到目前为止,我们进行OCR的思路都非常暴力,大概都是这样:提取目标文本(去噪+二值化、自定义模板)-> 文字分割 -> 字符识别。
相对而言,第2步字符分割难度最大,而且最重要,原因有以下几点:
- 因为现实生活中字符粘连是很常见的问题,一旦字符粘连,文字分割效果就会急剧下降。
- 文字分割的错误会传播到字符识别阶段,从而直接影响字符识别的准确率。
- 语义修正只能缓解部分问题,而不能从根本上解决问题。
所以我们能不能跳过文字分割,直接提取到目标文本,然后通过深度学习做端到端的学习,而识别出目标字符呢?答案是肯定的,我们先一步步来。
固定长度:multi-label classification
对于定长的文字序列,比如验证码(4位数字),身份证(18位数字),这其实是一个multi-label的分类问题,解法还是非常简单而且直观的,直接将multi-label的所有one-hot向量拼接起来作为最终的label,然后构建普通的图片分类模型即可。比如对于4位数字验证码而言,转换后的最终label长度为10 * 4 = 40,如下所示: 1834 -> 0100000000|0000000010|0001000000|0000100000。network structure如下:
keep_prob = tf.placeholder(dtype=tf.float32, shape=[], name='keep_prob')
images = tf.placeholder(dtype=tf.float32, shape=[None, 64, 64, 1], name='image_batch')
labels = tf.placeholder(dtype=tf.int64, shape=[None], name='label_batch')
is_training = tf.placeholder(dtype=tf.bool, shape=[], name='train_flag')
conv3_1 = slim.conv2d(images, 64, [3, 3], 1, padding='SAME', scope='conv3_1')
max_pool_1 = slim.max_pool2d(conv3_1, [2, 2], [2, 2], padding='SAME', scope='pool1')
conv3_2 = slim.conv2d(max_pool_1, 128, [3, 3], padding='SAME', scope='conv3_2')
max_pool_2 = slim.max_pool2d(conv3_2, [2, 2], [2, 2], padding='SAME', scope='pool2')
conv3_3 = slim.conv2d(max_pool_2, 256, [3, 3], padding='SAME', scope='conv3_3')
max_pool_3 = slim.max_pool2d(conv3_3, [2, 2], [2, 2], padding='SAME', scope='pool3')
conv3_4 = slim.conv2d(max_pool_3, 512, [3, 3], padding='SAME', scope='conv3_4')
conv3_5 = slim.conv2d(conv3_4, 512, [3, 3], padding='SAME', scope='conv3_5')
max_pool_4 = slim.max_pool2d(conv3_5, [2, 2], [2, 2], padding='SAME', scope='pool4')
flatten = slim.flatten(max_pool_4)
fc1 = slim.fully_connected(slim.dropout(flatten, keep_prob), 1024, activation_fn=tf.nn.relu, scope='fc1')
# multi-label-size即为转换后的one-hot label总长度,4位数字验证码就是40
logits = slim.fully_connected(slim.dropout(fc1, keep_prob), FLAGS.multi-label-size, activation_fn=None, scope='fc2')
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))
optimizer = tf.train.AdamOptimizer(learning_rate=0.001)
train_op = slim.learning.create_train_op(loss, optimizer)
这种固定长度的模型只能解决某类问题,并不通用,对于长度不固定的字符识别问题就无能为力了,为了解决此类问题,一般采用RNN + CTC loss的方式,下面我们先来介绍什么是CTC loss。
不定长度:端到端OCR
CTC(Connectionist Temporal Classifier,联结主义时间分类器),适合于输入特征和输出标签之间对齐关系不确定的时间序列问题,CTC可以自动端到端地同时优化模型参数和对齐切分的边界。
回忆下我们之前讲过的基于RNN + CRF的命名实体识别章节,如果抛开CRF,直接基于RNN也可以完成NER任务,这个时候所用到的loss就是CTC loss,只不过当时我们没有做过多展开。CRF的作用只不过是加入了状态转移概率矩阵,将状态转移得分也加入到CTC loss中一起做优化。如果状态转移score对于最终任务不太敏感,且可用状态过多导致状态转移矩阵过大,可以考虑不加CRF loss,而直接用CTC loss,例如我们正在讲的端到端OCR任务以及语音识别任务等。
再回忆一下我们前面所讲的机器翻译的seq2seq模型,也是解决输入和输出之间对齐关系不确定的时间序列问题。seq2seq模型有两个独立的RNN网络,encoder是一个,deocder是另一个,encoder RNN将输入编码为一个向量的representation,decoder RNN基于这个中间向量表示进行解码,并通过
RNN+CTC被广泛的用在语音识别领域把音频解码成汉字,模型结构如下图所示,语音识别我们在后面的课程中会详细讲到。
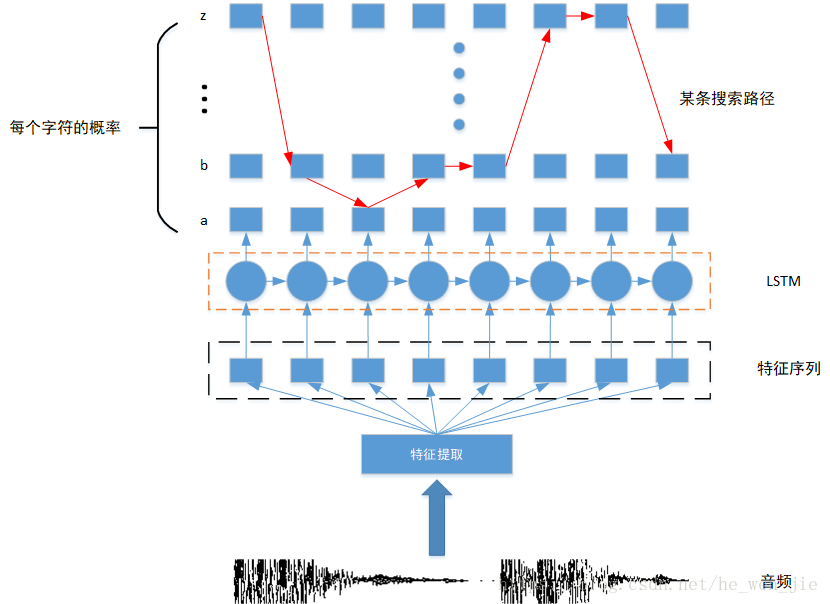 最上面得到每个字符的概率得分后,与target的每个time step计算cross_entropy loss(注意要先做mask以剔除Padding或无用的输出),然后将所有loss直接相加或相乘就得到了CTC loss。
最上面得到每个字符的概率得分后,与target的每个time step计算cross_entropy loss(注意要先做mask以剔除Padding或无用的输出),然后将所有loss直接相加或相乘就得到了CTC loss。
端到端OCR其实就是把图片解码成汉字,和语音识别并没有太本质的区别,所以完全可以复用上图所示的模型。 假设待识别的图片size是80x30,里面是一个长度为k的数字验证码,那么我们可以沿着x轴对图片进行切分,比如切成80个time step,即把图片的每一列都作为LSTM的输入,每个time step的输入特征维度为30,LSTM有80个输入就会有80个输出,而这80个输出可以通过CTC loss计算和k个验证码标签之间的Loss。
inputs = tf.placeholder(tf.float32, [None, 80, 30) # (batch_size, time_steps, feature_size)
targets = tf.sparse_placeholder(tf.int32) # 稀疏矩阵
seq_len = tf.placeholder(tf.int32, [None])
# network structure
cell = tf.contrib.rnn.LSTMCell(num_hidden, state_is_tuple=True)
stack = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple=True)
outputs, _ = tf.nn.dynamic_rnn(cell, inputs, seq_len, dtype=tf.float32)
# 线性变换
logits = tf.layers.dense(outputs, num_classes, activation=None) # (batch_size, time_steps, num_classes)
# 模型训练
loss = tf.nn.ctc_loss(labels=targets, inputs=logits, sequence_length=seq_len)
cost = tf.reduce_mean(loss)
optimizer = tf.train.AdamOptimizer().minimize(loss)
# 预测或测试时用到
decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len) # beam_search
# tf.nn.ctc_greedy_decoder(logits, seq_len) # greedy
acc = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets))
有几点需要解释的是:
- num_classes表示num_labels+1个类,其中num_labels是真实标签的数量,最大值(num_classes-1)是为预留无意义输出标签(blank)保留的。例如对于包含3个标签[a,b,c]的词汇表,num_classes = 4,标签索引为{a:0,b:1,c:2,blank:3}。
- labels,这是一个SparseTensor,需要先将原始标签改为稀疏张量,如a=[[1,2,3],[4],[5,6,7],[9,8]],[5,6,7]的位置信息就是(2,0),(2,1),(2,2)。SparseTensor的意义在于可以免去Padding(因为tf.placeholder要求每一个batch输入都是同样的shape)。
- sequence_length,不定长文字序列的长度,用来对logits输出做mask。
- preprocess_collapse_repeated=False,将连续的重复的labels合并为一个。
- ctc_merge_repeated=True,将连续的重复的logits合并为一个。
注意:
- 在计算ctc_loss时,不会剔除无意义的blank输出,而是对连续的重复的logits做merge。
- 线上预测时,记住Replacing blank label to none。
参看文献:CTC tensorflow example 代码解析
社群
- 微信公众号
