Airbnb作为全球最大的短租网站,提供了一个连接房主(host)挂出的短租房(listing)和主要以旅游为目的的租客(guest/user)的中介平台。Airbnb基于user的点击(click)及预订(booking)等交互行为数据构建了一个real time的Search ranking model(搜索排序模型)。为了捕捉到user的short term以及long term的兴趣,Airbnb并没有把user behavior history的clicked listing ids或者booked listing ids直接输入ranking model,而是先对user和listing进行了embedding,进而利用embedding的结果构建出诸多feature,作为ranking model的输入。
文章生成两种类型的embedding分别capture用户的short term和long term的兴趣:
- 通过click session数据生成listing的embedding,生成这个embedding的目的是为了召回相似的listing,以及对用户进行session内的实时个性化推荐。
- 通过booking session生成user-type embedding和listing-type embedding,目的是捕捉不同user-type的long term喜好。
召回
上面说到,召回是通过计算listing embedding的相似度完成。
listing embedding
Airbnb采用了一个session内,用户点击的listing的序列数据,对listing进行embedding。session间隔还是取30分钟,并且去掉停留时间小于30s的listing page,避免偶然的噪声,最后也丢弃了长度仅为1的session sequence。Airbnb把click session分成两类:最终产生booking行为的叫booked session(每个booked session只有最后一个listing是booked listing),没有的称做exploratory session,论文中还将booked session过采样了5倍以缓解样本不均衡。有了由clicked listings组成的sequence,就可以把这个sequence当作一个“句子”样本,开始“Word” embedding的过程。这是一种极其聪明的做法,因为用户在预定的时候自然会考虑price、listing-type,甚至listing的风格信息等,所以最终的embedding能够把所有这些信息都encode进去。Airbnb不出意外的选择了word2vec的skip-gram model来训练listing embedding,并通过修改word2vec的目标函数使其更靠近Airbnb的业务目标。
Airbnb的工程师从session sliding window中选取正样本,负样本则是在确定central listing后随机从语料库(这里就是不在当前window中的listing的集合)中选取。紧接着,针对其业务特点,为了使booked session中的所有listing embedding更倾向于被booking的那个listing,我们不管这个booked listing在不在word2vec的滑动窗口中,我们都会把这个booked listing加到滑动窗口的末尾:
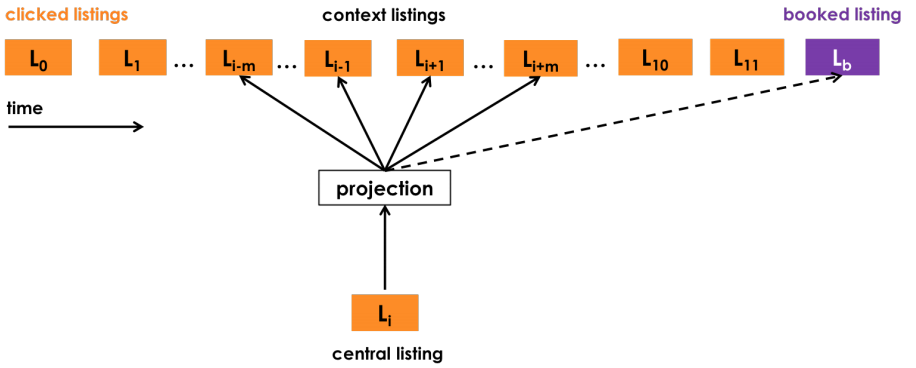 所以相当于引入了一个global context到objective中,因此objective就变成了下面的样子:
所以相当于引入了一个global context到objective中,因此objective就变成了下面的样子:
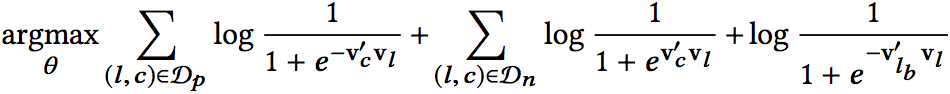 其中,Dp是正样本集合,Dn是负样本集合,l表示central listing,c表示context,lb就代表booked listing。上面的公式是针对单个sequence。
其中,Dp是正样本集合,Dn是负样本集合,l表示central listing,c表示context,lb就代表booked listing。上面的公式是针对单个sequence。
另外,针对其业务特点,同一市场(marketplace)内部的listing之间应该尽量差异最大化,Airbnb加入了另一组negative sample,就是把与在central listing同一市场的其他所有listing作为负样本。于是最终的objective就变成了下面的样子:
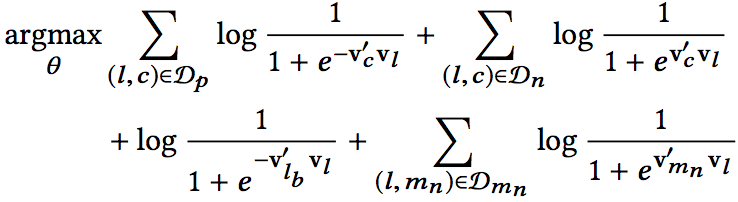 其中Dmn就是与central listing处在同一marketplace的所有其他listing集合。对每一种negative sample,还可以有不同的权重,代表不同的重要性,实验中可以灵活调节。
其中Dmn就是与central listing处在同一marketplace的所有其他listing集合。对每一种negative sample,还可以有不同的权重,代表不同的重要性,实验中可以灵活调节。
至此,就可以通过训练word2vec的skip-gram model来得到listing的embedding。除此之外,文章还多介绍了一下cold start的问题。简言之,如果有new listing缺失embedding vector,就找附近的3个同样类型、相似价格的listing embedding进行平均得到,不失为一个实用的工程经验。
user-type & listing-type embedding
Airbnb利用用户的session级的短期兴趣(同session内的点击高度同构),使用用户的点击数据构建了listing embedding,基于该embedding,可以很好的找出相似listing。为了捕捉用户的长期偏好,airbnb将用户的所有booking session组织起来,然后基于某些属性规则做相似user和相似listing的聚合。具体是怎么做的呢?假设listing的所有属性如下:
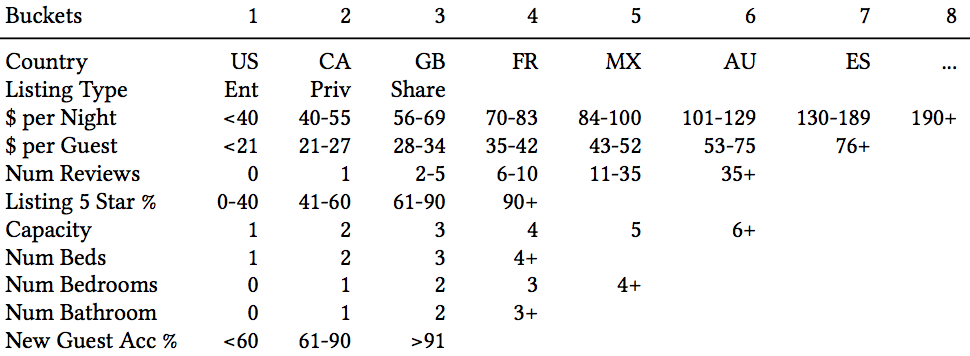 那么我们就可以用所有属性以及该属性的所有可能取值(用bucket id代替)组成一个list_type,比如说某个listing的国家是US、类型是Ent(bucket 1)、每晚的价格是56-59美金(bucket3),那么就可以用US_lt1_pn3来表示该listing的listing_type。user_type采用同样的做法:
那么我们就可以用所有属性以及该属性的所有可能取值(用bucket id代替)组成一个list_type,比如说某个listing的国家是US、类型是Ent(bucket 1)、每晚的价格是56-59美金(bucket3),那么就可以用US_lt1_pn3来表示该listing的listing_type。user_type采用同样的做法:
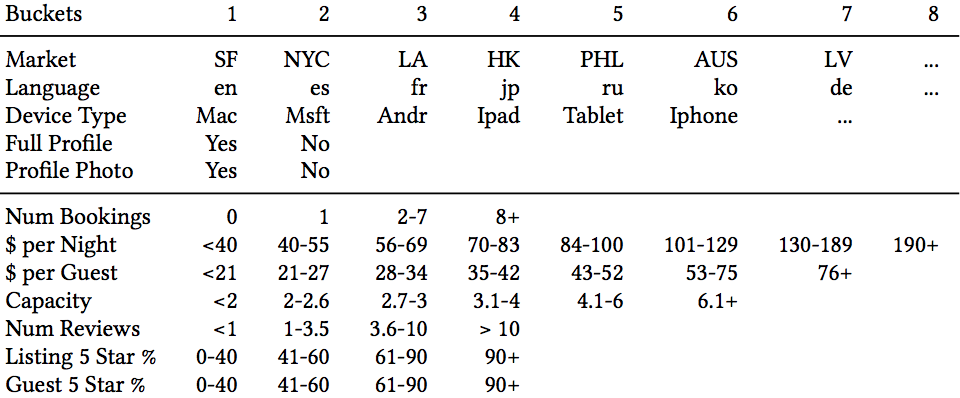 从上表中可以看到Airbnb用的用户属性包括:device type、是否填了简介、有没有头像照片、之前定过的平均价位等等。细心的你可能发现中间画了一条线,表示如果一个用户没有过预订行为,其类别只用线上的五行属性,如果有预订行为,则用所有的属性。
从上表中可以看到Airbnb用的用户属性包括:device type、是否填了简介、有没有头像照片、之前定过的平均价位等等。细心的你可能发现中间画了一条线,表示如果一个用户没有过预订行为,其类别只用线上的五行属性,如果有预订行为,则用所有的属性。
由于booking session集合的大小是远远小于click session的,而且大部分listing被book的次数也少的可怜,我们知道word2vec要训练出较稳定且有意义的embedding,item最少需要出现5-10次,但大量listing的book次数少于5次,我们采用上面做法,同一list_type或user_type的出现次数很大可能大于5,足以训练得到可靠的embedding。
有了user type和listing type之后,我们用listing type替换booking session sequence中的listing id,重新生成新的booking session sequence,同样训练word2vec模型即可得到listing type embedding。Airbnb在此基础上更进了一步,为了得到和listing type embedding在同一个vector space中的user type embedding,airbnb采用了一种比较“反直觉”的方式:
- 首先用(user_type, listing_type)组成的元组替换掉原来的listing id,因此sequence变成了[(Ut1,Lt1),(Ut2,Lt2),…,(Utm,Ltm)]。这里Lt1指的就是listing1对应的listing type,Ut1指的是该user在book listing1时的user type,由于某一user的user_type会随着时间变化,所以每个元祖的user_type不一定相同。
- 将新的sequence进行Flatten,不区分到底是user type和item type,直接训练embedding。
Airbnb还把“房主拒绝”(reject)这个动作组成元祖(Ut1,Lt1),加入训练embedding的负样本集中。对于大部分长度为1的booking session,可以直接丢弃,或者因为Flatten之后长度变为了2,也可以加入训练。
排序
airbnb采用的ranking模型是一个pairwise的支持Lambda Rank的GBDT模型(二分类)。模型的输入特征基于上面所得到的embedding计算而来:
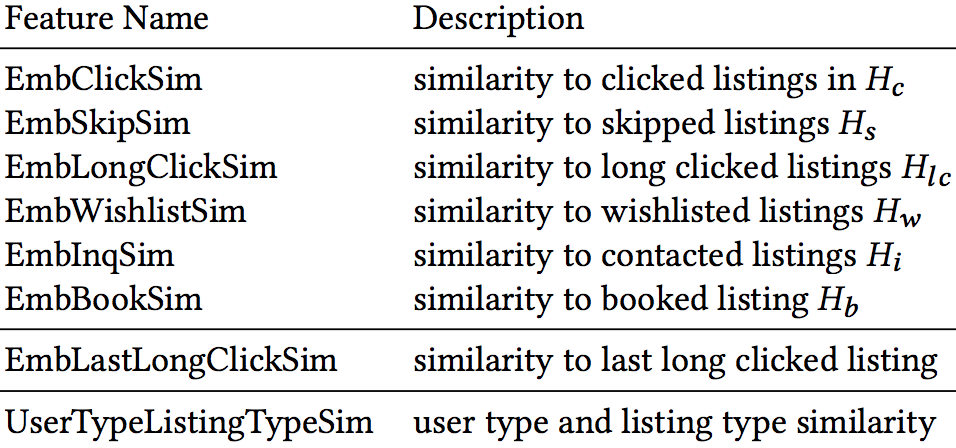 我们可以很清楚的看到,最后一个特征UserTypeListingTypeSim指的是user type embedding和listing type embedding的Cosine similarity,EmbClickSim则是candidate listing embedding与用户最近点击过的listings embedding(average pooling)的Cosine similarity。
我们可以很清楚的看到,最后一个特征UserTypeListingTypeSim指的是user type embedding和listing type embedding的Cosine similarity,EmbClickSim则是candidate listing embedding与用户最近点击过的listings embedding(average pooling)的Cosine similarity。
为什么airbnb在文章题目中强调是real time personalization?原因就是由于在这些embedding相关的feature中,我们加入了“最近点击listing的相似度”,“最后点击listing的相似度”这类特征,由于这类特征的存在,用户在点击浏览的过程中就可以得到实时的反馈,搜索结果也是实时地根据用户的点击行为而改变,所以这无疑是一个real time个性化系统。
那么为什么不直接用user-type以及listing-type embedding训练排序模型呢?是因为embedding模型和排序模型不是一起训练的,embedding如果更新的话,如果排序模型不重新训练则会出错,而similarity特征是相对比较稳定的,并且可以用到short term embedding等更加丰富的特征。