语音合成(Text-to-Speech,TTS)是将自然语言文本转换成语音音频输出的技术,在AI时代的人机交互中扮演着至关重要的角色。请大家思考一个问题,导航中的林志玲语音,真的是一条条录出来的吗?
 答案显而易见,肯定不全是事先录出来的,在语音导航中,左转、减速、掉头等较短的语句,通常是录好的内容,关键信息总是在变换的长句子,但是听起来很自然,其实就是通过语音合成技术合成出来的。
答案显而易见,肯定不全是事先录出来的,在语音导航中,左转、减速、掉头等较短的语句,通常是录好的内容,关键信息总是在变换的长句子,但是听起来很自然,其实就是通过语音合成技术合成出来的。
那么语音合成究竟是如何完成的呢?通常有以下几步:
- 首先需要事先录制一些语音(speech unit)作为语音库。为了尽可能的覆盖语言中的元音、辅音、音调,录制的内容通常需要经过一定的设计。
- 其次是预测文本的读音。除了将文本转换成音素(拼音)序列,为了让生成的声音更加自然,我们还要分析文本的节奏、重音,处理文本中的数字、缩写等等。
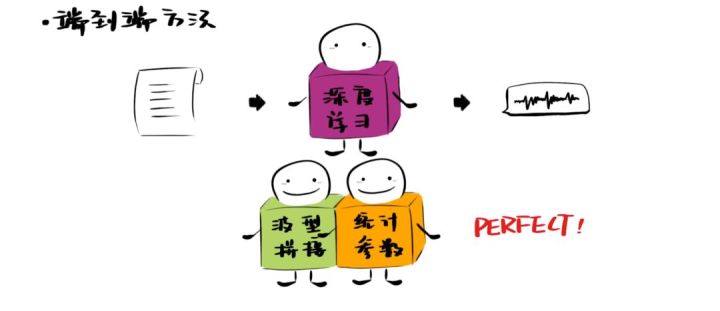
- 接下来才是合成声音。主要有三种方式:一种方法是从语音库中逐一寻找与第二步得到的音素一致的语音元,并将它们的波形拼接起来;另一种方法则是将第二步得到的音素转换成每时每刻的语音参数,加上从语音库中学习到的特征,再生成语音;第三种方法是使用深度学习端到端的完成语音合成任务。不过从结果上看,还是将前两种方法融合起来效果比较好。
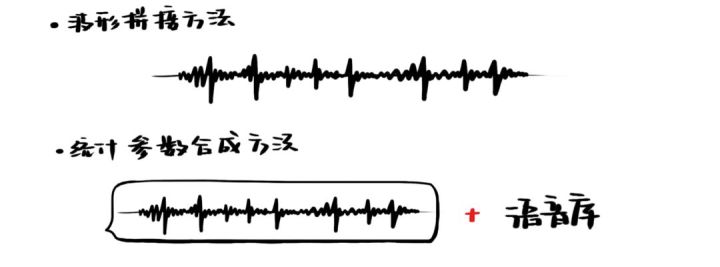
基于参数的语音合成系统
语音库是大量文本和其对应音频的pairs。对于文字,我们像上一节语音识别的做法一样,先将文字展开成音素,再展开成状态。对于音频,我们对其提取声学特征。然后再用统计学模型学习出来状态到声学特征(音素时长、音素基频等)的转换,最后将预测出来的声学特征还原成waveform(声波)。所以核心其实是个预测问题,目前主流是用神经网络来进行从状态到声学特征的预测。将声学特征还原成waveform是通过声码器(vocoder、Griffin-Lim等)来完成的,但是通过声码器合成的声音,毕竟有损失。
一般我们是将波形拼接和参数合成两种思路相结合,取二者优点,得到混合的语音合成解决方案。即用基于参数的语音合成系统预测声学上最匹配的声学特征后,再从库里把它找出来。业界基本上是用这种方案,合成效果融合两种思路的长处,效果最优。
端到端语音合成系统
目前比较热门的做法是用神经网络直接学习文本端到声学特征端的对应关系,即端到端的语音合成系统,不再需要语言学标注系统将文本转为音素及状态了,Google的Tacotron就是其中的代表,不过最后还是需要声码器。再或者,用神经网络直接学习语言学标注端到语音帧级别的waveform端的对应关系,这时就不再需要声码器了,但是需要语言学标注,DeepMind的WaveNet就是其中的代表。现如今还有用神经网络直接学习语言文本端到语音帧级别的waveform端的对应关系,这时声码器和语言学标注就都不需要了,百度硅谷研究院的ClariNet就是其中的代表。
Tacotron
Tacotron模型架构如下所示:
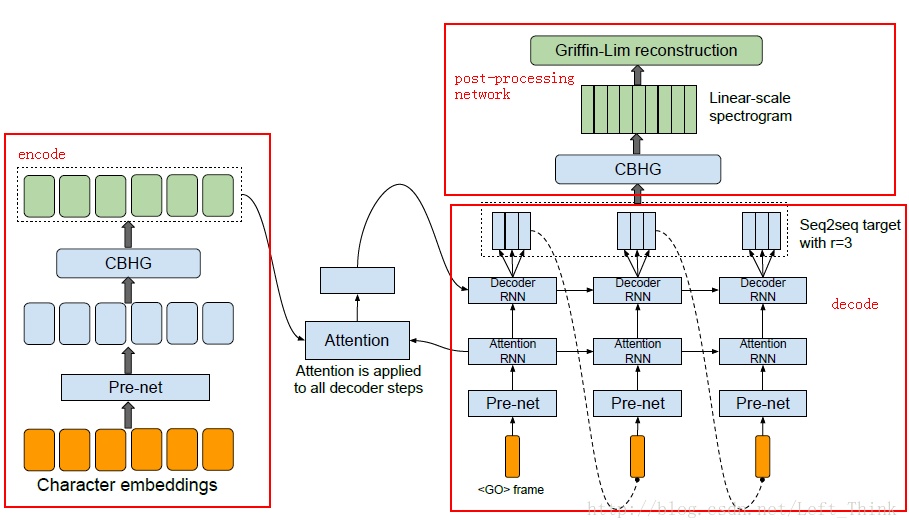 因为需要学习原始文本到声学特征图的对齐关系,所以模型总体上就是一个基于Attention的Encoder-Decoder(seq2seq),首先将输入embeddings通过prenet(即两层DNN)处理成维度为embed_size//2大小的张量,然后进行CBHG编码,紧接着用一个基于注意力机制的解码器产生声谱帧数据,最后用一个后处理网络将产生的声谱帧数据转换成波形。
因为需要学习原始文本到声学特征图的对齐关系,所以模型总体上就是一个基于Attention的Encoder-Decoder(seq2seq),首先将输入embeddings通过prenet(即两层DNN)处理成维度为embed_size//2大小的张量,然后进行CBHG编码,紧接着用一个基于注意力机制的解码器产生声谱帧数据,最后用一个后处理网络将产生的声谱帧数据转换成波形。
其核心是encoder端和decoder端的CBHG模块:
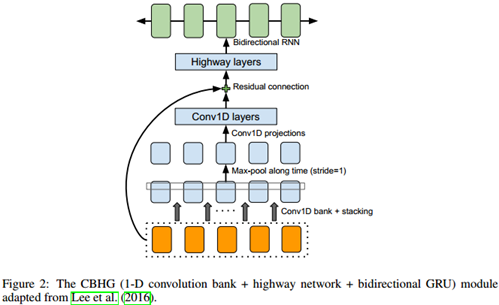
- 首先在输入序列上用K组一维卷积核进行卷积。每组filter的size和个数都不相同,即第k组包含Ck个宽度是k(k=1,2,,,,K)的卷积核。
- 上一步的输出结果被stacking在一起,然后沿时间方向做Max-pooling以增加局部不变性,令步长=1以维持时间方向的原始大小。
- 再经过两层1维卷积(相当于全连接操作),将结果降维到embed_size/2,其输出结果通过残差网络被叠加到原始输入上。
- 将上一步结果送入一个多层highway network来提取高层特征。
- 最上层堆叠一个bi-GRU用来在前后双向提取序列特征。
decoder端在CBHG模块上叠加一个简单的全连接层,作为后处理网络层(构建后处理网络的另外一个动机是它可以看到全体解码结果序列,对比普通seq2seq总是从左到右运行,它可以获得前后双向信息用以纠正单帧预测错误),最终得到带宽为80的梅尔刻度声谱图作为解码器的目标输出。最后使用Griffin-Lim算法做合成器,将解码器的输出转化最终的语音波形。
WaveNet
WaveNet主张用神经网络直接学习语言学标注端到语音帧级别的waveform(音频波形)端的映射关系,直接省掉声码器,是基于CNN的采样点自回归模型。我们来解释一下这句话,语音的波形实际上是一个个采样点的拼接,自回归模型(AR,Autoregressive Model)是最常见的一种平稳时间序列建模,他指的是时间序列X(t)在时间戳t时刻的取值Xt与其前t-1个时刻的取值相关,即自己生成自己,根据一个序列的前t-1个点预测第t个点的结果,通过不断的这样递归下去来预测语音中的采样点数值。基本公式如下:
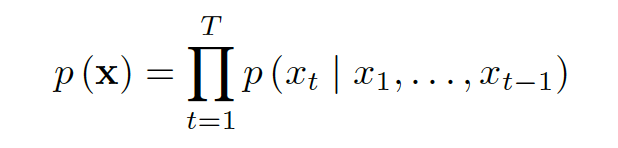 所以WaveNet的语音生成过程如下所示:
所以WaveNet的语音生成过程如下所示:
 Wavenet模型的主要成分是Causal卷积网络(因果卷积),每个卷积层(Hidden Layer)都对前一层进行卷积,层级越高,卷积核越大,时域上的感知能力越强,感知范围越大。在生成过程中,每生成一个点,就把该点放到输入层最后,然后继续迭代生成下一个采样点。由于语音的采样率高,16KHz的采样率的文件,每秒钟就会有16000个元素,时域上对感知范围要求大,但是由于CNN结构的限制,为了解决长距离依赖问题,必须想办法扩大感受野,但扩大感受野又会增加参数量。为了在扩大感受野和控制参数量间寻找平衡,因此采用了Dilated convolutions,叫“扩张卷积”或“空洞卷积”,顾名思义就是计算卷积时跨越若干个点,我们在卷积神经网络章节中介绍过,这里不再赘述。
Wavenet模型的主要成分是Causal卷积网络(因果卷积),每个卷积层(Hidden Layer)都对前一层进行卷积,层级越高,卷积核越大,时域上的感知能力越强,感知范围越大。在生成过程中,每生成一个点,就把该点放到输入层最后,然后继续迭代生成下一个采样点。由于语音的采样率高,16KHz的采样率的文件,每秒钟就会有16000个元素,时域上对感知范围要求大,但是由于CNN结构的限制,为了解决长距离依赖问题,必须想办法扩大感受野,但扩大感受野又会增加参数量。为了在扩大感受野和控制参数量间寻找平衡,因此采用了Dilated convolutions,叫“扩张卷积”或“空洞卷积”,顾名思义就是计算卷积时跨越若干个点,我们在卷积神经网络章节中介绍过,这里不再赘述。
WaveNet的网络结构如下:
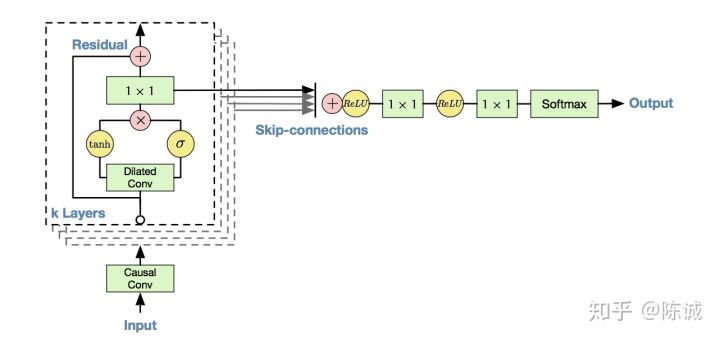 空洞卷积完成后,使用了一个门控卷积进行门控控制:
空洞卷积完成后,使用了一个门控卷积进行门控控制:
 其中*表示卷积操作; \odot 为对应位置相乘运算符(dot product);1 x 1表示使用1x1卷积核进行降维操作或者全连接;最后加入残差网络,避免过拟合并能更好的收敛;Skip-connections是对隐层中每一层的节点,通过把该层原来的值和通过激活函数后的值concat后传递给下一层。最后使用softmax层作为输出层,把采样值的预测作为分类任务进行。
其中*表示卷积操作; \odot 为对应位置相乘运算符(dot product);1 x 1表示使用1x1卷积核进行降维操作或者全连接;最后加入残差网络,避免过拟合并能更好的收敛;Skip-connections是对隐层中每一层的节点,通过把该层原来的值和通过激活函数后的值concat后传递给下一层。最后使用softmax层作为输出层,把采样值的预测作为分类任务进行。
ClariNet
Tacotron从文本出发,在输出端却止步于语谱图,之后再用传统方法将语谱图转换成波形。而WaveNet则需要先从文本中提取语言学特征作为输入,而不是直接使用原始文本。ClariNet把两头都打通,号称是构建了一个从文本到波形、真正端到端的语音合成模型。 详情请看官网介绍:ClariNet,限于篇幅,在此不过多介绍。
社群
- 微信公众号
