推荐系统是一个让人又爱又恨的领域(大坑),爱它是因为,要知道人的惰性是可以无限放大的,DT时代充斥着海量信息,比起主动搜索,人们更愿意被动的接受推荐,而随着越来越多的推荐数据被拿来做训练,推荐结果也会越来越好,甚至推荐系统会比你更懂你,这样人就会越来越懒,如此恶性循环;另一方面在弱人工智能时代,基于大数据的搜索、推荐这种类AI的应用场景将更加具有实用性。
恨他的原因主要是在于,在实际业务场景中,很难给出一个准确的评价函数来评价我们推荐系统的效果。这涉及到推荐系统中多样性与精确性的两难困境,盲目崇拜精确性可能会导致用户得到一些信息量为0的“精准推荐”并且视野变得越来越狭窄,让用户视野变得狭窄是协同过滤算法的一个主要缺陷,这会进一步加剧长尾效应,与此同时,应用个性化推荐技术的商家,也希望推荐中有更多的品类出现,从而激发用户新的购物需求。
但是,多样性与精确性之间往往存在矛盾,因为前者风险很大,因为一旦推荐一个没人看过或者打分较低的东西,很可能被用户憎恶,从而效果更差,只能通过牺牲多样性来提高精确性,或者牺牲精确性来提高多样性。所以通常我们会使用组合推荐策略来精巧的融合精确性与多样性,遗憾的是,多样性和精确性之间错综复杂的关系和隐匿其后的竞争,到目前为止还是一个很棘手的难题。
总的来说,推荐系统有三个层次的评价指标,常见的准确率、召回率、点击率、AUC等属于第一层次;第二个层次是商业应用上的关键表现指标,如受推荐影响的转化率、购买率、客单价、购买品类数、总收入(排名需要根据CTR * 价格)等;第三个层次是用户真实的体验。绝大部分研究只针对第一个层次的评价指标,而业界真正感兴趣的是第二个层次的评价(比如到底是哪个指标或者哪些指标组合的结果能够提高用户购买的客单价),而第三个层次最难,没人能知道,只能通过第一层和第二层的结果来估计。实际上,在实际业务场景中,更为重要的是另外两个层次的评价。
前面我们介绍了基于传统机器学习的推荐系统,后续的所有文章我们将主要介绍基于深度学习的推荐系统,下图揭露了推荐算法演化路径,首当其冲的当属Google的wide & deep model。
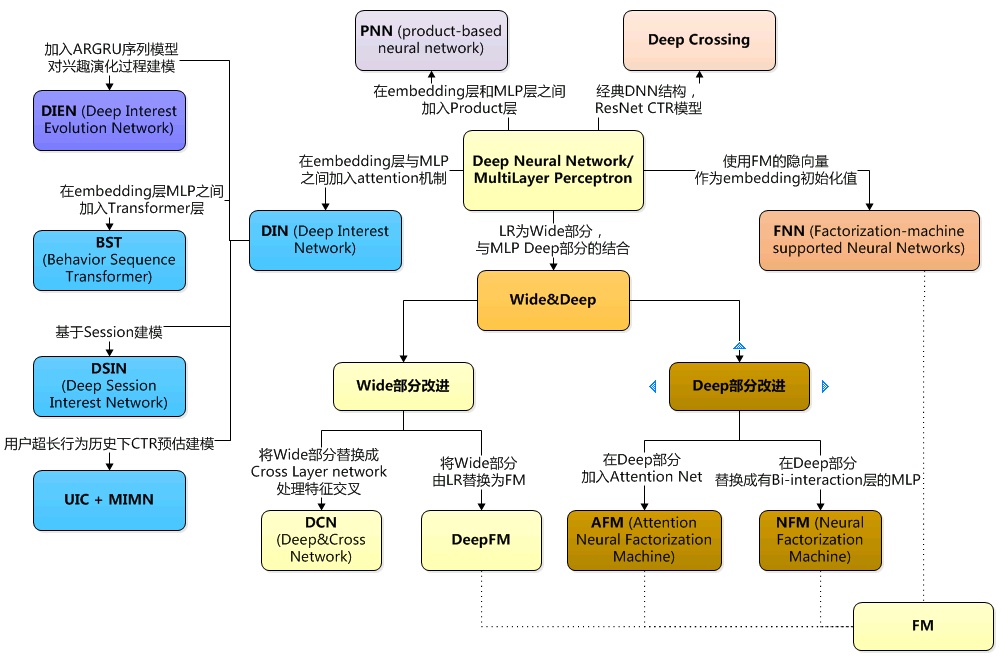
推荐系统包含两个模块,召回和排序,召回模块一般使用一系列机器学习模型的组合或者人为定义的规则从海量items中得到一批候选集,常见的召回算法包括:User-Based协同过滤、Item-Based协同过滤、Query-Based search(根据Query中包含的实时信息,如地理位置信息、WiFi到店、关键词搜索、导航搜索等对用户的意图进行抽象并提起关键信息)。然后排序模块对候选集进行排序,我们后面要说的一系列推荐算法绝大部分都是排序模块,wide & deep模型就是其中之一。
推荐系统评价指标
AUC
我们一般使用AUC指标值来评判一个推荐系统好坏,AUC的计算方法同时考虑了分类器对于正例和负例的分类能力,并且在样本不平衡的情况下,依然能够对分类器作出合理的评价。例如在反欺诈场景,设欺诈类样本为正例,正例占比很少(假设0.1%),如果使用准确率评估,把所有的样本预测为负例,便可以获得99.9%的准确率;但是如果使用AUC,把所有样本预测为负例,TPRate和FPRate同时为0(没有Positive),与(0,0)(1,1)连接,得出AUC仅为0.5,成功规避了样本不均匀带来的问题。
另外,对一份测试集随意repeat正负样本的比例,AUC是不会有任何变化的。因为RoC曲线的纵轴是正例的召回率,与负样本无关;横轴是1-负例召回率,与正样本无关。所以只要召回率不变,AUC也是不会有任何变化的。
从另一方面来说,AUC的值等价于:任意给一个正类样本和一个负类样本,正类样本的score有多大的概率大于负类样本的score。即AUC的计算方式为:
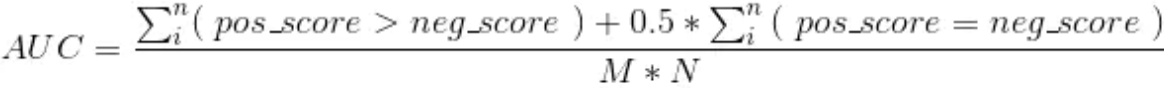 即将模型输出的所有概率值均+0.1,模型的auc是不变的(假设增加后概率不超过1)。
即将模型输出的所有概率值均+0.1,模型的auc是不变的(假设增加后概率不超过1)。
AUC具体含义参见:https://www.zhihu.com/question/39840928
也有研究尝试直接优化AUC,参见:https://zhuanlan.zhihu.com/p/69852955
MAP
MAP(Mean Average Precision),是一种对顺序敏感的Precision。假使当我们使用google搜索某个关键词,返回了10个结果,假如只有5个是正确的,那么这5个结果被展示地比较靠前就比展示地靠后效果要好。举个例子就清楚了:
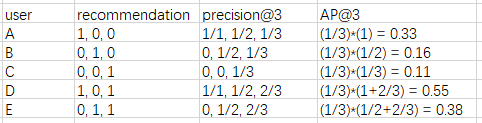 其中,user列表示一共有5个用户,recommendation列表示推荐的3个结果是否正确,precision列表示每个位置的准确率,AP列表示平均准确率(如果对应位置推荐错误,那么该位置取0,也即不参与加和)。
其中,user列表示一共有5个用户,recommendation列表示推荐的3个结果是否正确,precision列表示每个位置的准确率,AP列表示平均准确率(如果对应位置推荐错误,那么该位置取0,也即不参与加和)。
MAP = (0.33+0.16+0.11+0.55+0.38) / 5 = 0.306
模型架构
人类的大脑很复杂,它可以记忆(memorize)下每天发生的事情(麻雀可以飞,鸽子可以飞)然后泛化(generalize)这些知识到之前没有看到过的东西(有翅膀的动物都能飞)。但是泛化的规则有时候不是特别的准,有时候会出错(有翅膀的动物都能飞吗)。那怎么办那,没关系,记忆(memorization)可以修正泛化的规则(generalized rules),叫做特例(企鹅有翅膀,但是不能飞)。
wide & deep模型中的wide feature和deep feature分别使模型具备了很好的记忆性(Memorization)和泛化性(Generalization), 记忆性指学习items或features的frequent co-occurrence,以及尽量多的利用历史数据中的可用相关性。泛化性指基于相关性的传递,探索过去从未或很少发生过的新的feature combinations。正如推荐系统追求多样性和精确性的双重效果,精确性与记忆性的效果一致,泛化性倾向于提高推荐项的多样性。
记忆不同特征之间的交互组合是非常有效且有很好的可解释性,但是较好的泛化能力要求大量的特征工程。而深度学习可以通过学习稀疏特征的embedding来达到更好的泛化能力,泛化到一些没有见过的特征组合上,但是深度学习会过泛化(over-generalize),即在user-item的interactions比较稀疏和高维数特征(high-rank)的情况下,会推荐一些不太相关的东西。
wide feature除了包含原始特征,还包含交叉变换的特征,其实就是某些个特征值相乘,这样给wide部分的线性模型注入了非线性因素,公式如下:
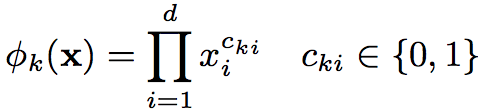 wide & deep模型架构如下图所示:
wide & deep模型架构如下图所示:
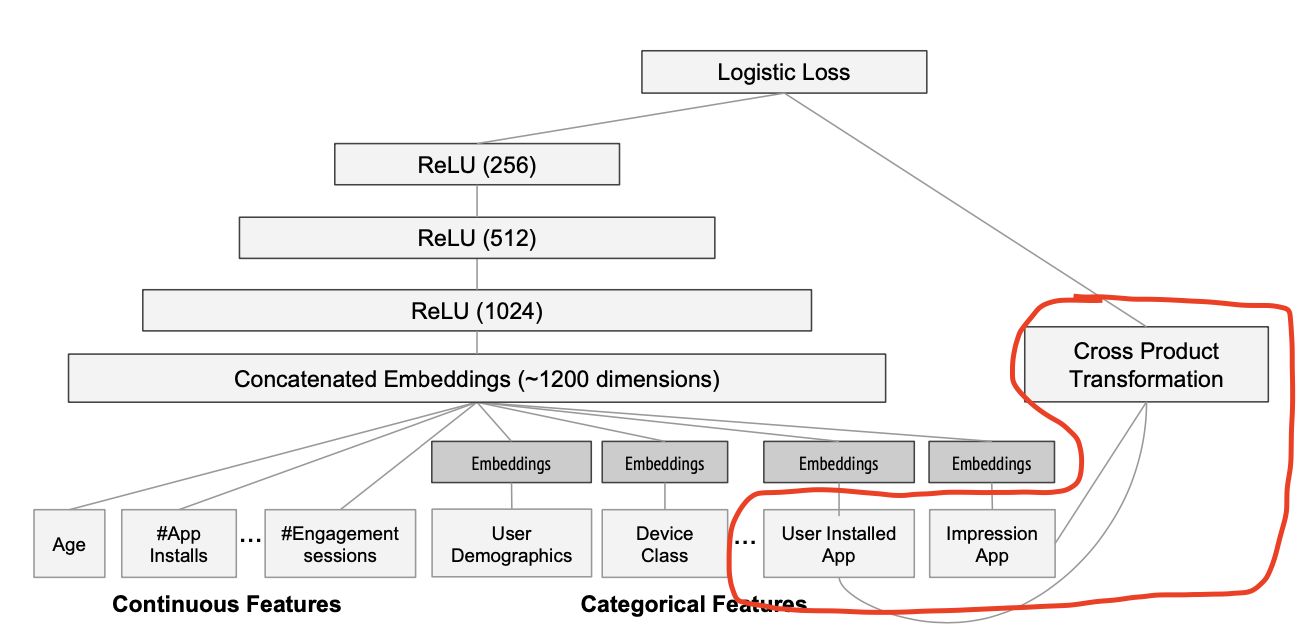 wide & deep模型中,wide部分由不加激活函数的单层全连接神经网络(线性模型)构成,deep部分由多层神经网络构成,输出层采用softmax或logistics regression综合Wide和Deep部分的输出。
wide & deep模型中,wide部分由不加激活函数的单层全连接神经网络(线性模型)构成,deep部分由多层神经网络构成,输出层采用softmax或logistics regression综合Wide和Deep部分的输出。
模型训练
Wide & Deep Model的训练过程还是通过优化一个二分类交叉熵损失函数,通过mini-batch梯度下降算法同时将梯度反向传播至wide部分和deep部分,只不过对于梯度的优化算法不同,对于wide部分使用FTRL+L1正则算法(线性模型优化算法),对于deep部分使用AdaGrad(神经网络优化算法)。为什么要这样做呢?
因为不论是L1正则还是FTRL都更容易让模型产生稀疏解,也就是说L1+FTRL会让Wide部分的特征权重大部分都为0,这大大压缩了模型计算复杂度。上图的红框部分就是wide feature,居然采用了两个id类特征(multihot)的乘积,Google的工程师使用这个交叉变换特征的意图,是想发现当前曝光app和用户安装app的关联关系,以此来直接影响最终的得分,但是两个id类特征向量进行组合交叉,一方面会维度爆炸,另一方面会让原本已经非常稀疏的multihot特征向量变得更加稀疏,所以其实wide部分的权重数量是海量的,为了不把数量如此之巨的权重都搬到线上进行model serving,采用FTRL过滤掉那些稀疏特征权重无疑是非常好的工程经验。也说明了稀疏特征用宽而浅的线性模型会更加稳定可靠。另一方面,从模型收敛上来看,wide部分直连输出,有点像残差网络,反向传播一步到位,所以wide部分如果跟deep部分一个优化器,会收敛太快。
我们对两个network进行jointly train,在训练期间,每个独立的network会察觉到另一个。
#对于没有那么多取值的类别变量,直接用one-hot
sex = tf.contrib.layers.sparse_column_with_keys(column_name="Sex", keys=["female", "male"])
#如果类别变量取值较多,将类别id对1000取模,再进行one-hot,相当于限制one-hot向量维度为1000
city = tf.contrib.layers.sparse_column_with_hash_bucket("city", hash_bucket_size=1000)
#对特征进行交叉变换
sport_x_city = tf.contrib.layers.crossed_column([sex, city], hash_bucket_size=int(1e4))
#连续型特征直接用原始值
age = tf.contrib.layers.real_valued_column(“age”)
#年龄桶化(Bucketization)允许我们找到乘客对应年龄组的生存相关性,按照年龄段分组,再进行one-hot。
age_buckets = tf.contrib.layers.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
wide_columns = [gender, native_country, education, occupation, workclass, relationship, age_buckets,
tf.contrib.layers.crossed_column([education, occupation], hash_bucket_size=int(1e4)),
tf.contrib.layers.crossed_column([age_buckets, education, occupation], hash_bucket_size=int(1e6)),
tf.contrib.layers.crossed_column([native_country, occupation],hash_bucket_size=int(1e4))]
deep_columns = [age, education_num, capital_gain, capital_loss, hours_per_week,
tf.contrib.layers.embedding_column(workclass, dimension=8),
tf.contrib.layers.embedding_column(education, dimension=8),
tf.contrib.layers.embedding_column(gender, dimension=8),
tf.contrib.layers.embedding_column(relationship, dimension=8),
tf.contrib.layers.embedding_column(native_country,dimension=8),
tf.contrib.layers.embedding_column(occupation, dimension=8)]
if FLAGS.model_type =="wide":
m = tf.contrib.learn.LinearClassifier(model_dir=model_dir, feature_columns=wide_columns,
optimizer=tf.train.FtrlOptimizer(learning_rate=0.1, l1_regularization_strength=1.0)) # 指定优化算法
elif FLAGS.model_type == "deep":
m = tf.contrib.learn.DNNClassifier(model_dir=model_dir, feature_columns=deep_columns, hidden_units=[100,50])
else:
m = tf.contrib.learn.DNNLinearCombinedClassifier(model_dir=model_dir, linear_feature_columns=wide_columns, dnn_feature_columns = deep_columns, dnn_hidden_units=[100,50])