之前其实好几篇文章都介绍了智能机器人相关的核心技术,比如语义检索DSSM、深度语义匹配deep QQ-match、迁移学习的Classification & NER multi-task transfer learning,以及知识图谱实战中的智能检索、智能问答等。本篇文章将会把这些核心技术串联起来,并详细介绍智能机器人的总体架构及实现原理。
现如今,用户将越来越多的时间花在少数几个应用程序上,社交和消息应用程序成为了大赢家,用户不喜欢仅为查看一小段信息(例如检查天气、股票价格或查找饭店或地图)而退出其消息应用程序,用户正在逐步外包他们的“杂务”,比如驾驶、购物、清洁、送餐和跑腿,这催生了“零工经济”和更多客户服务的需求。另一方面API经济已成熟到可直接通过终端访问许多有用的服务来完成实际任务。简言之,智能机器人被用在人类用户最喜欢的环境(消息应用程序)中,使用自然语言直接与用户对话,理解用户的意图,并通过庞大的互联服务网络来执行人类的命令。
智能机器人(bot)一般分为任务型机器人(task-bot)、问答型机器人(QA-bot)、闲聊型机器人(chat-bot),下面会分别详细介绍。除此之外还有营销型机器人,它主要是给出推荐结果。IR-based 问答系统(IR:Information Retrieval),根据用户query利用搜索引擎检索相关文章,然后对文章进行阅读理解截取文本片段作为答案。
在科学上,“怎么实现一个机器人”,是一个太宽泛的问题,往往此类问题都会被分解为若干个小问题。例如:怎么让实现让机器人能回答单个问题?怎么实现让机器人能回答连续的问题?怎么让机器人帮我买咖啡?而一个学术领域往往是一个子问题的最新、最优解,而工程上我们往往需要结合不同领域的成果构建一个可用系统。
任务型机器人
任务型机器人(task-bot)是指在特定条件下提供信息或服务的机器人。通常情况下是为了满足带有明确目的的用户服务,例如查流量、查话费、订餐、订票等任务型场景。由于用户的需求较为复杂,通常情况下需分多轮互动,用户也可能在对话过程中不断修改和完善自己的需求,任务型机器人需要通过不断询问、澄清和确认来帮助用户明确目的。
任务型机器人的核心模块主要包括三部分:自然语言理解模块(NLU)、对话管理模块(DM,Dialog Management)、自然语言生成模块(NLG)。整体架构如下:
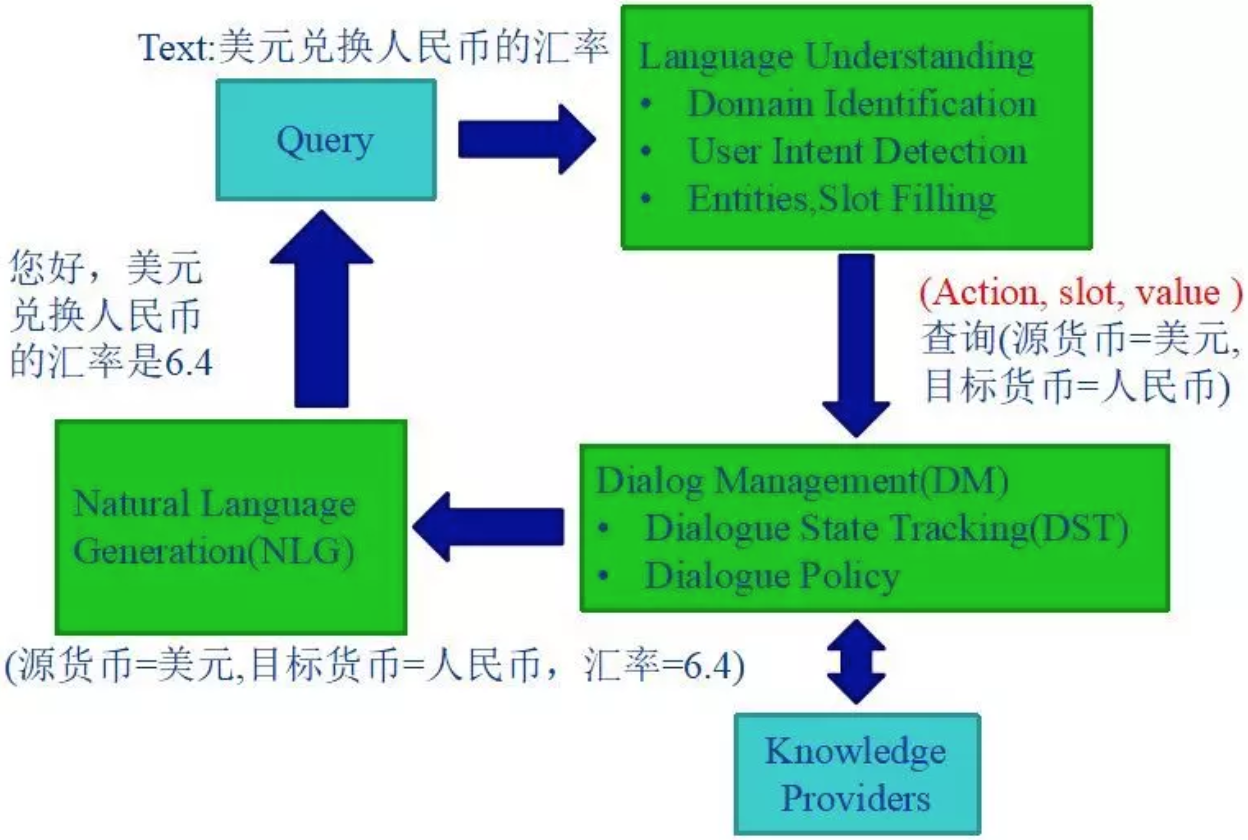 下面将分别介绍这三大模块究竟是怎样协同工作,并通过自然语言对话完成特定任务场景的。
下面将分别介绍这三大模块究竟是怎样协同工作,并通过自然语言对话完成特定任务场景的。
NLU
当用户语言(query)经过自然语言理解模块时,即需要经过领域识别、用户意图识别、槽位提取三个子模块。
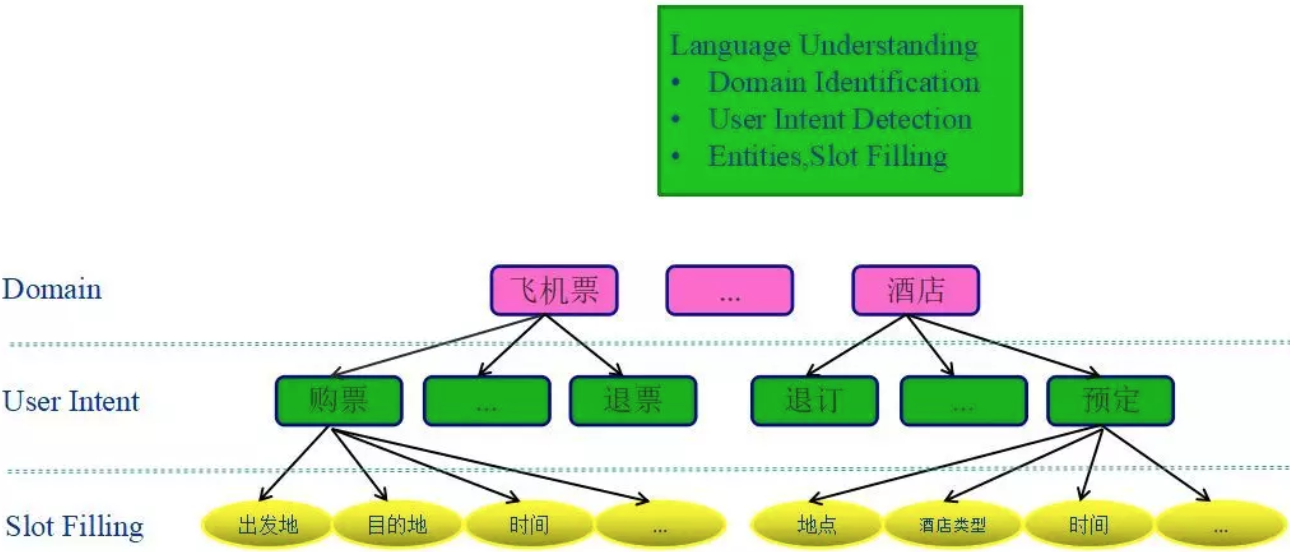 领域识别(Domain Identification),即识别用户query的所属任务场景。意图识别(User Intent Detection),即识别用户意图,当领域识别模块识别出用户query属于该任务场景后,通过识别出的用户意图细分到该任务型场景下的子场景。实体识别与槽位填充(Entities Slot Filling),一般用于对话管理模块的输入。假设用户query=“人民币对美元的汇率是多少?”,经过自然语言理解模块会解析为intent(slot1 = value1, slot2 = value2 ……)的形式,即意图、槽位、槽位信息的三元组形式,此处会被解析为“查汇率(源货币 = 人民币, 目标货币 = 美元)”这样的形式。
领域识别(Domain Identification),即识别用户query的所属任务场景。意图识别(User Intent Detection),即识别用户意图,当领域识别模块识别出用户query属于该任务场景后,通过识别出的用户意图细分到该任务型场景下的子场景。实体识别与槽位填充(Entities Slot Filling),一般用于对话管理模块的输入。假设用户query=“人民币对美元的汇率是多少?”,经过自然语言理解模块会解析为intent(slot1 = value1, slot2 = value2 ……)的形式,即意图、槽位、槽位信息的三元组形式,此处会被解析为“查汇率(源货币 = 人民币, 目标货币 = 美元)”这样的形式。
意图识别其实是一个典型的文本分类任务,但是可能需要结合用户当前query以及上下文context信息(多轮对话),常用方法比如之前曾介绍过的ContextCNN、HierarchicalCNN模型。实体识别与槽位填充可以通过规则匹配(正则表达式)的方法,也可以通过NER的方式,也有用生成模型seq2seq来做的。我还是更偏向于使用CF & NER multi-task transfer learning模型进行多任务学习,一个模型搞定两个任务,详情可以参见我们之前的迁移学习章节。
DM
NLU模块的三元组输出将作为DM模块的输入,DM模块包括两大核心:状态追踪以及对话策略。
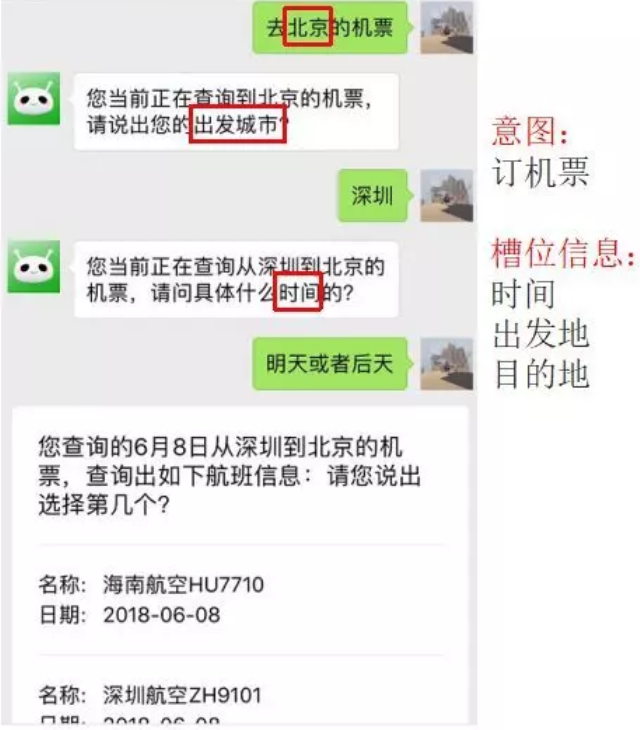
状态追踪模块通常采用状态机流转,实现多轮会话中的上下文状态记忆、处理意图跳转、修改slot值等。比如用户首先提问“我想订一张从北京到上海的机票”,这是一个订机票意图,目的地slot的值是上海,用户马上又问“还想订酒店”,这时候意图跳转为订酒店,订酒店也有一个目的地slot,这时候就会通过状态机回溯到上一个订机票状态,并自动填充订酒店的目的地slot为订机票的目的地slot——上海。
对话策略则与所在的任务场景息息相关,通常作为DM模块的输出,决定下一步的对话走向,如对缺失槽位的反问策略等。
还是继续上面的用户query=“人民币对美元的汇率是多少?”。“查汇率(源货币 = 人民币, 目标货币 = 美元)”这样的形式将作为DM模块的输入,这时候状态追踪模块就要根据前几轮的信息,结合该输入得到想要查询的确实是人民币对美元的汇率信息。这时候,根据现有的对话策略给出对话管理模块的输出,如查询结果(源货币=人民币,目标货币=美元,汇率=1:0.16)
把对话看做是在有限状态内跳转的过程,每个状态都有对应的动作和回复,如果能从开始节点顺利的流转到终止节点,任务就完成了。
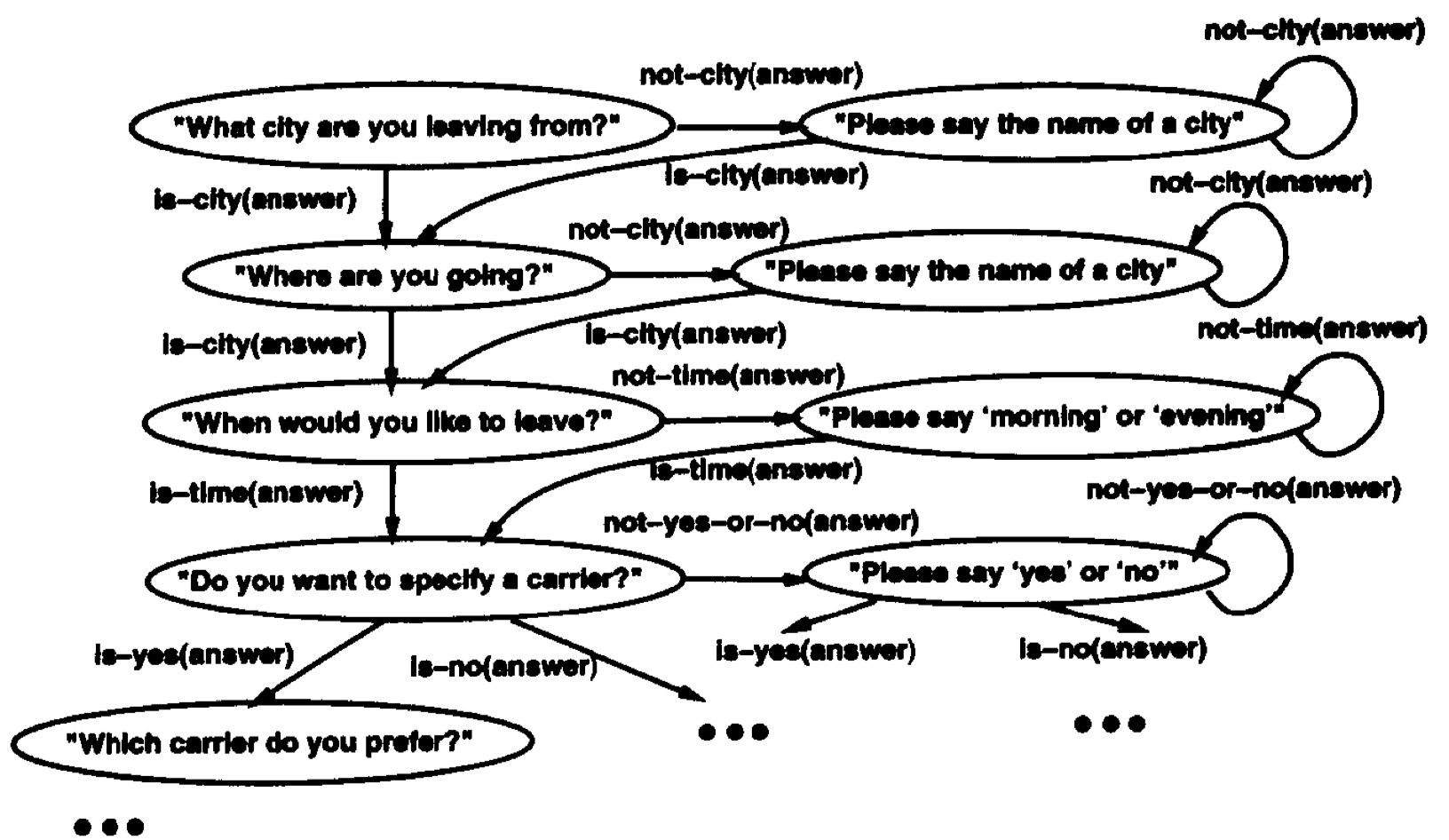 对话管理模块相当于任务型机器人的大脑。主要还是基于规则的方法,目前流行的有基于强化学习的方法,但是基于强化学习的对话管理系统需要很多数据去训练,并且不太稳定,对于复杂对话还是不能很好的应付。
对话管理模块相当于任务型机器人的大脑。主要还是基于规则的方法,目前流行的有基于强化学习的方法,但是基于强化学习的对话管理系统需要很多数据去训练,并且不太稳定,对于复杂对话还是不能很好的应付。
NLG
NLG模块的作用就是根据DM的输出结果组装回复返回给用户,通常的做法是设定回复的模板,替换模板中的变量。
目前市面上也有很多类似于机器人工厂的产品,比如阿里的bot framework以及百度的baidu unit等,用户可以利用这些机器人平台拖拖拽拽然后进行简单个性化配置即可快速生成一个定制化的task-bot。但是这些机器人工厂由于高度通用化,所以功能有限,并且可拓展性较差,因此并不实用。
问答型机器人
问答型机器人(QA-bot),也叫封闭领域智能机器人,之所以叫做封闭领域,因为它是在特定域内找出某个问题的答案,这个特定域内的输入和输出空间有限,并且希望尽快完成对话,也就是对话轮数越少越好,通常是单轮的。其架构如下所示:
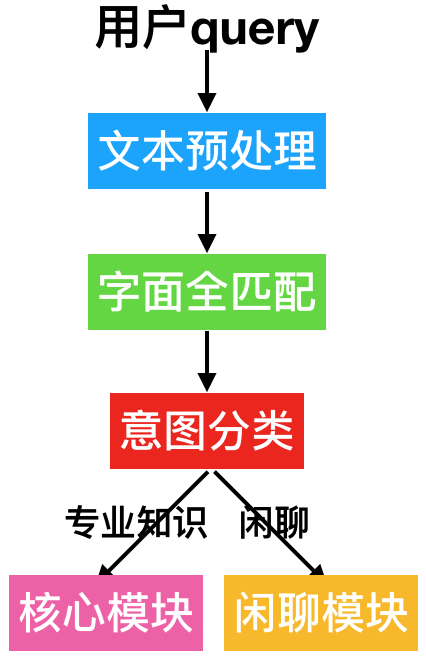
- 首先拿到用户query进行文本预处理,比如停用词过滤、数字日期处理等字符标准化操作。
- 将预处理后的文本与问答库中的标准问题进行字面全匹配,若匹配上则直接返回答案。
- 若没有匹配上则进入意图分类模块,判断是专业知识咨询还是闲聊意图。
- 闲聊意图路由到闲聊模块,可以直接调用开源闲聊模型服务,或者自己实现闲聊型机器人(接下来会讲解)。专业知识咨询意图路由至核心模块,如下所示:
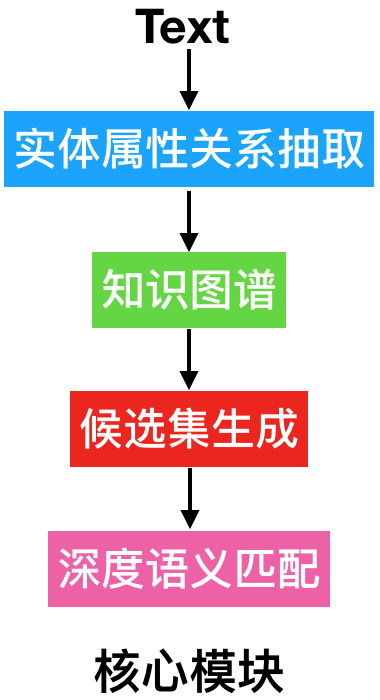
- 首先通过NER任务进行实体属性关系抽取。
- 查询知识图谱。一般需要人工录入实体属性关系三元组至图数据库(graph database)构建知识库,三元组的结构是(实体,属性,属性值)或者(实体,关系,实体)。例如有知识库(三元组):(中国,有首都,北京)(北京,是某国的首都,中国),那么就可以解答用户输入“中国的首都是哪”,“北京是哪个国家的首都”,“中国与北京的关系”这样的问题,这三个问题分别相当于查询(中国,有首都,?),(北京,是某国的首都,?),(中国,?,北京)。详情参见我们之前的知识图谱实战这一章节。
- 若从知识图谱中查询到结果则直接返回,否则需要通过某种方式获得若干候选结果。最简单的方法是通过全文检索的方式;当然如果想通过语义检索,就需要一个语义映射函数vec(x),把一个问题或者答案转换成一个有限长度的实数向量,然后通过一个相似度函数similarity(x, y)来判断两个向量是否相似。那么当用户来了一个问题q_user的时候,我们可以先把它向量化得到vec(q_user),然后再去匹配我们已经预先向量化好的其他问题,因为向量相似匹配的算法,远快于遍历所有问题(或答案)。通常情况下,映射函数vec(x)可以直接取word embedding的加和平均。
- 若无候选集(所有候选集的得分均低于阈值),此时给出推荐问或常用问。
- 将候选结果(问答库中的标准问题或答案)一一与用户query通过deep QQ-match模型进行深度语义匹配,若match score小于阈值则出推荐,否则返回得分最高的答案。
当然上面是经典做法,也可以将意图分类和闲聊模块去掉,字面全匹配后直接进入核心模块,最终如果经过deep QQ-match后候选答案的score都低于阈值,那么进入兜底的闲聊意图(如果训练语料不包含闲聊)或返回兜底话术如“正在学习中”(训练语料中包含闲聊问答)。还有一种比较有效的做法是对核心模块的改进,经过知识图谱模块处理完后,先通过分类模型将用户query分到常用问题类目,如果分到常用问题类,则直接返回答案,否则进入候选集生成模块。
最后在可用性方面,当系统并发量上去以后,需要有应对方案,比如对deep QQ-match模型扩容或者降级。扩容一般是指增加CPU、GPU核数以及实例数,降级一般是直接shutdown(即在候选集召回模块直接返回得分最高的答案)或者选择RT更低的QQ-match模型。
闲聊型机器人
闲聊型机器人(chat-bot),也叫开放领域智能机器人,它没有明确的对话目标,输入和输出空间无限大,并且希望尽可能延续对话,也就是对话轮数越多越好。
AIML
它们主要通过模板实现,也就是人工定义对话模板,产生类似智能的效果。这样的机器人模板其实可以很多,例如Alicebot有超过六万条AIML模板来覆盖绝大部分日常对话。AIML即人工智能标记语言,是用来通过定义模板实现闲聊机器人的一种方法。它的最简单的例子是这样的:
<category>
<pattern>YOU CAN DO BETTER</pattern>
<template>Ok, I will try.</template>
</category>
问题是“you can do better”,机器人会回答“ok, i will try”。
用户:你喜欢 * 吗?
系统:我喜欢 * 啊,你喜欢吗?
系统:我喜欢 * 啊,你还喜欢什么别的吗?
用户:你吃过 * 吗?
系统:我是机器人,不吃 *
系统:* 好吃吗?你告诉我呗
用户:你觉得 * 怎么样?
系统:这取决于你对 * 的理解,我不好回答啊
系统:我觉得 * 还不错吧,你怎么看?
AIML还可以完成很多复杂的功能,比如计算1+1=?等。这里列出几个不错的AIML产品:
Rive Script
Super Script
生成模型
与模板方法相对的,是基于深度学习的模型,即基于神经机器翻译技术演变而来的对话生成模型(其核心原理我们在seq2seq章节已详细介绍过),类似于机器翻译,例如一句英文翻译为一句中文,对话中,上一句对话也可以“翻译”到下一句对话,本质是根据统计学方法进行的一种文本生成,这种文本生成往往会生成语法正确的句子,但语义、逻辑、一致话、发散性等地方会有问题。
发散性也指结果的重复性,因为闲聊会话中,多个不同输入可以对应同一输出,这就导致生成式对话模型更容易出现“I don’t know”问题,也就是模型更容易学会更好回答而不犯错的答案,任何问题都回答“我不知道”就行了,或者类似的简单回复。解决方案也有很多,通常采用抗语言模型与互信息模型。假设我们训练语料的第一句话是S,而回复是T,例如:
S:你今年几岁了?<br>
T:野原新之助,5岁!
一般来说我们所训练提高的概率就是P(T|S),损失函数log(P(T|S))。抗语言模型(anti-language)的损失函数:log(P(T|S)) - log(P(T)),也就是我们在提高P(T|S)的同时,需要抑制P(T)。解释是:如果T是经常出现的句子,例如“我不知道”,那么P(T)就会很高,所以我们需要人为降低P(T)出现的概率。互信息模型损失函数:log(P(T|S)) + log(P(S|T)),解释是:提高S与T的相关性,如果T是与S完全无关的回复,例如“我不知道”,那么P(S|T)的概率就会很低,即相关性很低,我们的目的是奖励S与T相关性(互信息)高。
训练不同情绪或人格的chatbot
我们可以把语料分为不同的情绪,然后结合一些trick,例如给训练数据添加一些标签:
S: [happy] 你 好
T: 你好啊!偶好开心!
S: [sad] 你 好
T: 哦……你来啦
S: [angry] 你 好
T: 你滚啦!
这样把标签后的数据一起输入模型进行训练,使用时只要给用户的输入加入不同的标签,则可以得到不同情绪的机器返回结果。当然了,你也可以直接根据不同情感训练多个模型,具体怎么做好需要实际测试。
社群
