记于加州斯坦福大学校内。
视频分析
视频分析(Video Analysis),视频分析是近几十年来计算机视觉和多媒体领域最根本研究课题之一。这是一个非常具有挑战性的问题,因为通常视频是一个有着有很大的差异性和复杂性的信息密集媒体。由于深度学习技术的发展,计算机视觉和多媒体领域的研究人员现在利用深度学习技术能够大幅度的提高视频分析的性能,并开始在分析视频上开辟了许多新的研究方向。
当前,全世界现在每天有超过50%的人在线看视频,每天在Facebook上会观看37亿个视频,YouTube上每天会观看5亿小时时长的视频。我们做视频,大家首先想到的就是做广告,视频上面的广告每年都是30%的速度递增的,在YouTube上面也是每年30%的增长态势。人们在视频上花的时间是图片上的2.6倍,视频的生成比文字和图片要多1200%。
目前视频分析的领域方向有很多,包括视频分类、动作识别、目标跟踪等,下面我们将依次进行介绍。
视频分类与动作识别
视频分类与动作识别实现原理相似,都是视频分类问题,一般有两种主流实现方法,一种是Hierarchical-CNN-RNN,另一种是3D-CNN。
Hierarchical-CNN-RNN
Hierarchical-CNN-RNN实现原理非常简单直观,因为视频是一帧一帧时序性的图像,所以很自然的想到应该先用CNN提取每一帧图像的特征,得到每张图像的representation,然后将之输入RNN中进行视频分类。模型结构如下所示:
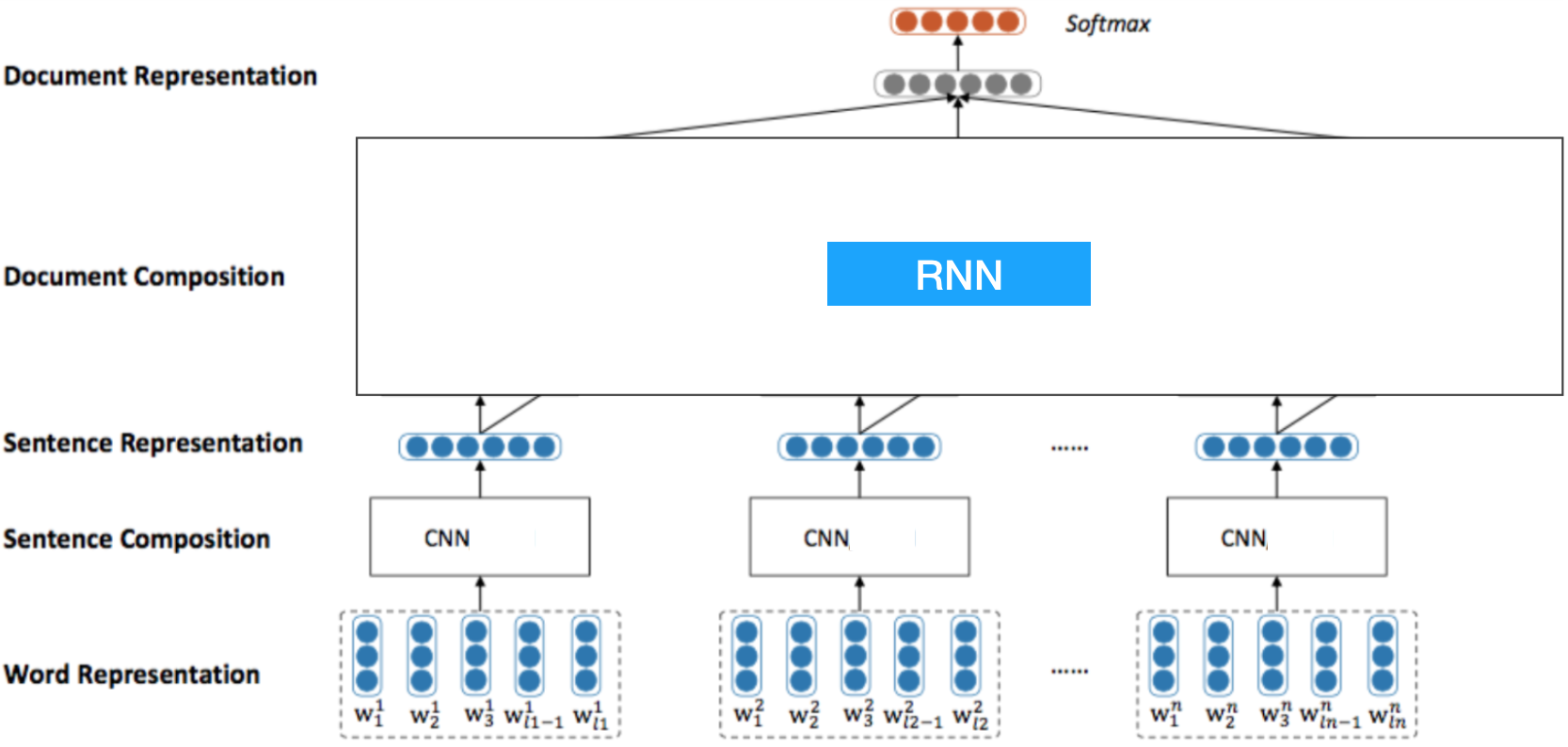 这是我截取的HierarchicalCNN的模型图,原理一模一样,这里的Word相当于每张图像的像素,Sentence相当于每张图像,Document相当于这里的视频。这种简单明了的模型架构存在很明显的效率问题,因此实际并不常用,实际中用到最多的还是3D-CNN架构。
这是我截取的HierarchicalCNN的模型图,原理一模一样,这里的Word相当于每张图像的像素,Sentence相当于每张图像,Document相当于这里的视频。这种简单明了的模型架构存在很明显的效率问题,因此实际并不常用,实际中用到最多的还是3D-CNN架构。
3D-CNN
3D-CNN模型架构也特别简单直观,即通过在2D-CNN(图像卷积)的基础上增加时间这个维度,即将连续帧组成的视频一起作为模型的输入进行卷积操作。比如对三幅连续帧用一个3D卷积核进行卷积,可以理解为用一个3x3x3的cube作为卷积核在一段视频(若干个连续帧)上以滑动窗口的形式移动。如果是彩色图片,还要注意通道数也为3,这时每一帧都是三个通道,即相当于用一个3x3x9的cube作为卷积核在一段视频(若干个连续帧)上以滑动窗口的形式移动。
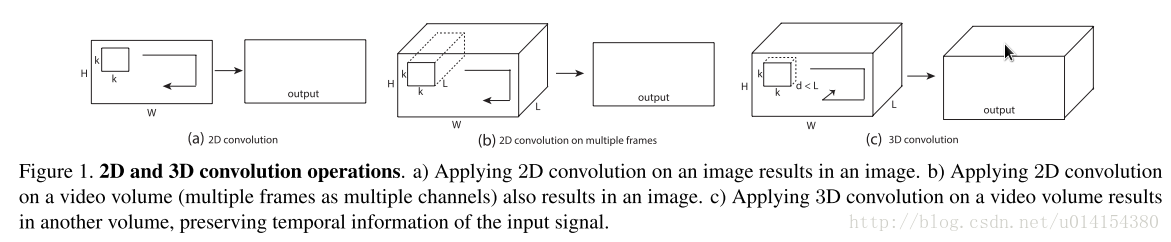 上图中的第一幅图表示使用2D-CNN在一张黑白图像(单通道)上做卷积,结果是一张二维的feature map;第二幅图表示使用2D-CNN在一张彩色图像(3通道)上做卷积,结果仍是2维的;第三幅图表示使用一个kxkxd(d小于l)的卷积核在一段帧数为l的视频上进行3D卷积,结果得到一张3维的feature map。
上图中的第一幅图表示使用2D-CNN在一张黑白图像(单通道)上做卷积,结果是一张二维的feature map;第二幅图表示使用2D-CNN在一张彩色图像(3通道)上做卷积,结果仍是2维的;第三幅图表示使用一个kxkxd(d小于l)的卷积核在一段帧数为l的视频上进行3D卷积,结果得到一张3维的feature map。
由于经过多次3D-CNN卷积操作后,结果依然得到一张3维的feature map,所以需要将其flatten之后输入全连接神经网络完成视频分类任务。
目标跟踪
目标跟踪(Visual Object Tracking),相机的跟踪对焦、无人机的自动目标跟踪等都需要用到目标跟踪技术,这里说的目标跟踪,是通用单目标跟踪,第一帧给个矩形框,这个框在数据库里面是人工标注的,在实际情况下大多是检测算法的结果,然后需要跟踪算法在后续帧紧跟住这个框。
 我们首先看上方给出的3张图片,它们分别是同一个视频的第1,40,80帧。在第1帧给出一个跑步者的边框(bounding-box)之后,后续的第40帧,80帧,bounding-box依然准确圈出了同一个跑步者。以上展示的其实就是目标跟踪(visual object tracking)的过程。目标跟踪(特指单目标跟踪)是指:给出目标在跟踪视频第一帧中的初始状态(如位置,尺寸),自动估计目标物体在后续帧中的状态。
我们首先看上方给出的3张图片,它们分别是同一个视频的第1,40,80帧。在第1帧给出一个跑步者的边框(bounding-box)之后,后续的第40帧,80帧,bounding-box依然准确圈出了同一个跑步者。以上展示的其实就是目标跟踪(visual object tracking)的过程。目标跟踪(特指单目标跟踪)是指:给出目标在跟踪视频第一帧中的初始状态(如位置,尺寸),自动估计目标物体在后续帧中的状态。
人眼可以比较轻松的在一段时间内跟住某个特定目标。但是对机器而言,这一任务并不简单,尤其是跟踪过程中会出现目标发生剧烈形变、被其他目标遮挡或出现相似物体干扰等等各种复杂的情况。
前面我们讲过目标检测,目标跟踪是一系列的目标检测,目标检测和目标跟踪的异同如下:
- 目标检测一般在静态图像上进行,而目标跟踪就是需要基于录像(视频)。
- 目标跟踪不需要目标识别,可以根据运动特征来进行跟踪,而无需确切知道跟踪的是什么,所以如果利用视频画面之间(帧之间)的临时关系,单纯的目标跟踪可以很高效的实现。
- 基于目标检测的目标跟踪算法计算非常昂贵,需要对每帧画面进行检测,才能得到目标的运动轨迹。而且,只能追踪已知的目标,因为目标检测算法就只能实现已知类别的定位识别。
- 目标检测要求定位+分类。而目标跟踪,分类只是一个可选项,根据具体问题而定,我们可以完全不在乎跟踪的目标是什么,只在乎它的运动特征。实际中,目标检测可以通过目标跟踪来加速,然后再间隔一些帧进行分类(好几帧进行一次分类)。在一个慢点的线程上寻找目标并锁定,然后在快的线程上进行目标跟踪,运行更快。
目标跟踪算法主要分为两大类:生成(generative)模型方法和判别(discriminative)模型方法。
生成类方法是指,在当前帧对目标区域建模,生成描述目标的表观特征,下一帧寻找与表观特征最相似的区域就是预测位置,比较著名的算法有卡尔曼滤波,粒子滤波,mean-shift等。举个例子,从当前帧知道了目标区域80%是红色,20%是绿色,然后在下一帧,搜索算法就像无头苍蝇,到处去找最符合这个颜色比例的区域。生成式方法着眼于对目标本身的刻画,忽略背景信息,在目标自身变化剧烈或者被遮挡时容易产生漂移。
判别类方法是指,运用CV中的经典套路:图像特征 + 机器学习,当前帧以目标区域为正样本,背景区域为负样本,机器学习方法训练分类器,下一帧用训练好的分类器找最优区域。判别式方法因为显著区分背景和前景的信息,表现更为鲁棒,逐渐在目标跟踪领域占据主流地位,所以目前比较流行的也是判别类方法,也叫检测跟踪(tracking-by-detection),主要是结合相关滤波(CF,correlation filter)和深度学习。
不同于检测、识别等视觉领域深度学习一统天下的趋势,深度学习在目标跟踪领域的应用并非一帆风顺。其主要问题在于训练数据的缺失,深度模型的魔力之一来自于对大量标注训练数据的有效学习,而目标跟踪仅仅提供第一帧的bounding-box作为训练数据。这种情况下,在跟踪开始针对当前目标从头训练一个深度模型困难重重。
OpenCV内置的目标跟踪算法
OpenCV集成了八种不同的目标追踪工具,我们可以直接利用这些算法进行实时目标追踪。这八种工具包括:
- BOOSTING Tracker:和Haar cascades(AdaBoost)背后所用的机器学习算法相同,但是距其诞生已有十多年了。这一追踪器速度较慢,并且表现不好,但是作为元老还是有必要提及的。(最低支持OpenCV 3.0.0)
- MIL Tracker:比上一个追踪器更精确,但是失败率比较高。(最低支持OpenCV 3.0.0)
- KCF Tracker:比BOOSTING和MIL都快,但是在有遮挡的情况下表现不佳。(最低支持OpenCV 3.1.0)
- CSRT Tracker:比KCF稍精确,但速度不如后者。(最低支持OpenCV 3.4.2)
- MedianFlow Tracker:在报错方面表现得很好,但是对于快速跳动或快速移动的物体,模型会失效。(最低支持OpenCV 3.0.0)
- TLD Tracker:我不确定是不是OpenCV和TLD有什么不兼容的问题,但是TLD的误报非常多,所以不推荐。(最低支持OpenCV 3.0.0)
- MOSSE Tracker:速度快,但是不如CSRT和KCF的准确率那么高,如果追求速度选它准没错。(最低支持OpenCV 3.4.1)
- GOTURN Tracker:这是OpenCV中唯一以深度学习为基础的目标检测器,它需要额外的模型才能运行。(最低支持OpenCV 3.2.0)
个人建议:
- 如果追求高准确度,又能忍受慢一些的速度,那么就用CSRT。
- 如果对准确度的要求不苛刻,想追求速度,那么就选KCF。
- 纯粹想节省时间追求速度就用MOSSE。
OpenCV目标跟踪算法实践
首先安装imutils:
pip3 install --upgrade imutils
# extract the OpenCV version info
(major, minor) = cv2.__version__.split(".")[:2]
# if we are using OpenCV 3.2 OR BEFORE, we can use a special factory function to create our object tracker
if int(major) == 3 and int(minor) < 3:
tracker = cv2.Tracker_create(args["tracker"].upper())
# otherwise, for OpenCV 3.3 OR NEWER, we need to explicity call the approrpiate object tracker constructor:
else:
# initialize a dictionary that maps strings to their corresponding OpenCV object tracker implementations
# 注意:这里我没有将GOTURN加入到追踪器设置中,因为它还需要额外的模型文件。
OPENCV_OBJECT_TRACKERS = {
"csrt": cv2.TrackerCSRT_create,
"kcf": cv2.TrackerKCF_create,
"boosting": cv2.TrackerBoosting_create,
"mil": cv2.TrackerMIL_create,
"tld": cv2.TrackerTLD_create,
"medianflow": cv2.TrackerMedianFlow_create,
"mosse": cv2.TrackerMOSSE_create
}
# grab the appropriate object tracker using our dictionary of OpenCV object tracker objects
tracker = OPENCV_OBJECT_TRACKERS[args["tracker"]]()
# initialize the bounding box coordinates of the object we are going to track
# 当我们用鼠标选中目标物体时,该变量会显示目标物体的边界框(bounding box)坐标
initBB = None
# if a video path was not supplied, grab the reference to the web cam
if not args.get("video", False):
print("[INFO] starting video stream...")
vs = VideoStream(src=0).start()
# 设定一个一秒钟的暂停时间,好让摄像头传感器进行“热身”
time.sleep(1.0)
# otherwise, grab a reference to the video file
else:
vs = cv2.VideoCapture(args["video"])
# initialize the FPS throughput estimator,初始化FPS(frame per second)吞吐量预估
fps = None
# loop over frames from the video stream
while True:
# grab the current frame, then handle if we are using a VideoStream or VideoCapture object
frame = vs.read()
frame = frame[1] if args.get("video", False) else frame
# check to see if we have reached the end of the stream
if frame is None:
break
# resize the frame (so we can process it faster) and grab the frame dimensions
frame = imutils.resize(frame, width=500)
(H, W) = frame.shape[:2]
# check to see if we are currently tracking an object,如果选定了目标物体
if initBB is not None:
# grab the new bounding box coordinates of the object
# 目标跟踪核心代码,追踪器可能会跟丢目标物并且报错,所以success可能不会一直是True
(success, box) = tracker.update(frame)
# check to see if the tracking was a success
if success:
# 在该frame中框出返回的边界框
(x, y, w, h) = [int(v) for v in box]
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
# update the FPS counter
fps.update()
fps.stop()
# initialize the set of information we'll be displaying on the frame
info = [
("Tracker", args["tracker"]),
("Success", "Yes" if success else "No"),
("FPS", "{:.2f}".format(fps.fps())),
]
# loop over the info tuples and draw them on our frame
for (i, (k, v)) in enumerate(info):
text = "{}: {}".format(k, v)
cv2.putText(frame, text, (10, H - ((i * 20) + 20)), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2)
# show the output frame
cv2.imshow("Frame", frame)
key = cv2.waitKey(1) & 0xFF
# if the 's' key is selected, we are going to "select" a bounding box to track
if key == ord("s"):
# select the bounding box of the object we want to track (make sure you press ENTER or SPACE after selecting the ROI)
# 当键入“s”后,视频暂停,然后手动框选一个ROI,这时按回车或空格键来确定所选区域。如果你需要重新选择,就按“ESCAPE”键
# 当然我们还能用真实的目标探测器来代替手动选择
initBB = cv2.selectROI("Frame", frame, fromCenter=False, showCrosshair=True)
# start OpenCV object tracker using the supplied bounding box coordinates, then start the FPS throughput estimator as well
# 开始目标跟踪
tracker.init(frame, initBB)
fps = FPS().start()
# if the `q` key was pressed, break from the loop
elif key == ord("q"):
break
运行效果:

代码地址 https://github.com/qianshuang/CV
社群
- 微信公众号
