本文介绍几篇基于FM模型的拓展研究。
AFM
AFM(Attentional Factorization Machines),即在FM两两特征交叉后,加入Attention Layer,模型架构如下:
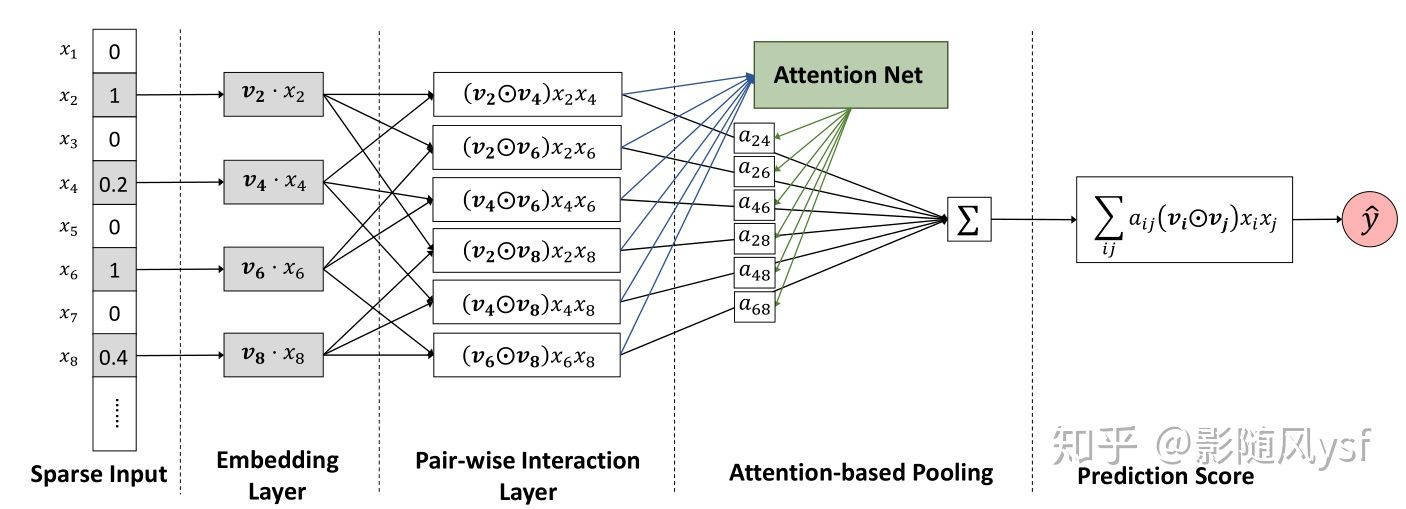 公式表达式为:
公式表达式为:
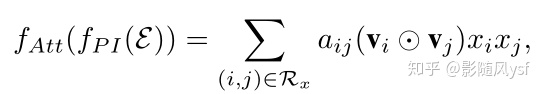 Attention计算采用MLP形式(非dot-product形式):
Attention计算采用MLP形式(非dot-product形式):
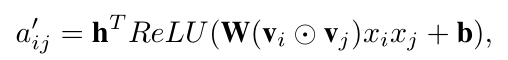 然后通过softmax归一化:
然后通过softmax归一化:
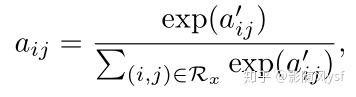 最终AFM模型的表达式为:
最终AFM模型的表达式为:
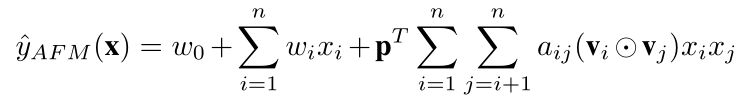 AFM核心代码如下:
AFM核心代码如下:
#输入层
self.feat_index = tf.placeholder(tf.int32,shape=[None,None],name='feat_index')
self.feat_value = tf.placeholder(tf.float32,shape=[None,None],name='feat_value')
self.label = tf.placeholder(tf.float32,shape=[None,1],name='label')
#Embedding层
self.embeddings = tf.nn.embedding_lookup(self.weights['feature_embeddings'],self.feat_index) # N * F * K
feat_value = tf.reshape(self.feat_value,shape=[-1,self.field_size,1])
self.embeddings = tf.multiply(self.embeddings,feat_value) # N * F * K
#element_wise product
element_wise_product_list = []
for i in range(self.field_size):
for j in range(i+1,self.field_size):
element_wise_product_list.append(tf.multiply(self.embeddings[:,i,:],self.embeddings[:,j,:])) # None * K
self.element_wise_product = tf.stack(element_wise_product_list) # (F * F - 1 / 2) * None * K
self.element_wise_product = tf.transpose(self.element_wise_product,perm=[1,0,2],name='element_wise_product') # None * (F * F - 1 / 2) * K
#attention层
num_interactions = int(self.field_size * (self.field_size - 1) / 2)
#wx+b -> relu(wx+b) -> h*relu(wx+b)
self.attention_wx_plus_b = tf.reshape(tf.add(tf.matmul(tf.reshape(self.element_wise_product,shape=(-1,self.embedding_size)),
self.weights['attention_w']),
self.weights['attention_b']),
shape=[-1,num_interactions,self.attention_size]) # N * ( F * F - 1 / 2) * A
self.attention_exp = tf.exp(tf.reduce_sum(tf.multiply(tf.nn.relu(self.attention_wx_plus_b),
self.weights['attention_h']),
axis=2,keep_dims=True)) # N * ( F * F - 1 / 2) * 1
self.attention_exp_sum = tf.reduce_sum(self.attention_exp,axis=1,keep_dims=True) # N * 1 * 1
self.attention_out = tf.div(self.attention_exp,self.attention_exp_sum,name='attention_out') # N * ( F * F - 1 / 2) * 1
self.attention_x_product = tf.reduce_sum(tf.multiply(self.attention_out,self.element_wise_product),axis=1,name='afm') # N * K
self.attention_part_sum = tf.matmul(self.attention_x_product,self.weights['attention_p']) # N * 1
#1-order
······
NFM
FM模型的限制:FM实际上是二阶交叉特征的加权求和,仍然是线性的,但是实际场景下的二阶交叉特征通常是highly non-linear,无法通过线性模型来很好的预估,因此FM的表达能力就有了较大的限制。NFM将二阶交叉特征的隐层空间进行非线性变换(Bi-Interaction and Pooling),从而将模型的二阶交叉特征非线性化。模型架构如下:
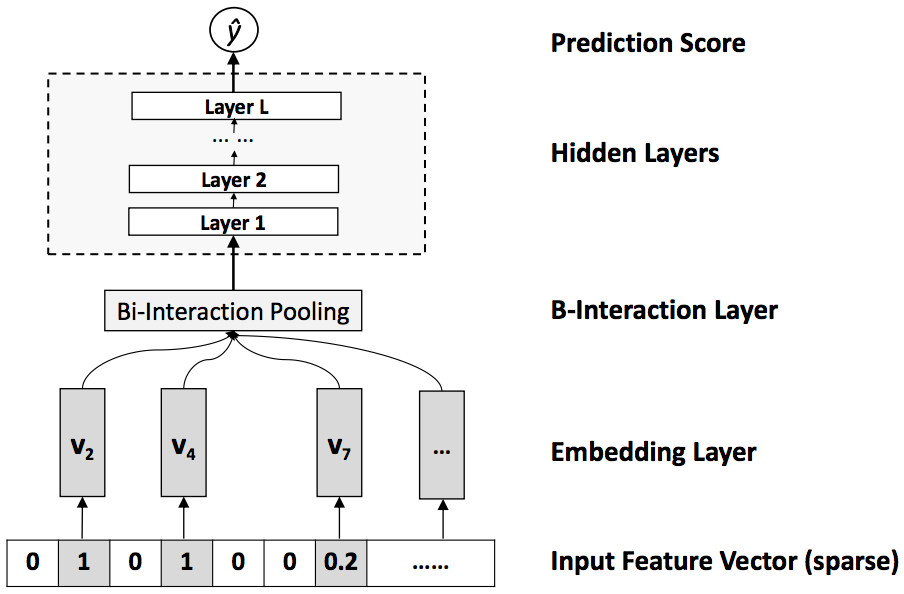
Bi-Interaction pooling
Bi-Interaction pooling,顾名思义,就是二阶交叉的同时做pooling,其计算公式如下:
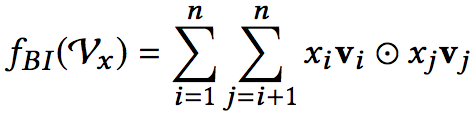 Bi-Interaction:将原始特征Embedding后得到的隐向量进行两两内积(按位点乘)。
pooling:经过两次加和操作即将一组Embedding向量转化成一个长度为k的向量。
Bi-Interaction:将原始特征Embedding后得到的隐向量进行两两内积(按位点乘)。
pooling:经过两次加和操作即将一组Embedding向量转化成一个长度为k的向量。
经过Bi-Interaction pooling后,再接MLP层来model高阶特征交互。