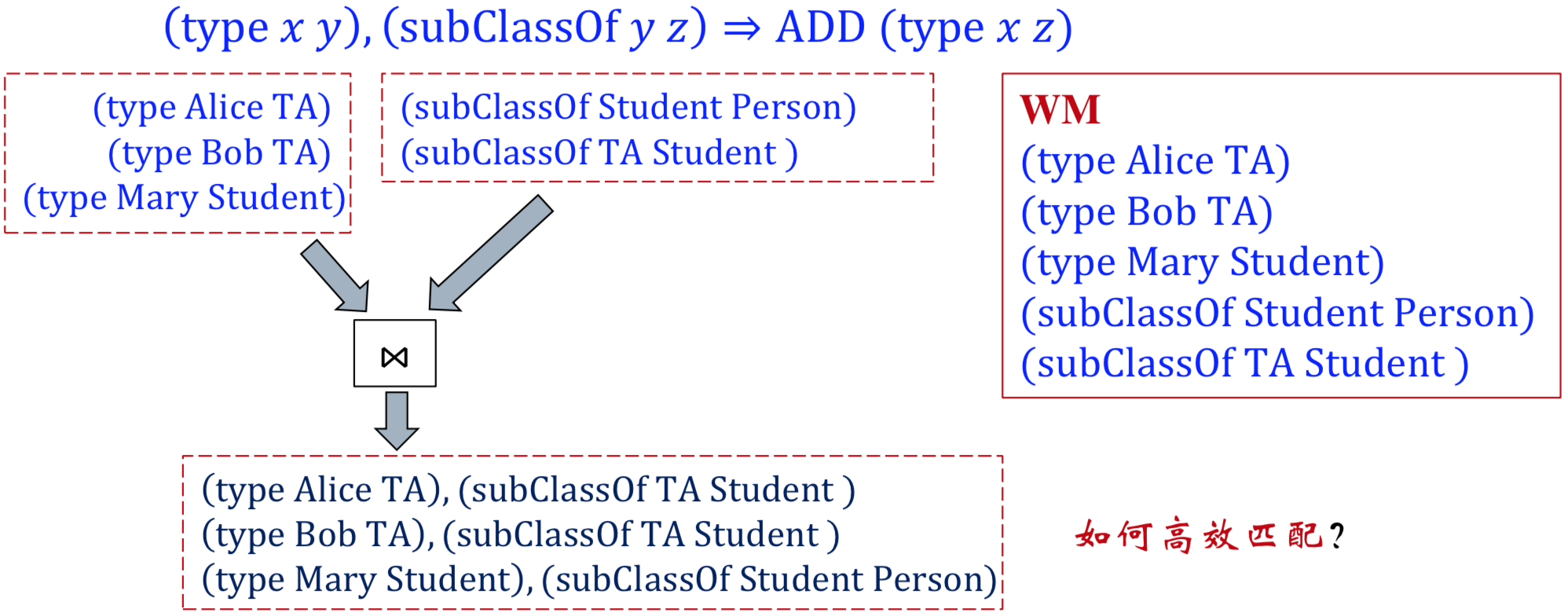
- 事实集合(Working Memory,WM): 是事实的集合,用于存储当前系统中所有事实。事实(Working Memory Element, WME),包含描述对象和描述关系,描述对象例如(student name: Alice age: 24),描述关系(Refication)例如(olderThan John Alice)。
- 产生式集合(Production Memory, PM):是类似于conditions => actions这样的语句。其中conditions是由条件组成的集合,又称为LHS,条件之间是且的关系,即当LHS中所有条件均被满足,则该规则才被触发;actions 是由动作组成的序列,又称为RHS,动作是依次执行的。举个例子: (Student name:x ) => ADD (Person name:x ),表示student是一个person。推理规则也可以通过无监督学习的手段进行挖掘,主要还是依赖于实体以及关系间的丰富同现情况。
- 推理引擎:它可以控制系统的执行,包含模式匹配(即用规则的条件部分匹配事实集中的事实,整个LHS都被满足的规则对应的action被触发,并被加入议程agenda)、解决冲突(按一定的策略从被触发的多条规则中选择一条)、执行动作(执行被选择出来的规则的RHS,从而对WM进行一定的操作)。
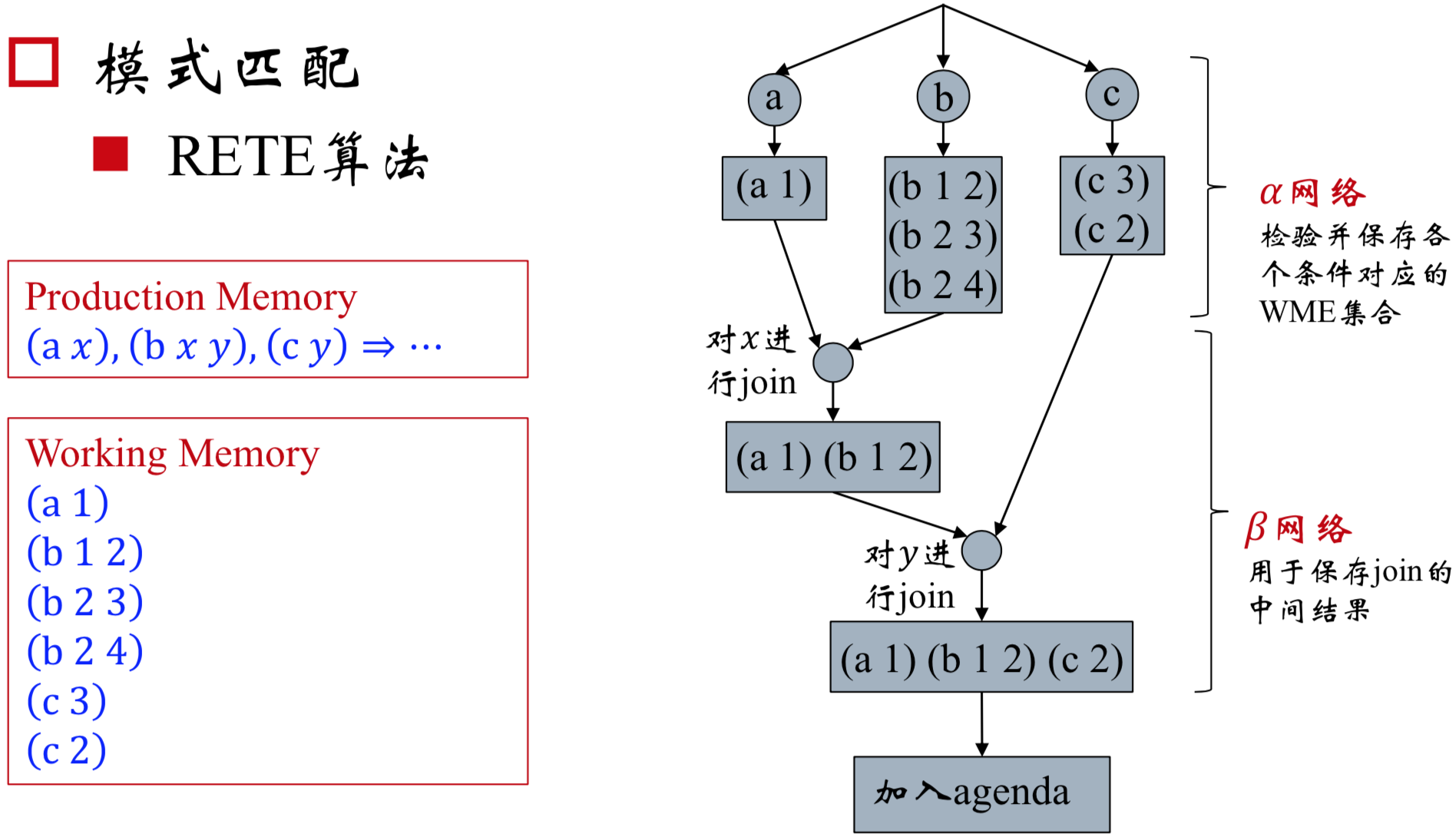
 一种高效的模式匹配算法是RETE算法:
一种高效的模式匹配算法是RETE算法:
 基于产生式规则的开源工具和框架有Drools、Jena、RDF4J等。
基于产生式规则的开源工具和框架有Drools、Jena、RDF4J等。
社群
- 微信公众号
