身份证识别
身份证识别的方法有很多,最常用的方式是三步走:第一步图像预处理,第二步文字分割,第三步文字识别。

- 图像预处理。因为所有文字都是黑色的,所以先split图片的RGB通道,留下黑色通道,这样基本上所有背景都被去掉了,然后再把头像部分也去除。
boundary = ([0, 0, 0], [100, 100, 100]) preprocess_bg_mask = PreprocessBackgroundMask(boundary) left_half_id_card_img_mask=np.copy(id_card_img_mask) left_half_id_card_img_mask[:,norm_width/2:]=0 - 文字分割。还是用上节同样的方法,往左投影求和找到文本行,然后每一行进行垂直投影,找到每一个字。
for line_range in line_ranges: start_y, end_y = line_range end_y += 1 line_img = id_card_img_mask[start_y: end_y] vertical_sum = np.sum(line_img, axis=0) vertical_peek_ranges = extract_peek_ranges_from_array(vertical_sum, minimun_val=40, minimun_range=1) vertical_peek_ranges2d.append(vertical_peek_ranges)
- 文字识别。文字识别可以直接调用上一讲训练好的OCR字符识别模型。
上述是身份证识别的最常用的方法,这种方式对身份证、护照等格式简单且固定的场景特别有效,但是一旦场景变得复杂,比如海关单证、收据等的关键信息提取,文本行提取的难度就会显著加大,甚至变得不可行,这时更通用的解决方案是基于自定义模板的方式。
基于自定义模板的OCR
只要表格类的样式较为固定,就可以针对性的制作出相应的模板,然后导入样本图片实现结构化的数据提取。
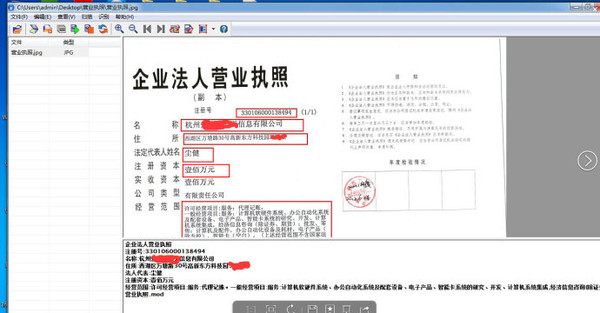 其实现原理其实非常简单,主要分为以下几步。
其实现原理其实非常简单,主要分为以下几步。
- 上传一张待识别的特定的一类具有固定格式的文档的图片作为模板,在模板上框选一些固定不变的文字段作为【参照点】。
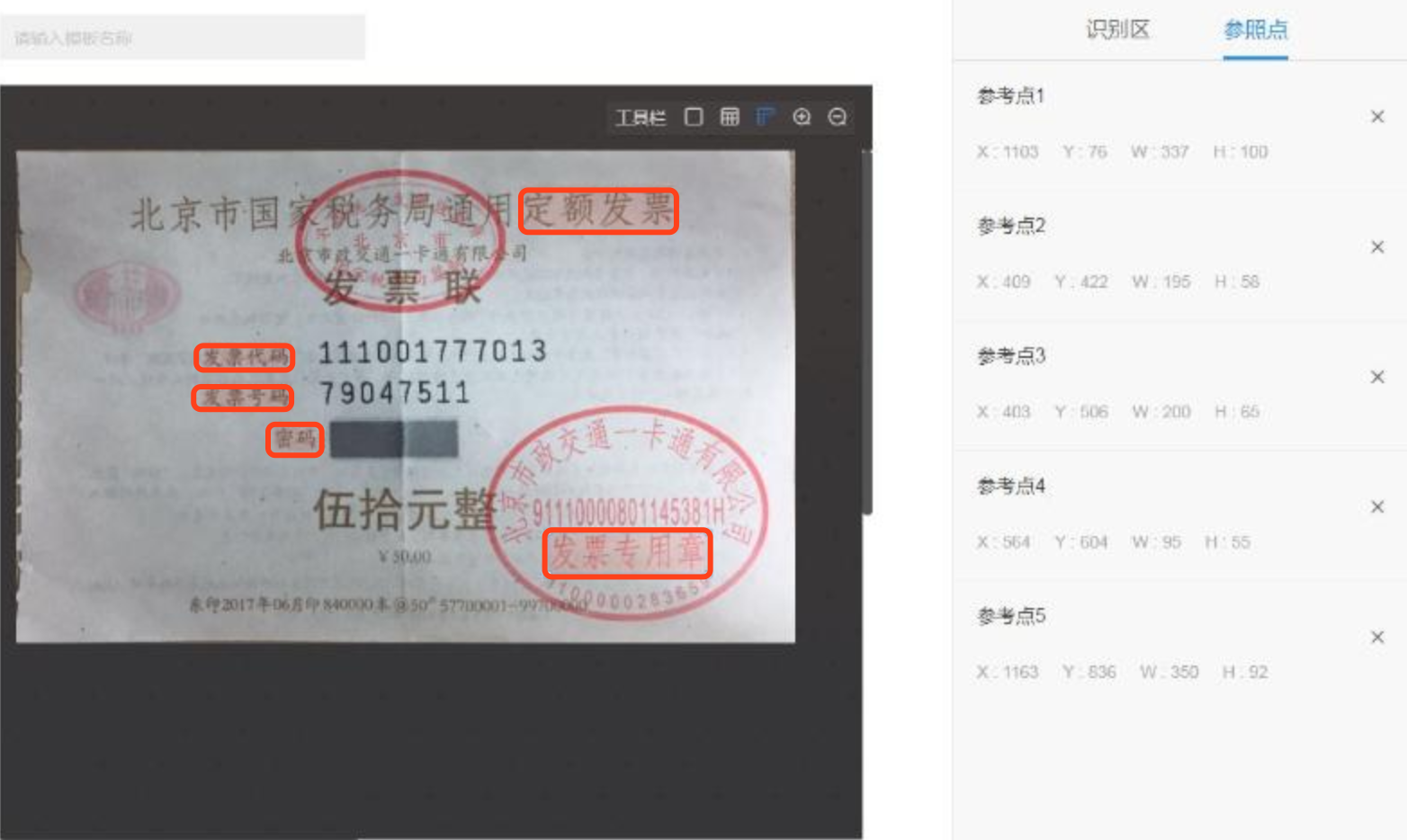 后续调用识别接口时,会将新上传的图片以【参照点】为依据,扭正到和模板图片一致,扭正方法也很简单,根据N个参考点求对应的透视变换,校正到统一的坐标维度。
后续调用识别接口时,会将新上传的图片以【参照点】为依据,扭正到和模板图片一致,扭正方法也很简单,根据N个参考点求对应的透视变换,校正到统一的坐标维度。 - 框选【识别区】,并映射每个字段对应的字段名。
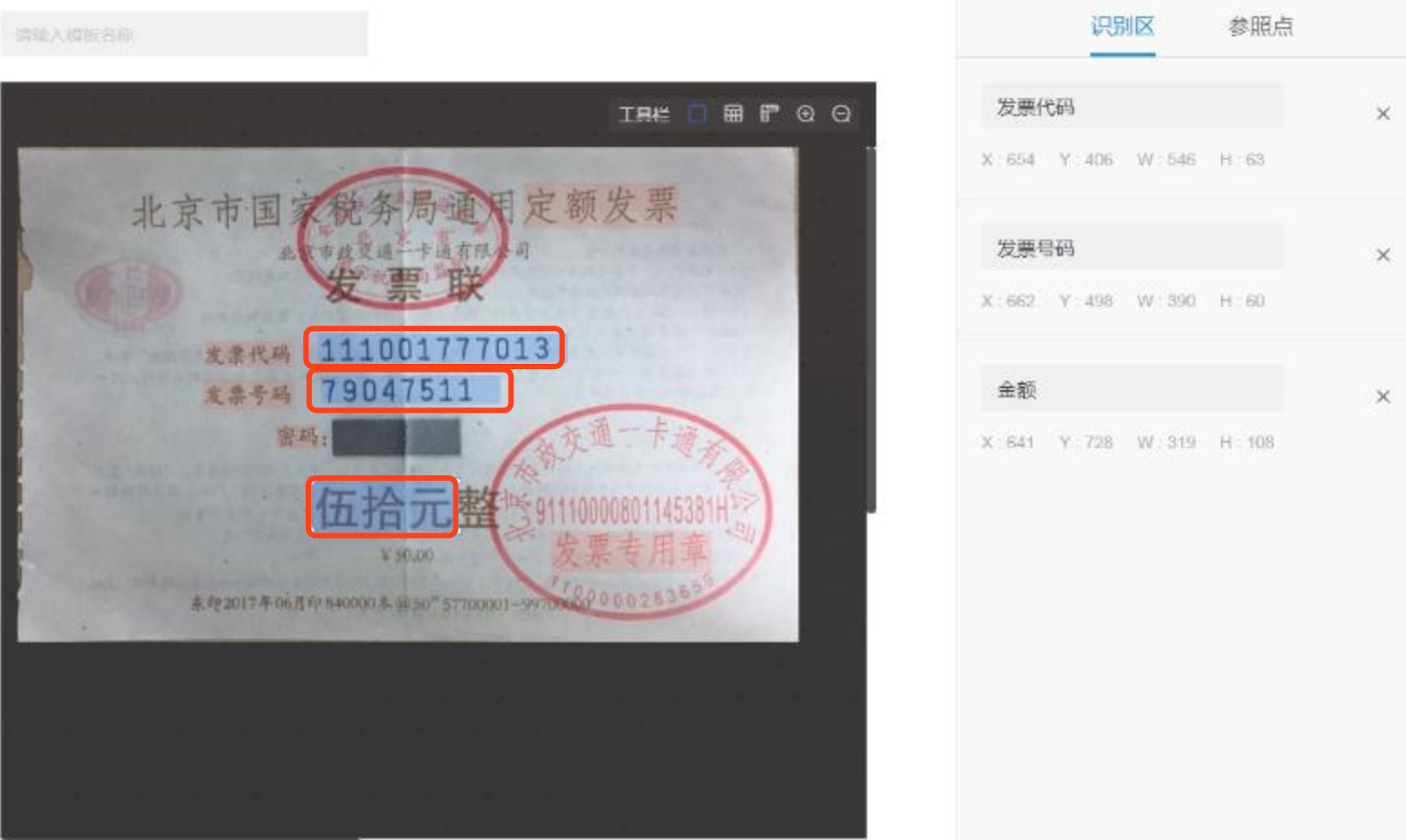 将扭正后的图片和识别区通过图像mask的方式提取目标文本行。
将扭正后的图片和识别区通过图像mask的方式提取目标文本行。 - 通过上述方法就可以很容易的提取到目标文本行,然后再通过同样的方式进行文字分割和文字识别。
社群
- 微信公众号
