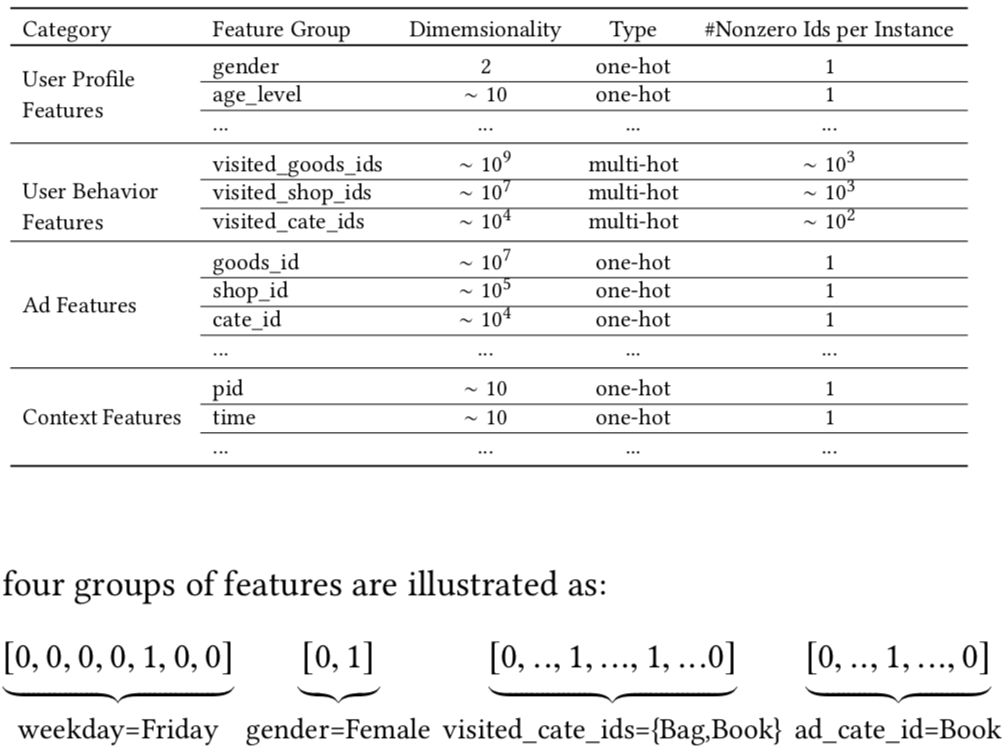
在具有丰富的用户行为的推荐场景中,特征通常包含有可变长度的ids list,比如YouTube推荐系统中的searched terms、watched videos,我们前面所讲的所有模型通常通过sum/average pooling将对应id的embedding向量矩阵转换为一个固定长度的向量,这样必然会造成信息的损失。举例来说,如果目标广告是咖啡相关的, 点击序列中有一个咖啡相关的广告,有10个服饰相关的广告,那么这个咖啡相关广告的信息很容易被忽略。并且有丰富行为的用户的购物兴趣是多种多样的,但是只是被局部激活。阿里巴巴推荐系统所用到的特征如下:
 传统模型中,对于用户点击过的商品(multi-hot feature vector),往往采用sum/avg pooling(element-wise sum/average operations on the list of embedding vectors)。采用这种方式的话,the user representation vector with a limited dimension will be a bottleneck to express user’s diverse interests。
传统模型中,对于用户点击过的商品(multi-hot feature vector),往往采用sum/avg pooling(element-wise sum/average operations on the list of embedding vectors)。采用这种方式的话,the user representation vector with a limited dimension will be a bottleneck to express user’s diverse interests。
模型架构
DIN模型通过计算候选商品与用户已购买过的每一个商品(historical be-haviors)之间的Attention来做soft-searching on her historical be-haviors。DIN模型架构如下:
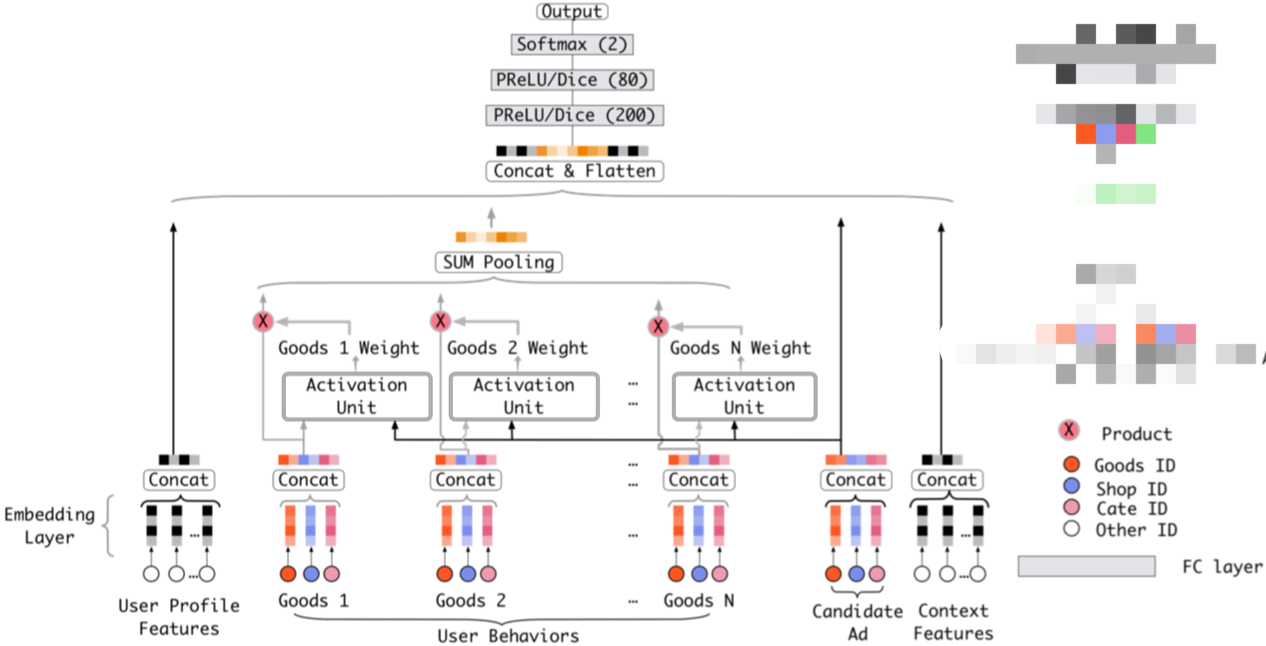 其中Attention(Activation Unit)结构为:
其中Attention(Activation Unit)结构为:
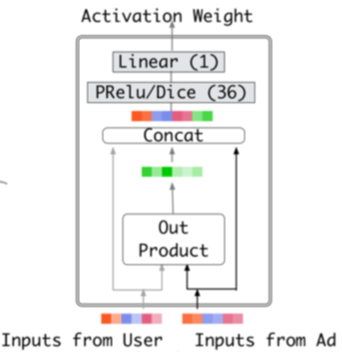 总体上看是一个MLP式的Attention,只是去掉了softmax层,旨在保留用户兴趣的强度。因为归一化后的权重求和是等于1的,这样的话,当所有的广告都与目标广告关系不大时,部分广告的权重由于归一化也会变得很大,而且辅助广告的数量也是会对归一化结果产生影响的。论文中也试验了用LSTM来model user historical behavior data in the sequential manner,但是没有明显效果。原因可能是因为用户的兴趣具有并发性、突发性、跳跃性,这样看来用户行为序列建模似乎成了噪声。
总体上看是一个MLP式的Attention,只是去掉了softmax层,旨在保留用户兴趣的强度。因为归一化后的权重求和是等于1的,这样的话,当所有的广告都与目标广告关系不大时,部分广告的权重由于归一化也会变得很大,而且辅助广告的数量也是会对归一化结果产生影响的。论文中也试验了用LSTM来model user historical behavior data in the sequential manner,但是没有明显效果。原因可能是因为用户的兴趣具有并发性、突发性、跳跃性,这样看来用户行为序列建模似乎成了噪声。
训练技巧
模型训练过程中也使用了两项黑科技,Mini-batch Aware Regularization和Data Adaptive Activation Function。
Mini-batch Aware Regularization
如果模型加入了高维稀疏特征(如one-hot),直接训练将导致严重的过拟合,这时候一般有以下几种处理方法:
- Dropout。即随机丢弃50%的feature ids in each sample。
- Filter。即将feature ids按照在所有样本中的出现次数排序,然后只取出现频率最高的top N的feature ids。
- Regularization。
但是传统的l1、l2正则化效果很差,因为传统的l1、l2正则在每个mini-batch训练过程中,会对所有参数计算l1/l2-norm,但是事实上Only parameters of non-zero sparse features appearing in each mini-batch needs to be updated,并且也只需要这部分参数参与计算l1/l2-norm。为了解决这个问题,本篇论文提出一种新颖的正则化方法MBA(Mini-batch Aware Regularization),自适应正则,即每次mini-batch,只在非0特征对应参数上计算L2正则(针对特征稀疏性),且正则强度与特征频次有关,频次越高正则强度越低,反之越高(针对特征长尾效应)。
Data Adaptive Activation Function
作者也对激活函数进行了改进,将原来的PRelu激活函数改为Dice。

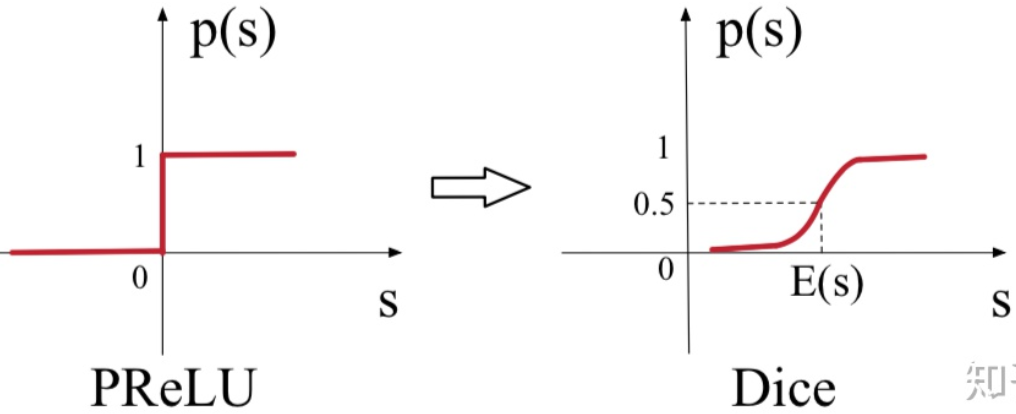 无论是ReLU还是PReLU,突变点都在0,论文里认为,对于所有输入不应该都选择0点为突变点,而是应该依赖于数据的。
无论是ReLU还是PReLU,突变点都在0,论文里认为,对于所有输入不应该都选择0点为突变点,而是应该依赖于数据的。
数据拆分与评测指标
对于CTR训练数据与测试数据的拆分,一般有以下几种形式:
- 按时序分隔。将用户购买过的商品按照时间顺序排列,取前n-2个商品作训练集,测试时输入前n-1个商品,预测最后一个是否会被用户购买。
- 按userid分隔。将所有数据按照userid先进行group,然后随机选取90%的userid所在的样本作训练集,剩下的用作测试集。
- 取前两周的所有购买数据作训练集,紧接着的其后两天的购买数据作测试集。
我们使用用户加权AUC来评测模型的效果,它通过对每个用户的AUC进行平均来衡量intra-user order的优劣。计算公式如下:
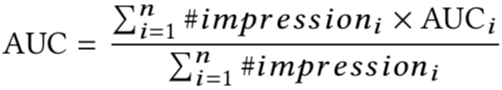 其中n代表用户数,#impressioni为曝光数或点击数,AUCi代表第i个用户的AUC。因为不同的用户活跃性不同,理论上活跃性越高的用户,其AUC更可信,所以权重越高,活跃性越低的用户,其单次点击可能有很大的偶然性,不能反映模型效果的好坏,所以降低其AUC权重。
其中n代表用户数,#impressioni为曝光数或点击数,AUCi代表第i个用户的AUC。因为不同的用户活跃性不同,理论上活跃性越高的用户,其AUC更可信,所以权重越高,活跃性越低的用户,其单次点击可能有很大的偶然性,不能反映模型效果的好坏,所以降低其AUC权重。
DIEN
顾名思义,DIEN是DIN的升级版,上面说到DIN试图用LSTM来model用户兴趣的演化,但是失败了,DIEN成功做到了,它通过两层GRU来model用户兴趣随着时间的演化过程。模型架构如下:
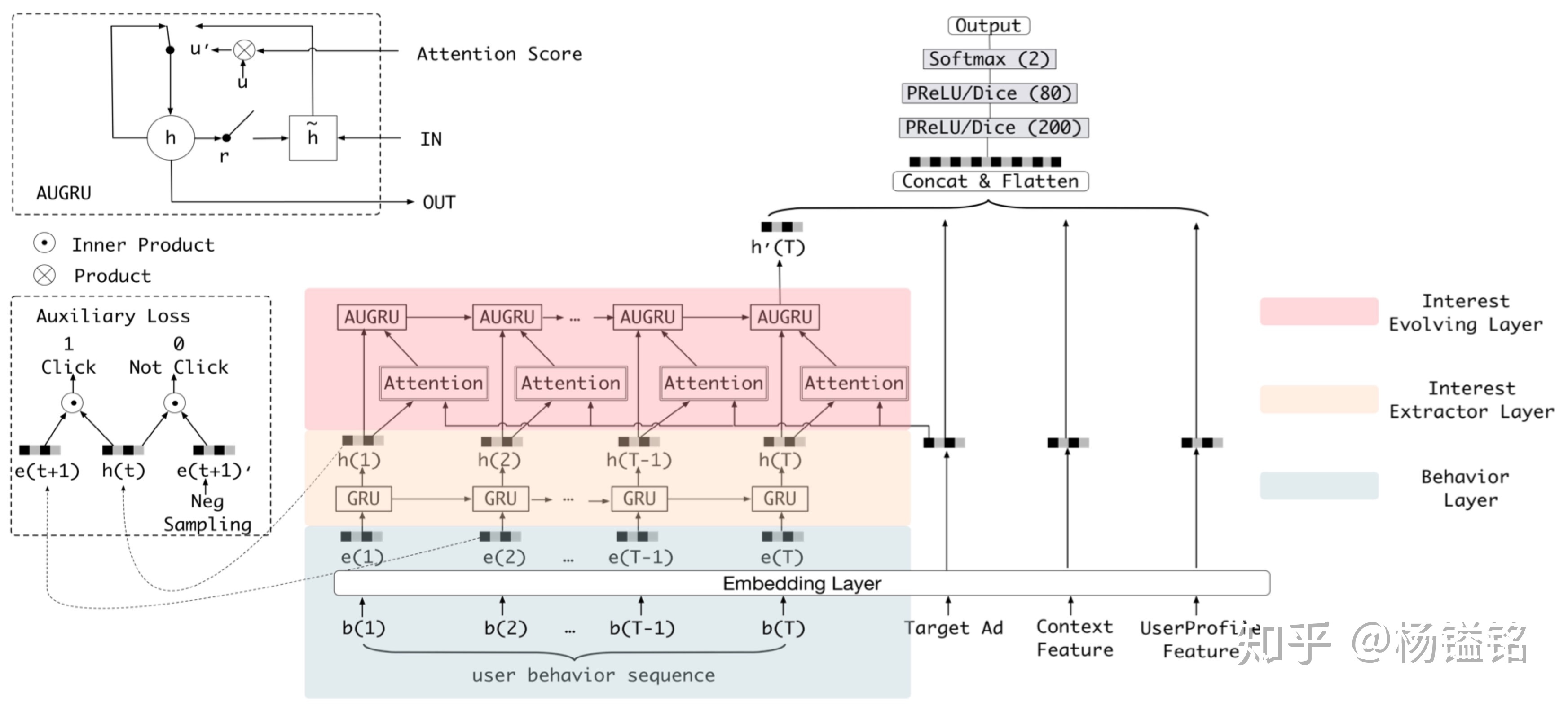 最下的Embedding层及最上的MLP层与之前的模型没有区别,用户行为建模主要包含两个核心模块:Interest Extractor Layer和Interest Evolving Layer。
最下的Embedding层及最上的MLP层与之前的模型没有区别,用户行为建模主要包含两个核心模块:Interest Extractor Layer和Interest Evolving Layer。
Interest Extractor Layer
在Interest Extractor层,模型使用GRU来对用户行为之间的依赖进行建模,GRU的输入是用户按时间排序的行为序列,也就是行为对应的商品。但是作者指出GRU只能学习行为之间的依赖,并不能很好的反映用户兴趣。所以模型引入了辅助loss,具体来说就是用t+1时刻的行为Bt+1来指导t时刻的隐状态Ht的学习,正样本就是真实的下一个item,负样本就是从曝光给该用户但该用户并没有点击中的item里采样(但具体是用户的所有曝光未点击的item还是单次下发曝光未点击的item,文中并未详细说明,如果是后者,可能存在时间穿越问题)。所以损失L = Ltarget + a * Lie。
辅助loss的引入有多个好处:
- 正如作者强调的,辅助loss可以帮助GRU的隐状态更好地表示用户兴趣。
- RNN在长序列建模场景下梯度传播可能并不能很好的影响到序列开始部分,如果在序列的每个部分都引入一个辅助的监督信号,则可一定程度降低优化难度。
- 辅助loss可以给embedding层的学习带来更多语义信息,学习到item对应的更好的embedding。
Interest Evolving Layer
这部分结合了注意力机制中的Local Activation和GRU的序列学习能力来实现建模兴趣演化的目标。attention部分的计算采用与DIN相同的形式,只不过最后多了softmax归一化。具体是如何将attention机制加到GRU中的呢?可以参见这篇文章 https://zhuanlan.zhihu.com/p/50758485,比较简单直观。