深度学习四大要素:数据、模型、算力、应用。天下文章,数不胜数,所以训练数据,取之不尽用之不竭。预训练模型的潜力远不止为下游任务提供一份精准的词向量,我们还可以利用这些海量数据直接预训练一个龙骨级的语言模型,就像图像领域的ImageNet一样,如果这个龙骨级语言模型里面已经充分的描述了单个字符、字与字之间、句子与句子之间的复杂的关系特征,并且在不同的NLP任务中都通用,那么我们只需要为特定的NLP任务定制一个非常轻量级的输出层(比如单层MLP),然后再根据具体应用,用supervised训练数据,精加工(fine tuning)模型,使之适用于具体应用。BERT(Bidirectional Encoder Representations from Transformers),就是这样的一个自然语言领域的龙骨级语言模型,它不仅包含预训练词向量,还包含模型龙骨结构以及模型参数。下面将从BERT模型的结构、输入以及训练三个方面依次进行介绍。
模型训练
训练数据输入有了,接下去的问题是模型。BERT模型使用两个新的有监督预测任务对BERT进行multi-task迁移学习预训练,分别是MLM(Masked Language Model)和Next Sentence Prediction。
Masked Language Model
我们经常说,“说话时,语句要通顺,要连贯”,其实就是在说自然语言的连贯性。如果语言模型的参数正确,并且每个词的词向量设置正确,那么语言模型的预测,就应该比较准确。传统的语言模型,严格讲是语言生成模型(Language Generative Model),即根据前文的词,预测下一个将要出现的词,即:
 这种语言模型很适合用RNN来做训练,因此也一度成为主流,但是由于RNN网络结构的特殊性,训练效率极低,这种RNN语言模型往往都很浅,只有三到四层,它们是怎样做的呢?假如给定一个句子:“能实现语言表征[mask]的模型”,遮盖住其中“目标”一词,从前往后预测[mask],也就是用“能/实现/语言/表征”,来预测[mask];或者,从后往前预测[mask],也就是用“模型/的”,来预测[mask],这称之为单向预测(unidirectional)。单向预测不能完整地理解整个语句的语义,于是研究者们尝试双向预测,把从前往后,与从后往前的两个预测,拼接在一起[mask1/mask2],这就是双向预测bi-directional。BERT的作者认为,bi-directional仍然不能完整地理解整个语句的语义,因为这两个方向的RNN其实是分开的,也就是说对于正向来说,只能从左往右预测,对于反向来说也只能从右往左预测,但是显然句子中的所有词的语义会同时依赖于其左右两侧的词,所以更好的办法是用上下文全向来预测[mask],也就是用“能/实现/语言/表征/../的/模型”,来预测”目标“,这被称之为deep bi-directional,也就是BERT中所谓的Masked Language Model,即BERT通过Masked Language Model来训练一个深度双向表示(deep bi-directional Transformers)。
这种语言模型很适合用RNN来做训练,因此也一度成为主流,但是由于RNN网络结构的特殊性,训练效率极低,这种RNN语言模型往往都很浅,只有三到四层,它们是怎样做的呢?假如给定一个句子:“能实现语言表征[mask]的模型”,遮盖住其中“目标”一词,从前往后预测[mask],也就是用“能/实现/语言/表征”,来预测[mask];或者,从后往前预测[mask],也就是用“模型/的”,来预测[mask],这称之为单向预测(unidirectional)。单向预测不能完整地理解整个语句的语义,于是研究者们尝试双向预测,把从前往后,与从后往前的两个预测,拼接在一起[mask1/mask2],这就是双向预测bi-directional。BERT的作者认为,bi-directional仍然不能完整地理解整个语句的语义,因为这两个方向的RNN其实是分开的,也就是说对于正向来说,只能从左往右预测,对于反向来说也只能从右往左预测,但是显然句子中的所有词的语义会同时依赖于其左右两侧的词,所以更好的办法是用上下文全向来预测[mask],也就是用“能/实现/语言/表征/../的/模型”,来预测”目标“,这被称之为deep bi-directional,也就是BERT中所谓的Masked Language Model,即BERT通过Masked Language Model来训练一个深度双向表示(deep bi-directional Transformers)。
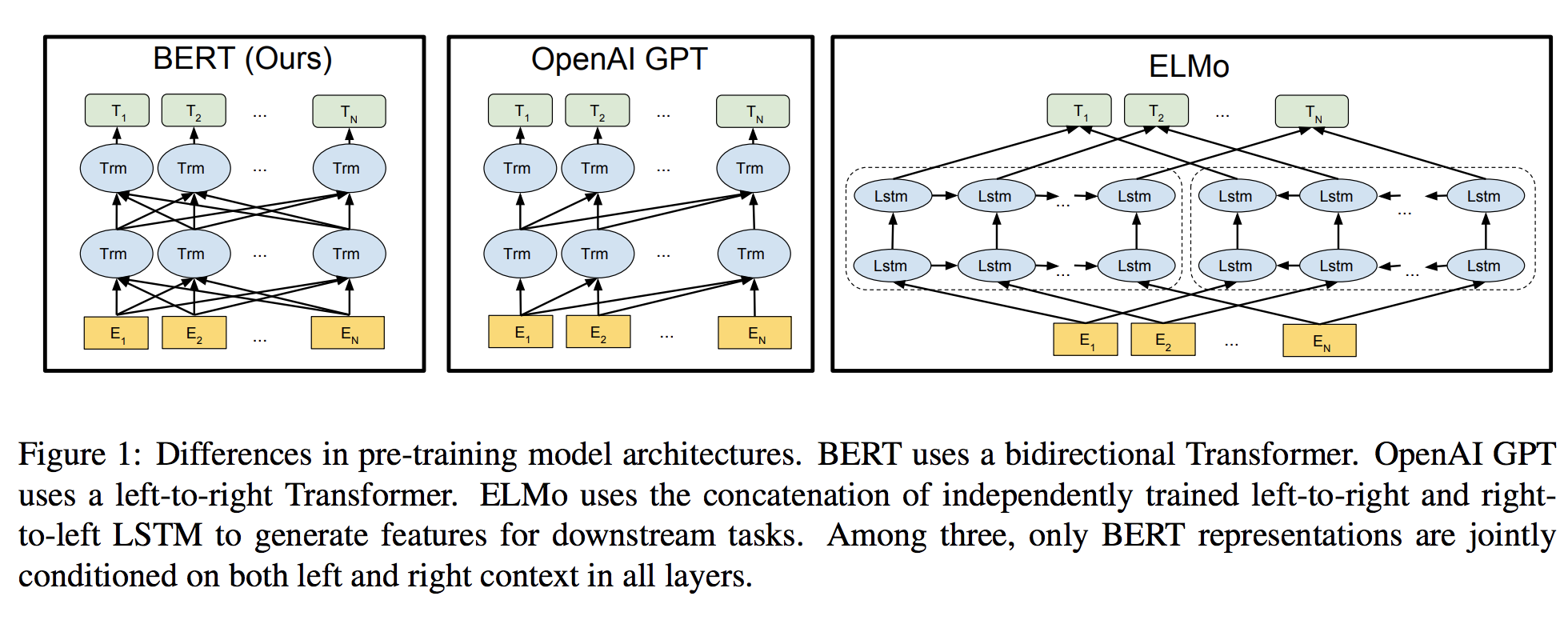
- BERT使用深层双向Transformers。深度即表示多层transformer架构;之所以是双向,其实是每个element经过h次线性变换产生Q、K、V,然后每个Q与其他的element的K计算Attention,也就是说每个节点都是一个transformer单元,如下图所示:
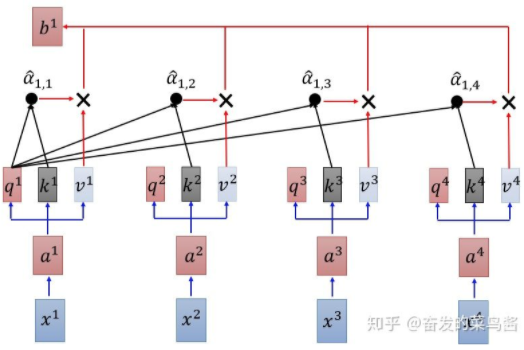
- OpenAI GPT使用从左到右(单向)的Transformer。
- ELMo使用独立训练的从左到右和从右到左LSTM的级联来生成下游任务的特征。
注意:
- 为什么不直接使用Bi-RNN实现真正的双向encoding呢?原因很简单,因为传统的语言模型是以预测下一个词为训练目标的,如果使用bi-RNN模型,那不就表示要预测的词已经被看到了吗?这样当然是没有意义的。
- Word2vec的CBOW模型也是通过上下文的词来预测当前词,两者的根本区别在于,word2vec的context输入并没有考虑词序。
Masked Language Model,顾名思义,就是直接把整个句子的一部分词(随机选取)mask住,然后让模型去预测这些被mask的词是啥(这个任务最开始叫做cloze test,漏字填充测验),简单来说即完形填空。与masked token对应的最终隐向量被送入softmax中进行预测,这其实借鉴了去噪自动编码器(de-noising auto-encoder)的思路,加入噪声(mask)去还原原文本,但是与去噪自动编码器相反,BERT只预测masked words而不是重建整个输入。
他的具体操作是,对于所有训练语料,随机找出15%的token,然后针对这15%再以3种不同的概率做3种处理:80%用[MASK]标记做替换,例如my dog is hairy → my dog is [MASK];10%用一个随机的单词做替换,例如my dog is hairy → my dog is apple;10%维持原样,例如my dog is hairy → my dog is hairy。为什么要进行这么复杂的操作呢?
- 如果总是挖空的话,那么下游任务中(比如序列标注),是需要使用[mask]位置词义的,mask之后就全部使用了[MASK]标记的encoding,而且在下游实际任务中[MASK]标记是不存在的。另一方面由于每个batch只预测了15%的token,那么模型可能需要更多的预训练步骤和训练数据才能收敛。
- 模型中总共有1.5%(15%x10%)的情况是保留原始的,以引导模型去在[MASK]的位置还是考虑一下原来的token输入,即调教模型尽量忽略这些[mask]标记的影响。
- 还有1.5%(15%*10%)的情况是用随机词替换,随机词替换会给模型增加一点点噪声,但是因为此时模型不知道哪个词是被随机换了,所以就迫使他去更好地保留每个词的分布式上下文表示(不像[MASK],给模型[MASK]则模型知道此处的词是被挖了,他需要预测这个位置是啥)。此外,因为随机替换只发生在所有token的1.5%(即15%的10%),这似乎也不会损害模型的语言理解能力。
- musk还起到了dropout的作用。
Next Sentence Prediction
我们经常说,“说话不要颠三倒四“,意思是上下文的句子之间,也应该具有语义的连贯性。很多句子级别的任务如自动问答(QA)和自然语言推理(NLI)都需要理解两个句子之间的关系。那么在这一任务中BERT将数据划分为等大小的两部分,一部分数据中的两个语句对是上下文连续的,另一部分数据中的两个语句对是上下文不连续的(随机组合),然后输入模型,让模型来辨别这些语句对是否match(即是否语义连贯,二分类任务)。
模型架构
BERT中使用了Deep Bidirectional Transformers来实现上下文全向预测,同时训练上述两个任务。Transformers这个模型由《Attention Is All You Need》一文发明,它可以使得每个词位的词都可以无视方向和距离的直接把句子中的每个词的信息都encoding进来(Attention机制),并且self-attention的过程可以把mask标记针对性的削弱匹配权重,尽量降低其对其他任务的影响。关于Transformers模型的详细介绍请翻看我们的《Attention机制》一文。
模型输入
模型的输入表示为单个文本(text)或一对文本(QA pair)。对于给定的词,其输入表示通过三部分Embedding求和组成:
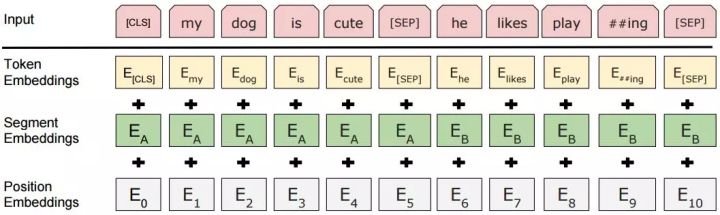 其中:
其中:
- Token Embeddings表示的是词向量,使用WordPiece嵌入和30,000个token的词汇表,用##表示分词,用特殊标记[SEP]将句对的每个句子分开。
- Segment Embeddings用来区别左句子和右句子,因为预训练不只做语言模型还要做以两个句子为输入的match任务,所以添加一个learned sentence A嵌入到第一个句子的每个token中,一个sentence B嵌入到第二个句子的每个token中。对于单个句子输入,只使用sentence A嵌入。
- Position Embeddings是通过模型学习得到的位置embedding,支持的序列长度最多为512个token。
架构细节
模型的每个输入序列的第一个token始终是特殊分类嵌入[CLS],BERT使用Deep Bidirectional Transformer对输入序列进行深度encoding,[CLS]这个特殊token的最终隐藏状态(即Transformer的输出)被用作分类任务的聚合序列表示,对于非分类任务,将忽略此向量。这一做法乍一看有点费解,但是不要忘了,Transformer模型是可以无视空间和距离的把全局信息encoding进每个位置,而[CLS]作为句子或句对的表示是直接跟分类器的输出层连接的,因此其作为梯度反传路径上的”关卡“,当然会自适应的学习到分类相关的上层特征。
BERT对各个下游任务的接口设计也是简洁到过分,对于文本分类和QQ-match任务,如下所示:
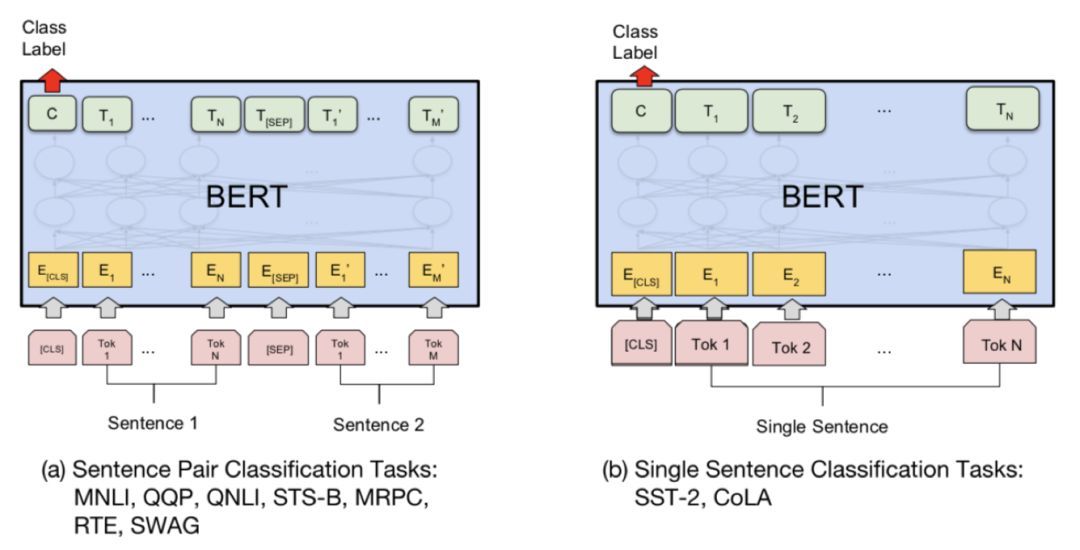 既然句子和句对的上层表示都得到了,那么只需要用得到的表示(即encoder在[CLS]词位的顶层输出)加上一层MLP就好了。
既然句子和句对的上层表示都得到了,那么只需要用得到的表示(即encoder在[CLS]词位的顶层输出)加上一层MLP就好了。
对于NER任务,如下所示:
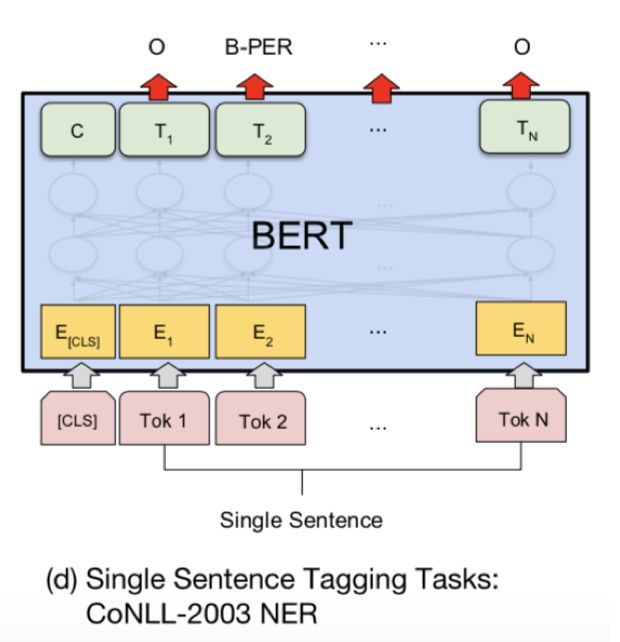 既然文本都被深度双向encode了,那么做NER任务就只需要加softmax输出层就好了,连CRF都不用加。
既然文本都被深度双向encode了,那么做NER任务就只需要加softmax输出层就好了,连CRF都不用加。
论文实现了两个版本的BERT模型,在两个版本中前馈大小都设置为4层,其中层数(即Transformer blocks块)表示为L,隐藏层神经元大小表示为H,自注意力的数量为A。
- BERT BASE:L=12,H=768,A=12,Total Parameters=110M
- BERT LARGE:L=24,H=1024,A=16,Total Parameters=340M
模型训练
下面我们就用BERT来训练我们之前的文本分类任务。
- 首先去Google官方GitHub将bert模型代码clone下来 https://github.com/google-research/bert
- 下载bert模型文件。BERT在英文数据集上提供了两种类型的模型:Base和Large;Uncased意味着输入的词都会转变成小写,cased是意味着输入的词会保存其大写(在命名实体识别等项目上需要);Multilingual是支持多语言的;最后一个是中文预训练模型。这里我们选择最后一个下载,解压后有ckpt文件、一个模型参数配置的json文件、一个词汇表txt文件。

- 直接执行run_classifier.py文件。详见 https://www.cnblogs.com/jiangxinyang/p/10241243.html https://www.jiqizhixin.com/articles/2019-03-13-4