语音识别(Automatic Speech Recognition,ASR)是指机器自动将人的语音的内容转成文字。语音识别是一门交叉的、非常复杂的学科,需要具备生理学、声学、信号处理、计算机科学、模式识别、语言学、数学、统计概率学等相关学科的知识。
语音识别的过程:一段待测的语音需要经过信号处理和特征提取,然后利用训练好的声学模型和语言模型,分别求得声学模型和语言模型得分,然后综合这2个得分,进行候选的ranking,最后得出语言识别的结果。下面将从音频信号处理、声学模型、语言模型几个方面分别进行讲解。
音频信号处理
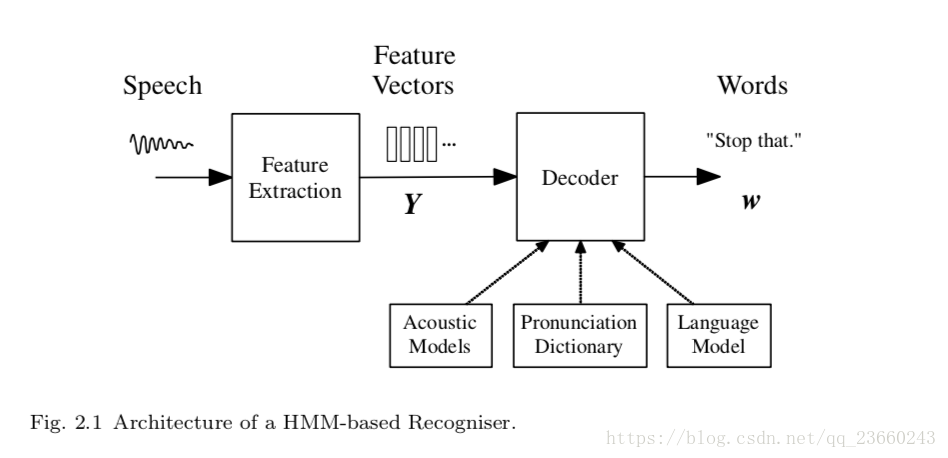
我们知道声音实际上是一种波。常见的mp3、wmv等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件,wav文件里存储的除了一个文件头外,就是声音波形的一个个点了。下图是一个波形的示例:
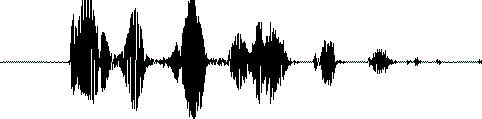 在开始语音识别之前,有时需要先把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。
在开始语音识别之前,有时需要先把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。
要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现,帧与帧之间一般是有交叠的,比如以帧长25ms、帧移10ms分帧,完成后每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。
分帧后,音波就变成了很多小段,但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,即根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的全部内容信息,这个过程叫做声学特征提取。至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。
详情请参见:语音信号预处理及特征参数提取
声学模型
接下来的工作就是把这个12行N列的声学特征矩阵转变成文本了。首先要介绍两个概念:
- 音素:单词的发音由音素构成,比如单词bat由三个音素组成:/b/,/ae/,/t/。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见The CMU Pronouncing Dictionary;对汉语,一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,如“他 仅 凭 腰 部 的 力 量”(ta1 jin3 ping2 yao1 bu4 de li4 liang4)。
- 状态:是比音素更细致的语音单位,通常把一个音素划分成3个状态。
语音识别究竟是怎样工作的呢?非常简单,三步走:第一步,把帧识别成状态(难点);第二步,把状态组合成音素;第三步,把音素组合成文字。前两步是声学模型所干的事情,后两步是语言模型所干的事情。声学模型将声学特征矩阵转变为音素,语言模型将因素合成为文字。
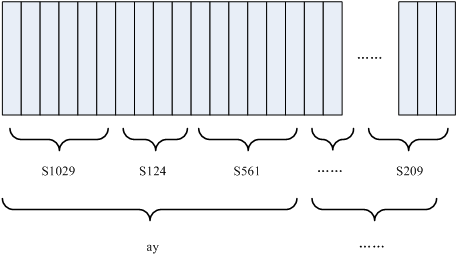 图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态,语音识别的结果也就出来了。
图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态,语音识别的结果也就出来了。
那怎样知道每帧语音对应哪个状态呢?这就是声学模型所干的事情了,即通过传统机器学习或者深度学习模型,预测每一帧对应到每一个状态的概率。如果直接取最大概率所对应的状态会存在一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号,相邻两帧间的状态号基本都不相同,假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素,如果真这么做,得到的状态号可能根本无法组合成音素,实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。
所以很自然的想到通过利用海量语音数据,将单词展开成音素,再展开成状态,最后统计一个状态转移概率矩阵,也就是隐马尔可夫模型(Hidden Markov Model,HMM),HMM我们在前面的章节已经详细介绍过。通过声学模型得到的每帧状态概率结合状态转移概率矩阵,利用维特比解码,寻找全局最优路径,这样就把结果限制在预先设定的可能情况中。
 当然这也带来一个局限,比如你设定的可能情况里只包含了“今天晴天”和“今天下雨”,那么不论输入语音是什么,识别出的结果必然是这两句中的一句。那如果想识别任意文本呢?这就需要端到端的语音识别技术了,目前流行且效果较好的声学模型有GRU-CTC和DFCNN,下面将分别进行介绍。
当然这也带来一个局限,比如你设定的可能情况里只包含了“今天晴天”和“今天下雨”,那么不论输入语音是什么,识别出的结果必然是这两句中的一句。那如果想识别任意文本呢?这就需要端到端的语音识别技术了,目前流行且效果较好的声学模型有GRU-CTC和DFCNN,下面将分别进行介绍。
GRU-CTC
bi-GRU-CTC模型我们在《端到端OCR》一节中已详细介绍,模型原理一模一样,在此不再赘述,代码如下:
inputs = tf.placeholder(tf.float32, [None, 80, 30) # (batch_size, time_steps, feature_size)
targets = tf.sparse_placeholder(tf.int32) # 稀疏矩阵
seq_len = tf.placeholder(tf.int32, [None])
# network structure
cell = tf.contrib.rnn.LSTMCell(num_hidden, state_is_tuple=True)
stack = tf.contrib.rnn.MultiRNNCell([cell] * num_layers, state_is_tuple=True)
outputs, _ = tf.nn.dynamic_rnn(cell, inputs, seq_len, dtype=tf.float32)
# 线性变换
logits = tf.layers.dense(outputs, num_classes, activation=None) # (batch_size, time_steps, num_classes)
# 模型训练
loss = tf.nn.ctc_loss(labels=targets, inputs=logits, sequence_length=seq_len)
cost = tf.reduce_mean(loss)
optimizer = tf.train.AdamOptimizer().minimize(loss)
# 预测或测试时用到
decoded, log_prob = tf.nn.ctc_beam_search_decoder(logits, seq_len) # beam_search
# tf.nn.ctc_greedy_decoder(logits, seq_len) # greedy
acc = tf.reduce_mean(tf.edit_distance(tf.cast(decoded[0], tf.int32), targets))
DFCNN
由于bi-GRU模型的参数是相同节点数全连接层的6倍,这样不论是在训练还是预测阶段,效率都非常低下。因此科大讯飞提出了一种使用DFCNN(Deep Fully Convolutional Neural Network)来对时频图进行处理的方法,即利用全卷积神经网络,在不降低准确率的基础上,将训练和预测效率大幅提升,具有较好的实时性,且深层次的卷积和池化层能够充分考虑语音信号的上下文信息。模型结构如下所示:
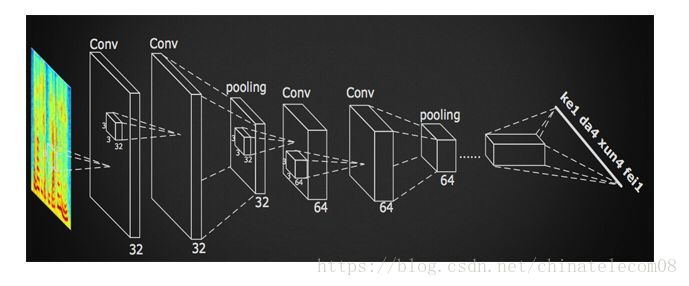 下面是模型实现:
下面是模型实现:
def creatModel():
input_data = Input(name='the_input', shape=(800, 200, 1))
# 800,200,32
layer_h1 = Conv2D(32, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(input_data)
layer_h1 = BatchNormalization(mode=0,axis=-1)(layer_h1)
layer_h2 = Conv2D(32, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h1)
layer_h2 = BatchNormalization(axis=-1)(layer_h2)
layer_h3 = MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(layer_h2)
# 400,100,64
layer_h4 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h3)
layer_h4 = BatchNormalization(axis=-1)(layer_h4)
layer_h5 = Conv2D(64, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h4)
layer_h5 = BatchNormalization(axis=-1)(layer_h5)
layer_h5 = MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(layer_h5)
# 200,50,128
layer_h6 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h5)
layer_h6 = BatchNormalization(axis=-1)(layer_h6)
layer_h7 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h6)
layer_h7 = BatchNormalization(axis=-1)(layer_h7)
layer_h7 = MaxPooling2D(pool_size=(2,2), strides=None, padding="valid")(layer_h7)
# 100,25,128
layer_h8 = Conv2D(128, (1,1), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h7)
layer_h8 = BatchNormalization(axis=-1)(layer_h8)
layer_h9 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h8)
layer_h9 = BatchNormalization(axis=-1)(layer_h9)
# 100,25,128
layer_h10 = Conv2D(128, (1,1), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h9)
layer_h10 = BatchNormalization(axis=-1)(layer_h10)
layer_h11 = Conv2D(128, (3,3), use_bias=True, activation='relu', padding='same', kernel_initializer='he_normal')(layer_h10)
layer_h11 = BatchNormalization(axis=-1)(layer_h11)
# Reshape层
layer_h12 = Reshape((100, 3200))(layer_h11)
# 全连接层
layer_h13 = Dense(256, activation="relu", use_bias=True, kernel_initializer='he_normal')(layer_h12)
layer_h13 = BatchNormalization(axis=1)(layer_h13)
layer_h14 = Dense(1177, use_bias=True, kernel_initializer='he_normal')(layer_h13)
output = Activation('softmax', name='Activation0')(layer_h14)
model_data = Model(inputs=input_data, outputs=output)
# ctc层
labels = Input(name='the_labels', shape=[50], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
loss_out = Lambda(ctc_lambda, output_shape=(1,), name='ctc')([labels, output, input_length, label_length])
model = Model(inputs=[input_data, labels, input_length, label_length], outputs=loss_out)
model.summary()
ada_d = Adadelta(lr=0.01, rho=0.95, epsilon=1e-06)
#model=multi_gpu_model(model,gpus=2)
model.compile(loss={'ctc': lambda y_true, output: output}, optimizer=ada_d)
#test_func = K.function([input_data], [output])
print("model compiled successful!")
return model, model_data
模型原理一目了然,只不过是将bi-GRU换成了多层CNN,其他同bi-GRU-CTC。
语言模型
现在我们知道,声学模型将声学特征矩阵转变为音素(汉语拼音),要将音素合成为文字,还需要借助于语言模型。拼音转文字本质上是一个序列到序列的模型,所以天然适合用诸如机器翻译的seq2seq模型来解决。seq2seq模型我们在《seq2seq》章节中也做了详细介绍,故不再赘述。
社群
- 微信公众号
