排序(ranking)算法整体可分为point-wise、pair-wise和list-wise,举个现实的例子,如果用户小白更喜欢“吃鸡”而不是“王者荣耀”你,那么:
- point-wise:这是最一般使用的做法,即对每一个候选物品给出一个评分,然后基于该评分进行排序。这种做法仅仅考虑了用户和物品之间的关系,而没有考虑排序列表中物品之间的关系。即point-wise会优化:f(小白,吃鸡)=1;f(小白,王者荣耀)=0。
- pair-wise:将候选物品对作为整体输入。即pair-wise会优化:f(小白,吃鸡) > f(小白,王者荣耀)
- list-wise:将候选物品列表作为整体输入。
假设我们一共有1000个item,rank(point wise的CTR预估模型)后取出top 10,也就是最终会展示出10个item,但是这10个item之间会相互影响,所以实际的点击情况和预估的会有gap。也就是说,第一,并没有考虑到item之间的影响;第二,基于第一点,不同用户对不同item之间影响的反馈都不一样。对于第二点的理解,比如展示的10个商品里面有类似的商品,对于有购买某商品意图的用户,这种类似的商品如果排在一块,用户点击价格低的那个商品概率会变大,对于没有购买意图的用户,这种时候把同类商品打散可能更适合让用户去发现。也就是需要预估在items的集合A下,user U对每个item的Re-ranking score。
正是基于以上考虑,所以需要对rank后的item列表做重排序(Re-ranking)。主流的方法是基于RNN的重排序,但是RNN对于建模物品之间的影响有一定的缺陷,如果两个物品相隔较远,它们的相关性并不能很好的刻画。因此很自然的想到基于Transformer的重排序结构,相较于RNN,其优势主要体现在两个方面:
- 两个物品的距离不会影响其相关性的计算。
- Transformer是并行计算,编码效率相较于RNN更为高效。
关于Re-ranking,最经典的论文便是阿里的Personalized Re-ranking for Recommendation,下面详细看一看。
模型架构
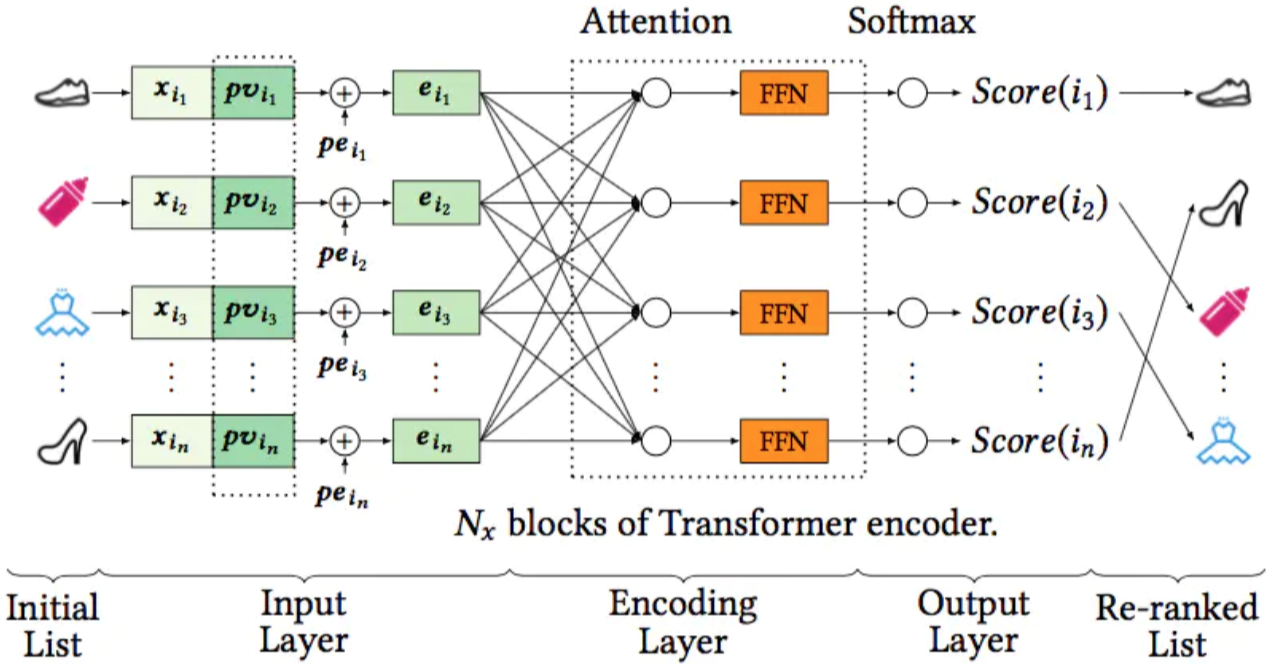 模型分成三个模块:input layer,encoding layer,output layer。
模型分成三个模块:input layer,encoding layer,output layer。
input layer
输入包含三个部分,首先是10个候选集的embedding(需要重新学习,不直接用ranking模型的),然后是position embedding(一定程度上消除了位置偏置的影响),最后还引入了user-item的特征向量pv(Personalized Vector),即用户和每一个物品之间都会计算一个个性化向量pvi作为输入,这个做法就是为了建模不同用户对item之间相互影响的不同反馈,个性化向量通过如下的预训练模型得到:
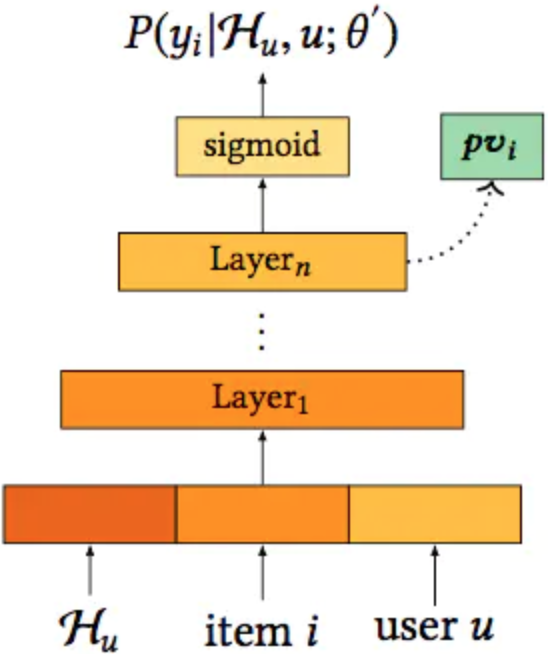 Hu是用户行为序列,即用户u历史点击的item序列。这个向量其实可以用ranking模型的最后一层来替代,实际成本会比较低。
Hu是用户行为序列,即用户u历史点击的item序列。这个向量其实可以用ranking模型的最后一层来替代,实际成本会比较低。
三个向量concat之后输入encoding layer,encoding layer是一个多层Transformer。
output layer
输出层通过softmax得到每个物品的重排序得分score(i),并按照得分高低进行重排序。因为每一次推荐的item列表在点击其中一个之后都会刷新,所以可以看成是一个多分类模型,通过softmax后的交叉熵计算损失函数。
测试时使用MAP评测指标,线上A/B评价指标包括PV、CTR和GMV。PV指24小时内所有item的浏览总量。如果用户看的越多、点击次数越多,也可以一定程度上表示模型排序结果更好。