BST
BST(Behavior Sequence Transformer),其实就是通过Transformer取代了DIEN中的双层GRU,试图通过Transformer来更好的model用户兴趣随着时间的演化过程。模型架构如下:
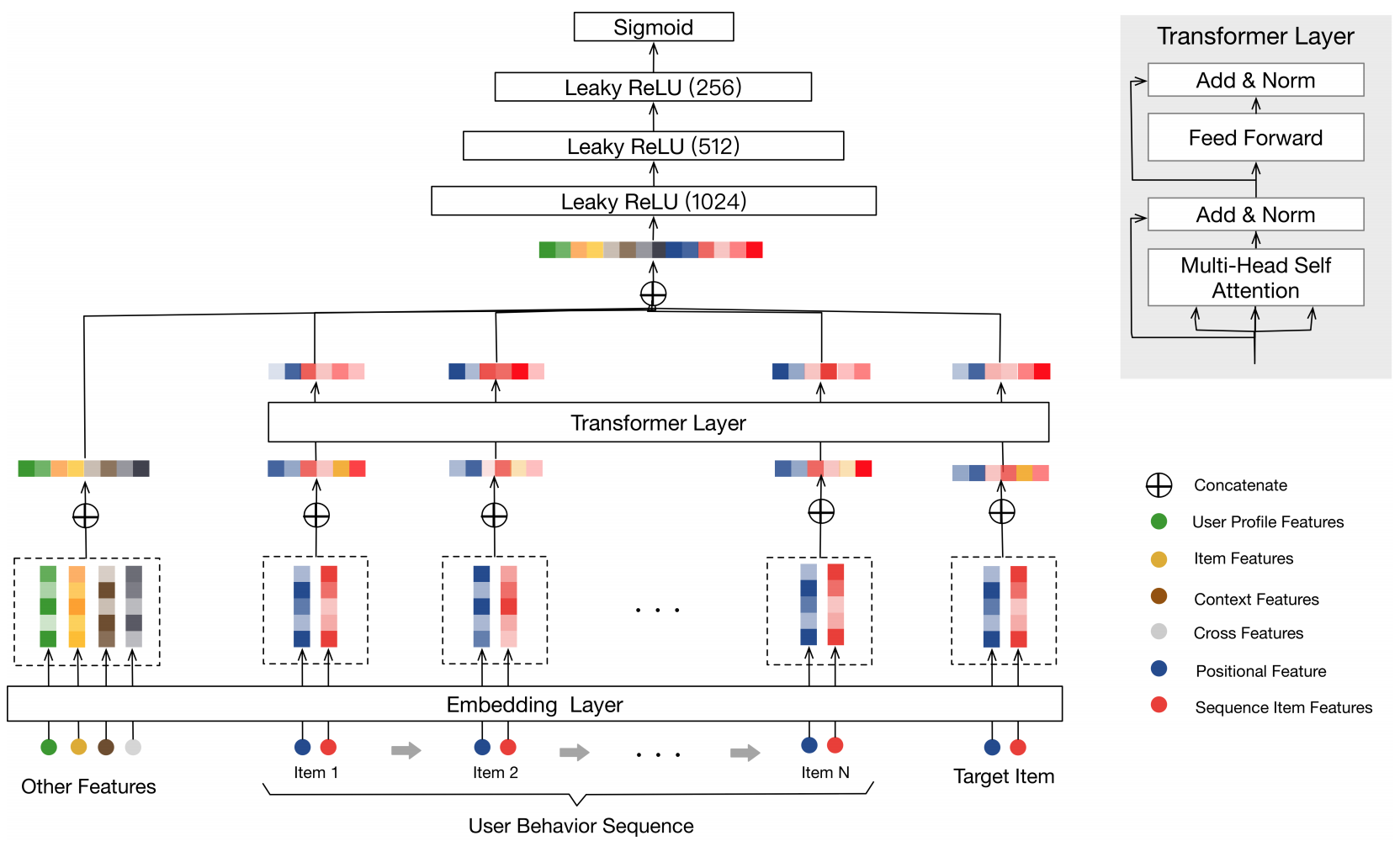 模型架构一目了然,除了引入Transformer之外,并没有太多其他创新的地方。唯一需要注意的就是position embedding的计算。位置特征用来刻画用户历史行为序列中的顺序信息,第i个位置的位置特征计算方式为:pos(vi)=t(vt)-t(vi),其中,t(vt)表示当前候选item,t(vi)表示用户点击商品vi时的时间戳(其实就是按照行为序列的开始时间和结束时间做2的幂次切片,如:(0,2],(2,4],(4,8],(8,16],看当前时间戳落在哪个时间片内)。
模型架构一目了然,除了引入Transformer之外,并没有太多其他创新的地方。唯一需要注意的就是position embedding的计算。位置特征用来刻画用户历史行为序列中的顺序信息,第i个位置的位置特征计算方式为:pos(vi)=t(vt)-t(vi),其中,t(vt)表示当前候选item,t(vi)表示用户点击商品vi时的时间戳(其实就是按照行为序列的开始时间和结束时间做2的幂次切片,如:(0,2],(2,4],(4,8],(8,16],看当前时间戳落在哪个时间片内)。
DSIN
DSIN(Deep Session Interest Network),将用户行为序列进一步细粒度化到session维度,因为同一个session内的行为高度同构(兴趣类似),不同session间的behavior异构,DSIN将这种信息也利用了起来,目的是抽取用户在每个session层面的interest,然后捕获session interest之间的用户行为序列关系。DSIN模型架构如下所示:
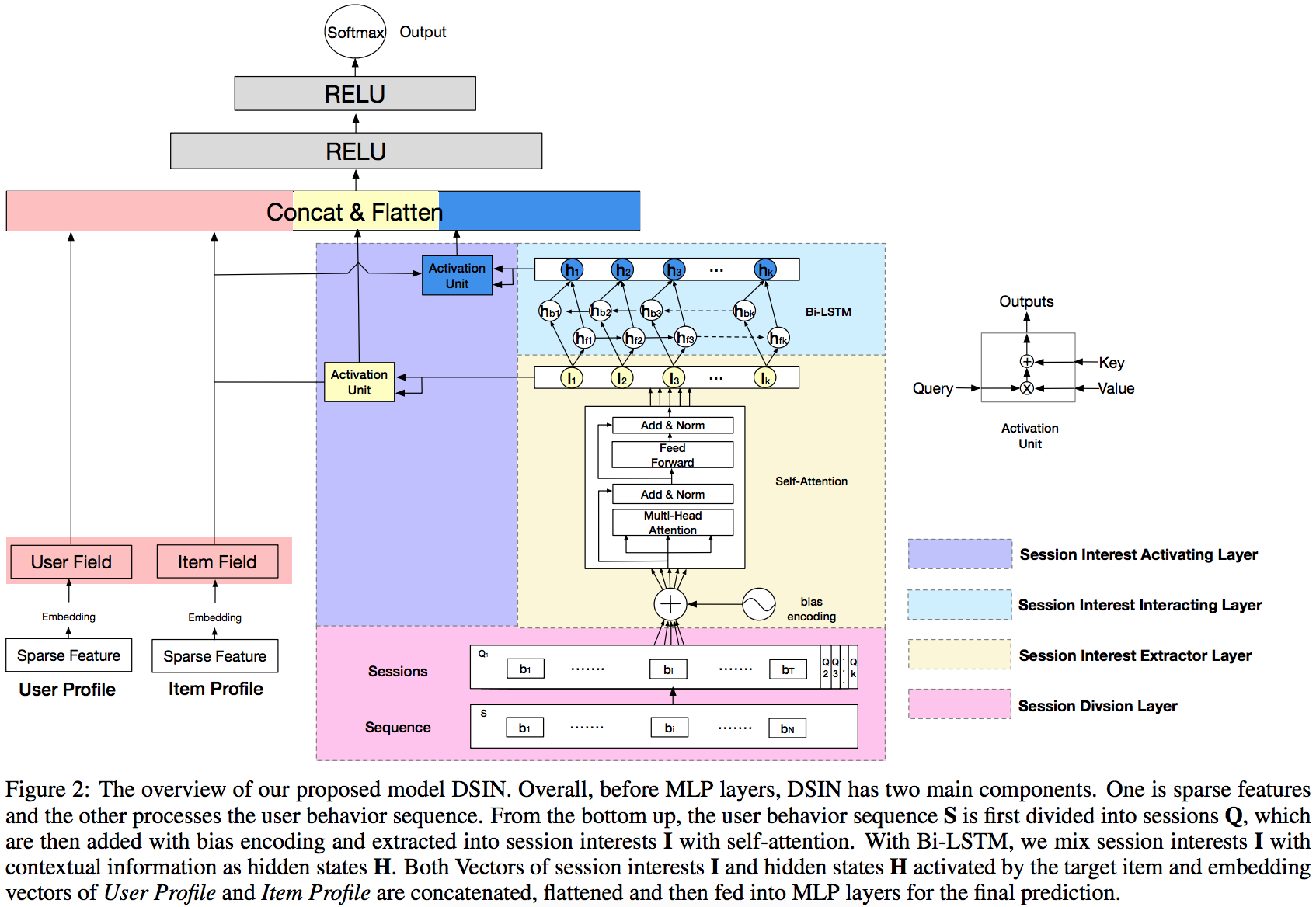 下面我们一层层的来看。
下面我们一层层的来看。
Session Division Layer
即根据特定规则将用户行为序列划分成多个session,一般是session间的时间间隔大于等于30min。相当于输入增加了一个维度变为n x s x t,n为用户数,s为每个用户的session数,t为每个session中的行为数。
Session Interest Extractor Layer
这一层的目的是寻找session内部的行为之间关系,来进一步提取session interest。即使同个session中的行为是高度同构的,但是还是会有一些随意的一些行为会使得session的兴趣表示变得不准确(比如我想买衣服,看着看着衣服,但不小心误触到其他推送内容,但那和我的真实想去点击的东西无关)。所以为了对同一session中多个行为的关系进行建模和减轻那些不相关行为的影响,注意在每个session内,使用Transformer来抽取每个session的兴趣特征。
不过在输入Transformer前还做了bias encoding,其实就是对Transformer中的position encoding做出了优化,命名为bias encoding(BE)。因为我们引入了session,所以需要考虑三层位置:每个用户有k个session,每个session又有t个behavior,每个behavior又有c个元素(向量维度)。所以bias encoding表达式为:
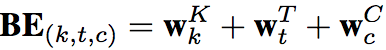 经过Transformer后的结果再在session维度做avg pooling得到每个session的interest向量表示。
经过Transformer后的结果再在session维度做avg pooling得到每个session的interest向量表示。
Session Interest Interacting Layer
在经过Session Interest Extractor Layer提取出每个session的interest后,很自然就会想要去捕获不同session之间的交互关系,这里使用Bi-LSTM来做这件事。
Session Interest Activating Layer
Item Profile(Item field)为商家ID、品牌ID的embedding,我们把跟商品i有关的特征考虑进来,跟用户的每一个session interest计算Attention score,最终通过softmax得到Attention weight。
对于跨session的interest,采用同样的做法。
ESMM
ESSM模型基于Multi-Task Learning的思路,提出一种新的CVR预估模型。不同于CTR预估问题,CVR(conversion rate,转化率)预估面临着两个关键问题:
- Sample Selection Bias(SSB):转化是在点击之后才“有可能”发生的动作,传统CVR模型通常以点击数据为训练集,其中点击未转化为负例,点击并转化为正例。但是训练好的模型实际使用时,则是对整个空间(曝光)的样本进行预估,而非只对点击样本进行预估。也就是说,训练数据与实际要预测的数据来自不同分布,这个偏差对模型的泛化能力构成了很大挑战。
- Data Sparsity(DS):作为CVR训练数据的点击样本远小于CTR预估训练使用的曝光样本。
当然一些策略可以缓解这两个问题:
- 从曝光集中对unclicked样本抽样做负例缓解SSB。这样做会很大程度上误导CVR模型的学习,因为那些unclicked的item,假设他们被user点击了,它们是否会被转化是不知道的,所以不能直接使用0作为它们的label。
- 对转化样本过采样缓解DS。
- 最常用的还是分别训练CTR和CVR模型,然后在Serving时使用二者的乘积作为最终的期望转化率。
但无论哪种方法,都没有很优雅地从实质上解决上面任一个问题。可以看到,点击—>转化,本身是两个强相关的连续行为,作者希望在模型结构中显示考虑这种“行为链关系”,从而可以在整个空间上进行训练及预测。这涉及到CTR与CVR两个任务,因此使用多任务迁移学习是一个自然的选择。
认识到点击(CTR)、转化(CVR)、点击并转化(CTCVR)是三个不同的任务后,我们再来看三者的关联:
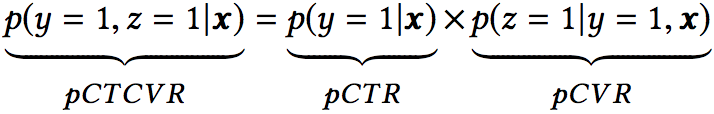 其中z和y分别表示conversion和click(其实GMV = 流量×点击率×转化率×客单价,不同场景使用的排序因子不一样,比如按点击付费的广告系统,主要排序分是ctr x bid_price;以最大化GMV为目标的场景,主要排序分是ctr x cvr x price)。
其中z和y分别表示conversion和click(其实GMV = 流量×点击率×转化率×客单价,不同场景使用的排序因子不一样,比如按点击付费的广告系统,主要排序分是ctr x bid_price;以最大化GMV为目标的场景,主要排序分是ctr x cvr x price)。
在全部样本空间中,CTR对应的label为click,而CTCVR对应的label为click & conversion,这两个任务是可以使用全部样本的,ESMM正是这么做的,将CTR与CVR通过Multi-Task迁移学习同时训练,模型结构如下所示:
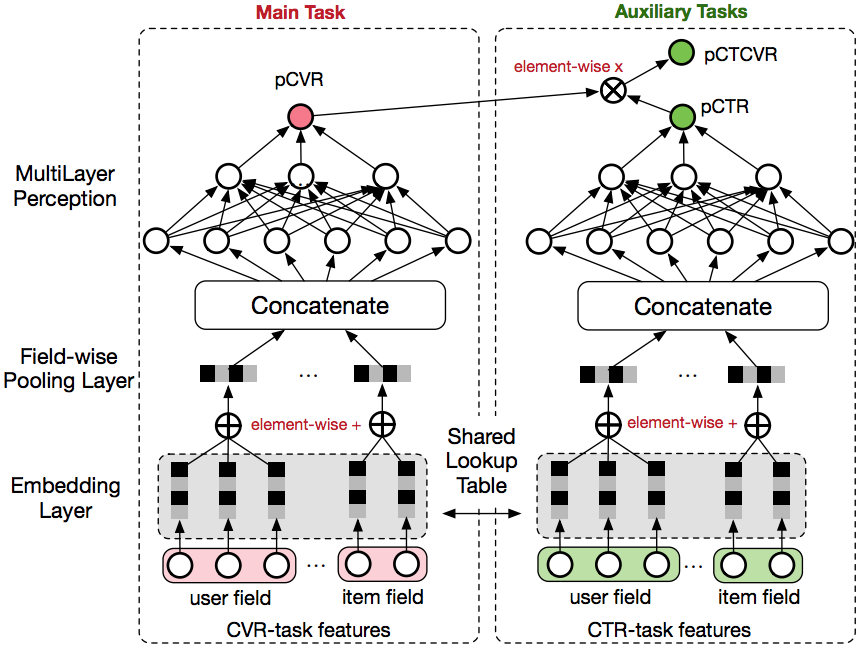 模型结构清晰,一目了然。核心在以下几点:
模型结构清晰,一目了然。核心在以下几点:
- 共享Embedding:在模型的最底层,CVR-task和CTR-task共享特征embedding,即两者从Concatenate之后才学习各自部分独享的参数。
- 隐式学习pCVR:这里pCVR(粉色节点)仅是网络中的一个node,没有显示的监督信号。即利用CTCVR和CTR的监督信息来训练网络(绿色节点),隐式地学习CVR。这样做可以非常有效的避免SSB和DS问题,即ctr的负样本一定是ctcvr的负样本,但对于cvr来说并不知道是正样本还是负样本,所以这里cvr只是一个辅助网络,并没有对应的loss。
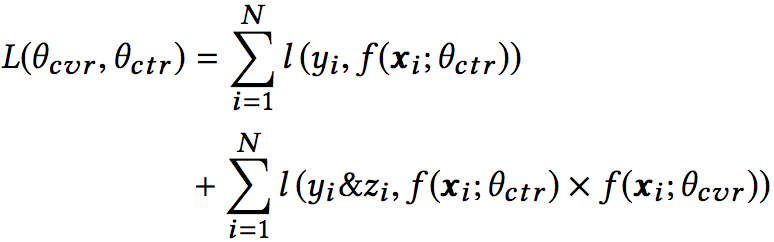 其实样本当中大部分都是click or impression的数据,存在cvr的标签太少了,这带来一个问题,由于embedding共享,而过多的关于ctr的数据导致模型最终训练出来的embedding更倾向于ctr,对cvr预测造成影响,所以使用权值来平衡两个loss,效果会好一些。
其实样本当中大部分都是click or impression的数据,存在cvr的标签太少了,这带来一个问题,由于embedding共享,而过多的关于ctr的数据导致模型最终训练出来的embedding更倾向于ctr,对cvr预测造成影响,所以使用权值来平衡两个loss,效果会好一些。 - 实际上线Serving时,拿到红色节点的值就是CVR,模型最终的输出结果就是CTCVR,另外一个绿色节点的值就是CTR。
模型同时计算两个衡量指标:
- 在点击样本上,计算CVR任务的AUC。
- 在全部样本上计算CTCVR任务的AUC。
ESMM模型同时解决了“训练空间和预测空间不一致”以及“同时利用点击和转化数据进行全局优化”两个关键的问题。其实举一反三的看,YouTube视频推荐也可以借鉴ESMM模型,视频曝光—>点击—>播放时长预估,播放度按时长分桶转换成分类模型或者使用weight logistic Regression。