Facebook CTR预估模型
说到CTR,不得不提Facebook的经典的GBDT+LR,利用GBDT自动进行特征筛选和组合,进而生成新的feature vector,再把该feature vector当作logistic regression的模型输入,预测CTR。大家知道,GBDT是由多棵回归树组成的树林,后一棵树利用前面树林的结果与真实结果的残差做为拟合目标。每棵树生成的过程是一棵标准的回归树生成过程,因此每个节点的分裂是一个自然的特征选择的过程,而多层节点的结构自然进行了有效的特征组合,也就非常高效的解决了过去非常棘手的特征选择和特征组合的问题。
首先利用训练集训练好GBDT模型,之后就可以利用该模型构建特征工程。具体过程是这样的,一个样本在输入GBDT的某一子树后,会根据每个节点的规则最终落入某一叶子节点,那么我们把该叶子节点置为1,其他叶子节点置为0,所有叶子节点组成的向量即形成了该棵树的特征向量,把GBDT所有子树的特征向量concatenate起来,即形成了后续LR输入的特征向量。举例来说,比如GBDT由三颗子树构成,每个子树有4个叶子节点,一个训练样本进来后,先后落到了“子树1”的第3个叶节点中,那么特征向量就是[0,0,1,0],“子树2”的第1个叶节点,特征向量为[1,0,0,0],“子树3”的第4个叶节点,特征向量为[0,0,0,1],最后concatenate所有特征向量,形成的最终的特征向量为[0,0,1,0,1,0,0,0,0,0,0,1],我们再把该向量作为LR的输入,预测CTR。
GBDT+LR在当时影响深远,虽然现在早已过时,但是其中的思想仍然非常值得借鉴,比如以下几个方面。
online learning和serving
线上的实时推荐系统一般采用kafka或flink把来自不同数据流的数据整合起来形成sample features,并最终与click数据进行多流join,形成完整的labeled sample。在整个过程中,应该注意以下几点:
- waiting window的设定。waiting window指的是在impression(曝光)发生后,我们要等待多久才能够判定一个impression是否有click。如果waiting window过大,数据实时性受影响,如果waiting window过小,会有一部分click来不及join到impression,导致样本CTR与真实值不符。这是一个工程调优的问题,需要有针对性的找到跟实际业务匹配的合适的waiting window。除此之外,无论怎样我们都会漏掉一部分click,这就要求我们阶段性的全量retrain我们的模型,避免online learning误差的积累。
- 分布式的架构与全局统一的action id。为了实现分布式架构下impression记录和click记录的join,facebook除了为每个action建立全局统一的request id外,还建立了HashQueue缓存impressions。hashQueue缓存的impression,如果在窗口过期时还没有匹配到click就会当作negative sample,这里说的窗口与上面提到的waiting window相匹配。
- 数据流保护机制。facebook专门提到了online data joiner的保护机制,因为一旦data joiner失效,比如click stream无法join impression stream,那么所有的样本都会成为负样本,由于模型实时进行online learning和serving,模型准确度将立刻受到错误样本数据的影响。为此,facebook专门设立了异常数据流检测机制,一旦发现实时样本数据流的分布发生变化,将立即切断online learning的过程,防止预测模型受到影响。
降采样
推荐系统中往往正负样本严重不均衡,负样本比例一般是正样本的十倍甚至以上,对于大型互联网公司来说,为了控制数据规模,降低训练开销,并且提升训练效果,降采样几乎是通用的手段,facebook实践了两种降采样的方法,uniform subsampling和 negative down sampling。uniform subsampling是对所有样本进行无差别的随机抽样,negative down sampling是保留全量正样本,对负样本进行降采样。
一般来讲,test set不需要负采样,因为我们希望test set尽量与线上数据保持一致。validation set一般在训练的时候需要负采样。
模型校正
负采样带来的副作用是CTR预估值的漂移,比如真实CTR是0.1%,进行0.01的负采样之后,CTR将会攀升到10%左右。而为了进行准确的竞价以及ROI预估等,CTR预估模型是要提供准确的有物理意义的CTR值的,因此在进行负采样后需要进行CTR的校正,使CTR模型的预估值的期望回到0.1%。校正的公式如下:
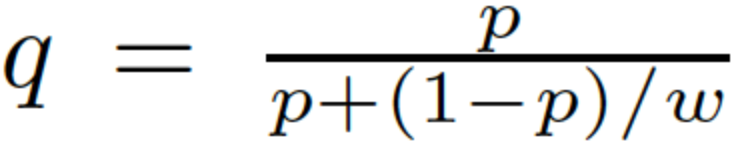 其中q是校正后的CTR,p是模型的预估CTR,w是负采样频率(指每间隔1/w个样本,取一个)。
其中q是校正后的CTR,p是模型的预估CTR,w是负采样频率(指每间隔1/w个样本,取一个)。
还可以通过保序回归进行CTR校准,参见: https://blog.csdn.net/u013019431/article/details/102473137
特征重要性
特征重要性可以帮助我们更好的认识不同特征的作用,对后期模型迭代也有意义。下面是特征重要性测试的常用方法:
- Ablation Test:每次去除一个特征,重新训练模型,然后观察效果的diff。但是这种方法也有问题,因为删去某个特征之后,由于特征集合存在冗余,模型能能力进行弥补,即使效果降低很少也并不意味着特征不重要。
- Permutation Test:这种方法最初是在随机森林中用来衡量特征重要性。针对某个特征,将测试集合中的取值随机打散,然后观察模型效果下降。显然,如果特征越重要,模型效果下降越明显。但是这种做法得到的结果并不能是很合理。因为特征之间往往并不独立,对特征取值进行打散可能产生的样本并不符合实际,这一个不切实际的样本空间上学习到的结果因此也并不可信。
YouTube视频推荐
YouTube视频推荐无论在算法设计还是工程实践上都非常具有借鉴意义,其在召回和排序模块都使用了深度学习。
在对训练数据的预处理上,YouTube对每个用户提取等数量的训练样本,以减少高度活跃用户对于loss的过度影响。在处理测试集的时候,YouTube不采用经典的随机留一法(random holdout),而是一定要把用户最近的一次观看行为作为测试集,这样做主要是为了避免引入future information,产生与事实不符的数据穿越。
召回
召回模块完成候选视频的快速筛选,这一步从百万量级的视频库中筛选出数百个候选视频。模型架构如下:
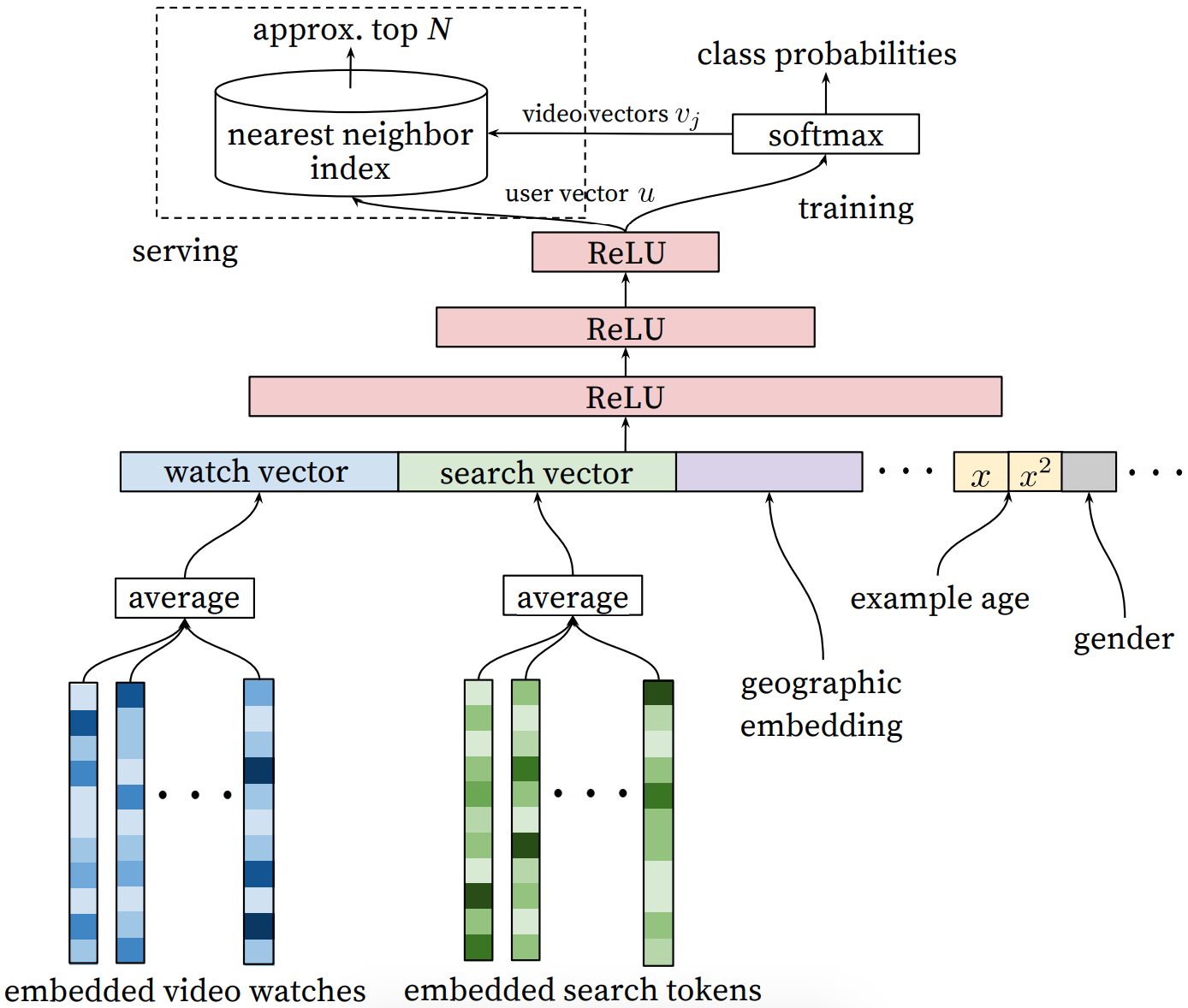 模型架构比较简单,最下层是watched-vedios embeddings和searched-tokens embeddings分别做average(这里可根据重要性和时间进行加权平均),再和地理位置的embedding、年龄、性别(这里的x的平方表示作者所做的特征工程)等做concat,然后把所有这些特征喂给上层的三层ReLU神经网络。最后是softmax,作者把推荐看成是next which one be watched,所以用一个简单的分类任务输出在所有candidate videos上的概率分布。
模型架构比较简单,最下层是watched-vedios embeddings和searched-tokens embeddings分别做average(这里可根据重要性和时间进行加权平均),再和地理位置的embedding、年龄、性别(这里的x的平方表示作者所做的特征工程)等做concat,然后把所有这些特征喂给上层的三层ReLU神经网络。最后是softmax,作者把推荐看成是next which one be watched,所以用一个简单的分类任务输出在所有candidate videos上的概率分布。
文中把推荐问题转换成分类问题,在预测next watch的场景下,每一个备选video都会是一个类别,因此总共的类别有数百万之巨,这在使用softmax训练时无疑是低效的,这个问题YouTube是如何解决的?作者其实进行了负采样(类似于word2vec中的技术)并用importance weighting的方法对采样进行校准。论文中同样介绍了一种替代方法,hierarchical softmax,但并没有取得更好的效果。
虽然在训练时进行了负采样等操作,但是上线Serving时,softmax仍然是相当低效的(即使softmax能够一次计算出几百万个score,这样的时间复杂度还是过高,softmax逐个进行向量内积运算加排序,复杂度应该是nlogn级别的,但使用LSH这种ANN(Approximate Nearest Neighbor)算法,建立索引后的复杂度可以低到logN甚至常数级别),因此在通过三层RELU得到user的embedding之后,直接和video的embedding进行最近邻搜索,效率要高很多。做法和dssm类似,都是通过内积限制两个embedding在相同空间。根据用户每次刷新的状态去输入到网络中得到的最后一层向量作为user vector,可以做到实时反馈,每次最新的浏览点击都能反馈到输入层进而得到不同的user vector(Serving时)。而video vector则是Softmax层的权重w(video_size * embedding_dim)直接作为videos的vector embedding矩阵,跟word_vec的训练方法如出一辙。Serving时通过实时输入数据到模型得到user vector(三层RELU后的向量结果),再与所有video vector计算内积取top N。
这里在进行video embedding的时候,直接把大量长尾的video用全0向量代替。主要还是为了节省online serving中宝贵的内存资源,当然从模型角度讲,低频video的embedding的准确性不佳是另一个“截断掉也不那么可惜”的理由。
模型还引入了“Example Age”这个feature来拟合用户对新视频的偏好。按照论文猜测,example age应该是sample log距离当前的时间,比如24小时前的日志,这个example age就是24,在做模型serving的时候,不管使用哪个video,会直接把这个feature设成0。
其实上述召回方式有一个很明显的缺点就是,没有办法引入item相关的feature。所以近几年来,召回模型升级为了双塔模型,架构如下:
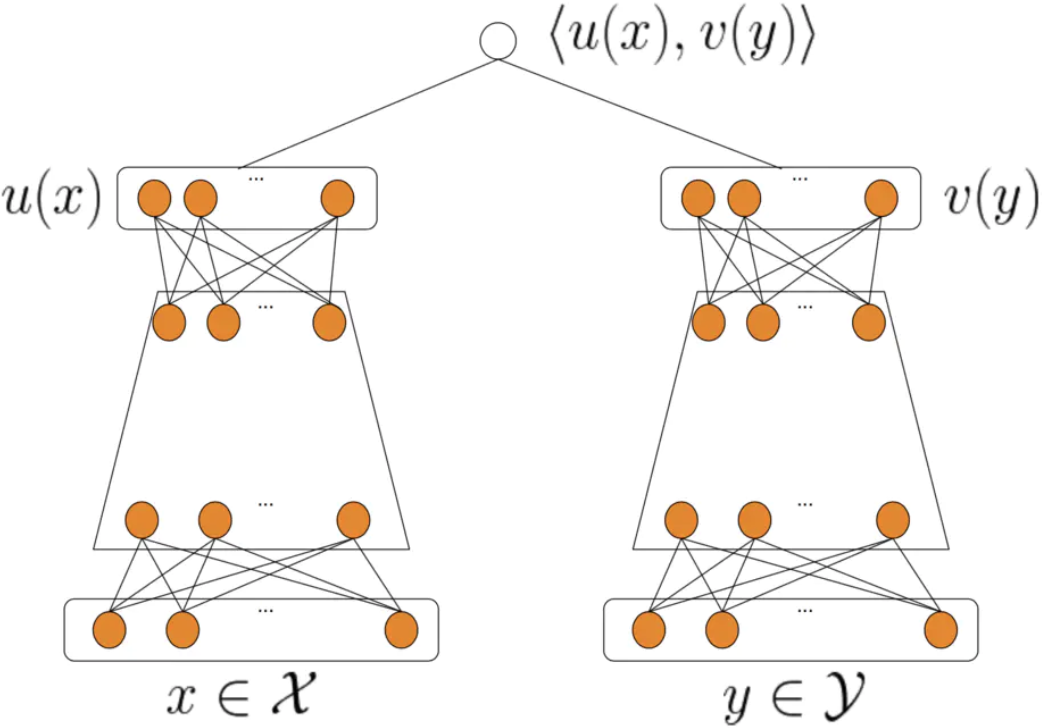 可以看到,双塔模型的左侧X为{用户,上下文}特征,右侧Y为{物品}特征,并在最后一层通过计算二者的内积,得到相似性得分。当模型训练完成后,固定模型参数,将item特征输入模型得到v(y),即是物品的embedding,该embedding是可以保存成词表的,线上应用的时候同样使用最近邻搜索做召回。
可以看到,双塔模型的左侧X为{用户,上下文}特征,右侧Y为{物品}特征,并在最后一层通过计算二者的内积,得到相似性得分。当模型训练完成后,固定模型参数,将item特征输入模型得到v(y),即是物品的embedding,该embedding是可以保存成词表的,线上应用的时候同样使用最近邻搜索做召回。
排序
经过召回模块得到了几百个候选,下一步就是利用ranking模型进行精排。模型架构如下:
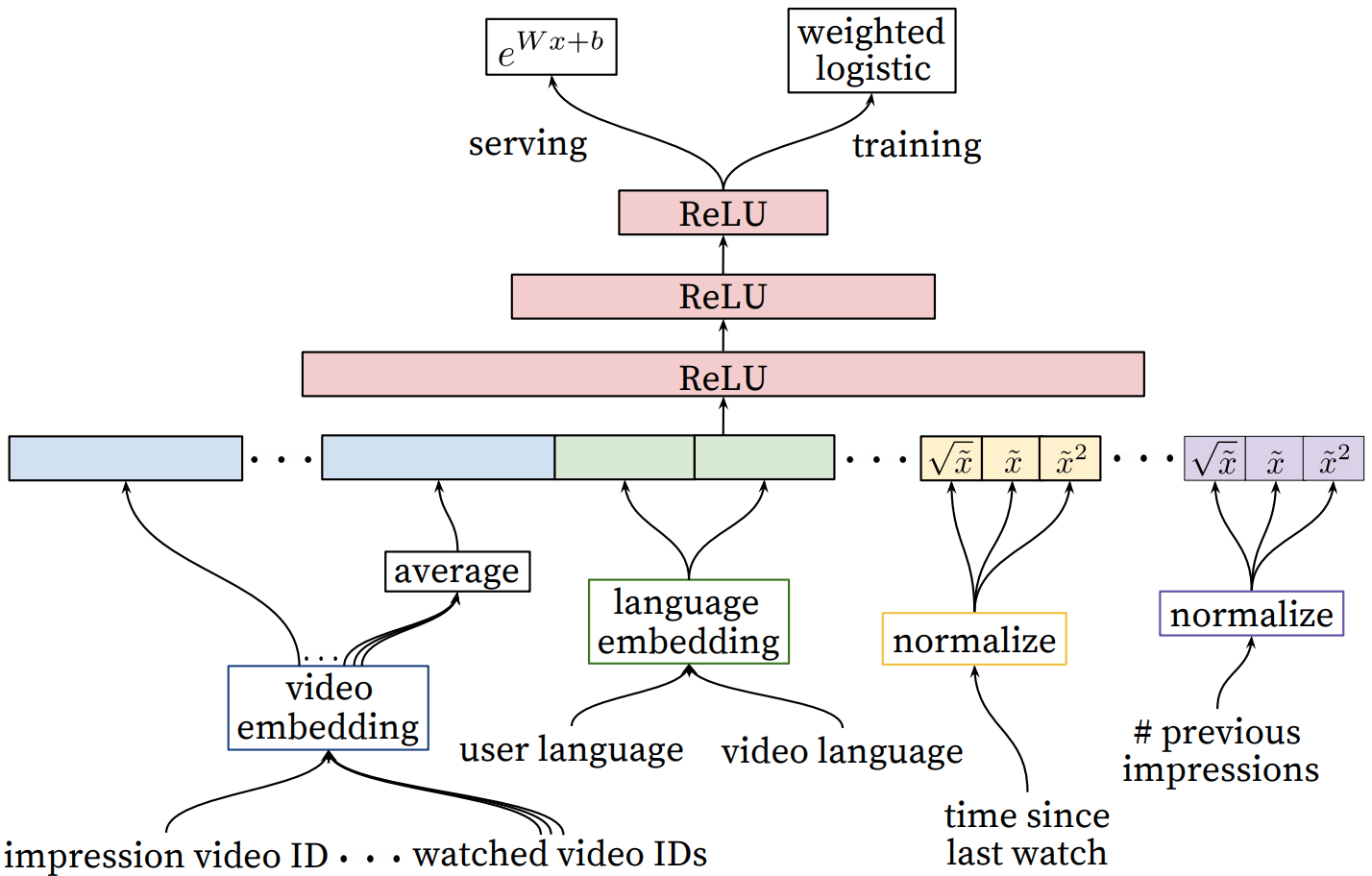 从左到右的特征依次是:
从左到右的特征依次是:
- impression video ID embedding: 当前要打分的video的embedding。
- watched video IDs average embedding: 用户观看过的最后N个视频embedding的average pooling。
- language embedding: 用户语言的embedding和当前视频语言的embedding。
- time since last watch: 自上次观看同channel视频的时间。假如我们刚看过“DOTA经典回顾”这个channel的视频,我们很大概率是会继续看这个channel的视频的,那么该特征就很好的捕捉到了这一用户行为。
- #previous impressions: 浏览该频道的次数。
对于最后两个特征,还进行了归一化处理,因为神经网络对输入特征的尺度和分布都是非常敏感的,基本上除了Tree-Based的模型(比如GBDT/RF),机器学习的大多算法都如此,严格来说,凡是通过梯度下降进行模型训练的算法都需要对特征做归一化处理,因为归一化利于梯度下降。归一化后又进行开根号、平方变换等操作,相当于给模型加入了非线性因素,使模型具有更好的表达能力。
在确定优化目标的时候,YouTube不采用经典的CTR或者播放率(Play Rate),而是采用了视频的预期播放时间作为优化目标。因为一方面watch time更能反应用户的真实兴趣;另一方面watch time越长,YouTube获得的广告收益越多(可以看到,优化目标的设定既要满足模型的效果,又要能直接反映商业价值)。
weighted logistic regression
对于视频播放时间的预测,采用了weighted logistic regression。为什么不把视频播放时间直接作为label训练线性回归模型,这不是更直接吗?其实回归有一个问题在于值域是负无穷到正无穷,在视频推荐这样一个大量观看时间为0的数据场景,为了优化MSE,很可能会把观看时间预测为负值,而在其他数据场景下又可能预测为超大正值。逻辑回归在这方面的优势在于值域在0到1,对于数据兼容性比较好。
YouTube推荐的Weighted LR中,正样本的Weight就是观看时长T,负样本weight为1。Weighted LR与LR的不同,主要体现在训练方式上,训练Weighted LR一般来说有以下两种办法:
- 将正样本按照weight做重复sampling,然后输入模型进行训练。
- 在训练过程中,如果输入是正样本,那么梯度下降时,梯度要乘以weight倍后,再更新。
其实可以看到,Weighted LR是一种非常好的处理样本不均衡的方法。上面这两种训练方法得到的结果是不一样的。对于第一种方法,把一条样本repeat 10次,这样在优化的过程中,每遇到一次该样本,就会用梯度更新一次参数,然后用更新后的参数再去计算下一条样本上的梯度,如此逐步计算并更新梯度10次;但对于第二种方法,则是一次性更新了单条梯度乘以10这么多的梯度,是一种一次到位的做法。直观一些来讲,第一种方法更像是给予一条样本10倍的关注,愿意花更多时间和精力来对待这条样本,是一种更细致的方法;第二种则比较粗暴了,不愿意花太多功夫,直接更新你10倍。
为什么线上serving时,e(Wx+b)的结果是expected watch time的近似?在逻辑回归一节中,我们知道Wx+b = ln(p/(1-p)),p是点击概率也即逻辑回归的预测值,我们令odds = p/(1-p)。又因为正样本权重T(观看时长)的加入会让正样本发生的几率变成原来的T倍(实际上是odds变为了原来的T倍,假设原本有a1个正样本,a0个负样本,那么p = a1/(a0+a1),现在负样本数不变,正样本数为T * a1,可以证明得到结论),所以现在e(Wx+b) = T * p/(1-p)。由于在视频推荐场景中,用户打开一个视频的概率p往往是一个很小的值,因此上式可以继续简化为e(Wx+b) = pT(约等于),该值的含义也就是用户对某视频的期望观看时长。其实只是因为期望观看时长对预测收入有用,所以线上serving时,取e(Wx+b)的结果,如果不需要预测收入,直接用模型的输出值做排序即可。
由此我们可以衍生到结合商品价格的商品推荐场景,目前的主流方式是先对CTR做预估,然后乘上商品价格,再排序。如果将商品价格作为正样本权重,负样本也权重设为1,是否也是可行的呢?we will see。但是个人感觉这是两个不同的场景,观看时长可以代表用户对item的感兴趣程度,所以用来对正样本加权,但不能用价格高低来衡量用户对商品的感兴趣程度,这样serving出来的排序结果很可能会把冷门但是高价的商品排在前面。