记于加州斯坦福大学校内。
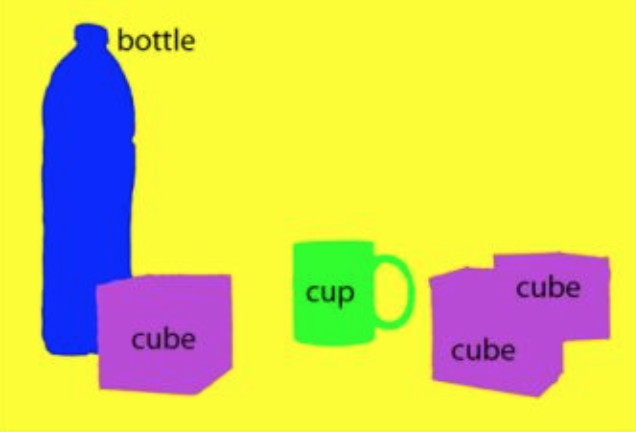
语义分割(semantic segmentation),是目标检测更进阶的任务,目标检测只需要框出每个目标的包围盒,语义分割需要进一步判断图像中哪些像素属于哪个目标,比如说下图,经过语义分割之后的图片就是一个包含若干种颜色的图片,其中每一种颜色都代表一类物体。
 解决语义分割任务的经典网络模型有很多,比如FCN、U-Net、Mask RCNN等。现在的深度学习语义分割模型基本上都是基于FCN发展而来的,它是开山鼻祖,尽管现在有很多方法都超越了FCN,但它的思想仍然有很重要的意义。U-net是基于FCN的一种非常流行非常优雅的语义分割模型。本文将重点介绍这两种模型。
解决语义分割任务的经典网络模型有很多,比如FCN、U-Net、Mask RCNN等。现在的深度学习语义分割模型基本上都是基于FCN发展而来的,它是开山鼻祖,尽管现在有很多方法都超越了FCN,但它的思想仍然有很重要的意义。U-net是基于FCN的一种非常流行非常优雅的语义分割模型。本文将重点介绍这两种模型。
FCN
FCN(Fully Convolutional Network,全卷积网络)主要使用了三种技术:卷积化(Convolutional)、上采样(Upsample)、跳跃结构(Skip Layer)。
卷积化
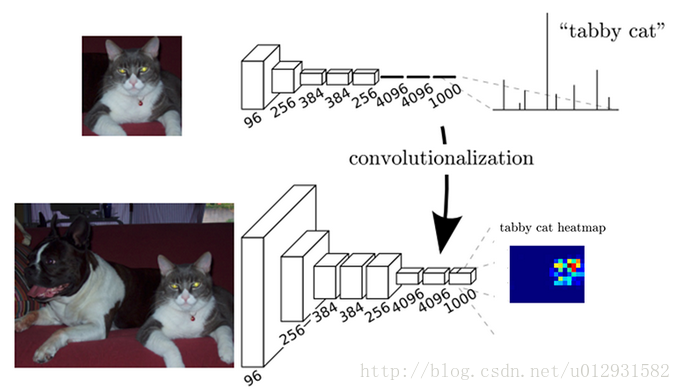 上图中上面的图最后一层是一个输出为1x1000向量的全连接层,因为一共有1000个类,向量的每一维都代表了属于某一类的概率,其中tabby cat的概率是最大的。而经过全卷积化后,没有了全连接层,取而代之的是卷积层,最后一层输出的是1000个二维数组,其中每一个二维数组可以可视化成为一张图像(该图像大小就是原始图像的单通道大小),该图像中的每一个像素点的灰度值都是代表当前像素点属于该类的概率,比如在这1000张图像中,取出其中代表tabby cat的那一张,颜色从蓝到红,越红则代表当前像素点属于tabby cat类的概率就越大。可以看出FCN与CNN之间的区别就是把最后几层的全连接层换成了卷积层,这样做的好处就是能够进行dense prediction,从而实现对图像进行像素级的分类。
上图中上面的图最后一层是一个输出为1x1000向量的全连接层,因为一共有1000个类,向量的每一维都代表了属于某一类的概率,其中tabby cat的概率是最大的。而经过全卷积化后,没有了全连接层,取而代之的是卷积层,最后一层输出的是1000个二维数组,其中每一个二维数组可以可视化成为一张图像(该图像大小就是原始图像的单通道大小),该图像中的每一个像素点的灰度值都是代表当前像素点属于该类的概率,比如在这1000张图像中,取出其中代表tabby cat的那一张,颜色从蓝到红,越红则代表当前像素点属于tabby cat类的概率就越大。可以看出FCN与CNN之间的区别就是把最后几层的全连接层换成了卷积层,这样做的好处就是能够进行dense prediction,从而实现对图像进行像素级的分类。
上采样
FCN可以接受任意尺寸的输入图像,采用反卷积(deconvolution)对最后一个卷积层的feature map进行连续的上采样,使它恢复到原始输入图像相同的尺寸,从而可以对每个像素都产生一个预测,同时保留了原始输入图像的空间位置信息,最后在上采样的特征图上进行逐像素分类。关于反卷积,我们在CNN章节已进行了详细介绍,这里不再赘述。
跳跃结构
在进行语义分割的时候,需要解决的一个重要问题就是,如何把定位和分类这两个问题结合起来,毕竟语义分割就是进行逐个像素点的分类,就是把where和what两个问题结合在一起进行解决,在前面几层卷积层,分辨率比较高,像素点的定位比较准确,后面几层卷积层,分辨率比较低,像素点的分类比较准确,所以为了更加准确的分割,需要把前面高分辨率的特征和后面的低分辨率特征结合起来。
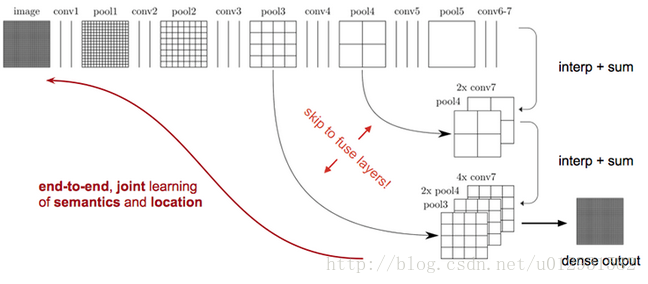 如上图所示,对原图像进行卷积conv1、pool1后尺寸缩小为原图像的1/2;之后对图像进行第二次conv2、pool2后尺寸缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3尺寸缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时进行32倍的上采样可以得到原图大小,这个时候得到的结果就叫做FCN-32s,但是FCN-32s的结果明显非常平滑,不够精细。针对这个问题,作者采用了combining what and where的方法,具体来说,就是把pool4层和conv7的2倍上采样结果相加(sum)之后进行一个16倍的上采样,得到的结果是FCN-16s。最后再把pool3层和2倍上采样的pool4层和4倍上采样的conv7层加起来,进行一个8倍的上采样,得到的结果就是FCN-8s。
如上图所示,对原图像进行卷积conv1、pool1后尺寸缩小为原图像的1/2;之后对图像进行第二次conv2、pool2后尺寸缩小为1/4;接着继续对图像进行第三次卷积操作conv3、pool3尺寸缩小为原图像的1/8,此时保留pool3的featureMap;接着继续对图像进行第四次卷积操作conv4、pool4,缩小为原图像的1/16,保留pool4的featureMap;最后对图像进行第五次卷积操作conv5、pool5,缩小为原图像的1/32,然后把原来CNN操作中的全连接变成卷积操作conv6、conv7,图像的featureMap数量改变但是图像大小依然为原图的1/32,此时进行32倍的上采样可以得到原图大小,这个时候得到的结果就叫做FCN-32s,但是FCN-32s的结果明显非常平滑,不够精细。针对这个问题,作者采用了combining what and where的方法,具体来说,就是把pool4层和conv7的2倍上采样结果相加(sum)之后进行一个16倍的上采样,得到的结果是FCN-16s。最后再把pool3层和2倍上采样的pool4层和4倍上采样的conv7层加起来,进行一个8倍的上采样,得到的结果就是FCN-8s。
 上图从左至右分别是原图、FCN-32s、FCN-16s、FCN-8s,从结果可以很明显的看出:FCN-8s结果好于16s,好于32s的。
上图从左至右分别是原图、FCN-32s、FCN-16s、FCN-8s,从结果可以很明显的看出:FCN-8s结果好于16s,好于32s的。
FCN得到的结果还是不够精细,对图像的细节不够敏感,这是因为在进行decode也就是恢复原图像大小的过程时,输入上采样层的label map太稀疏,而且上采样过程就是一个简单的deconvolution,其次是对各个像素进行分类,没有考虑到像素之间的关,忽略了在通常的基于像素分类的分割方法中使用的空间规整步骤,缺乏空间一致性。
U-net
U-net是基于FCN的一个语义分割网络,下面是U-net的网络结构图:
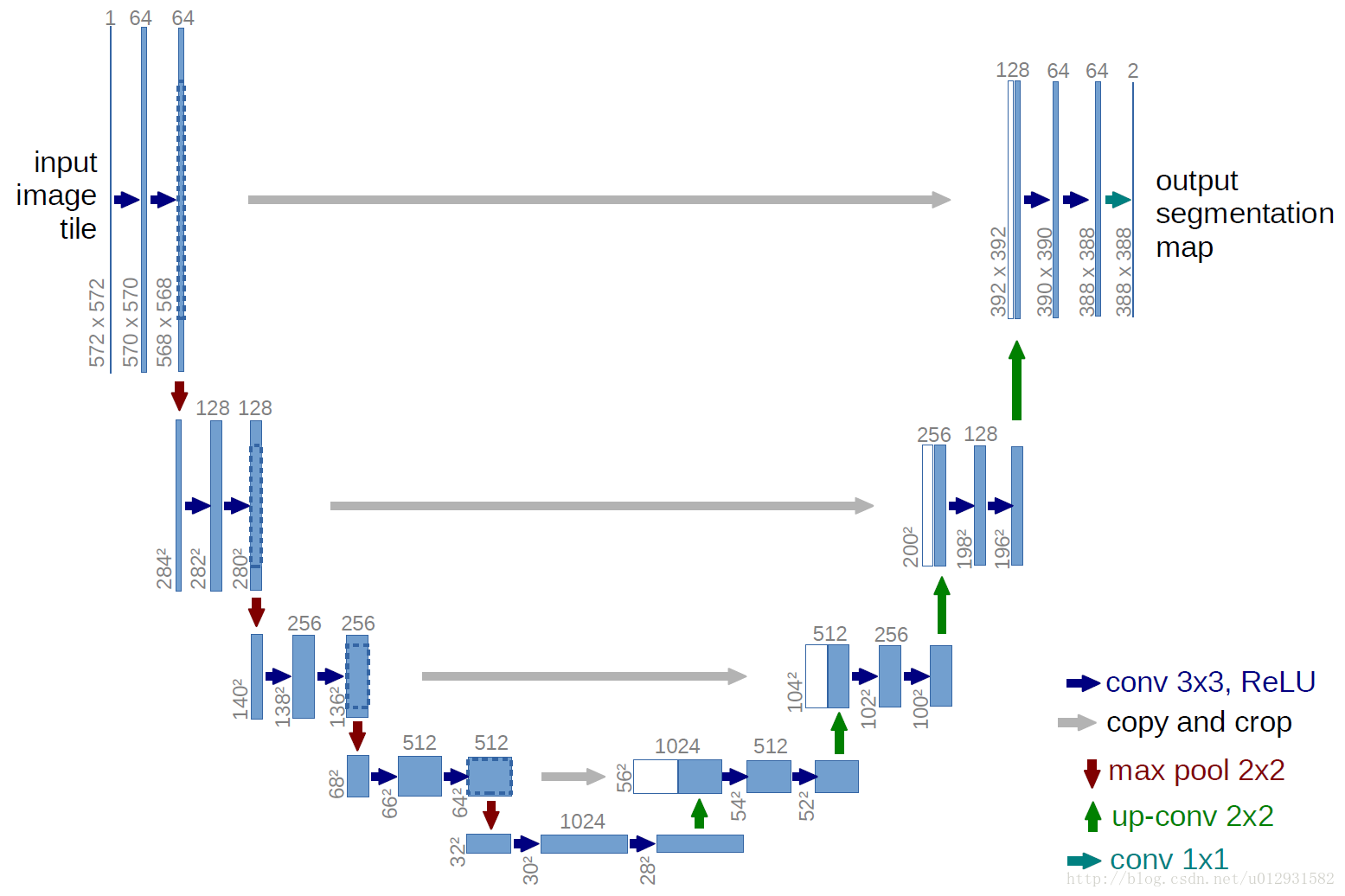 注:U-Net将388x388的原图像执行镜像操作后变成572x572,所以网络最后的输出也是388x388的图片。最终输出是388x388x2,其中的2表示2分类。
注:U-Net将388x388的原图像执行镜像操作后变成572x572,所以网络最后的输出也是388x388的图片。最终输出是388x388x2,其中的2表示2分类。
U-Net网络结构比较清晰,一目了然,也很优雅,成一个U状,设计思想和FCN一样,结构上唯一比较大的改动是在上采样阶段,与FCN逐点相加不同,U-Net采用将特征在channel维度拼接(concat)在一起,形成更“厚”的特征图。
社群
- 微信公众号
