模型原理
Prompt Learning是NLP领域继BERT后的又一突破性Topic,总的来说,Prompt是一种为了更好的使用预训练语言模型的知识,采用在输入段添加额外的提示文本的技术。
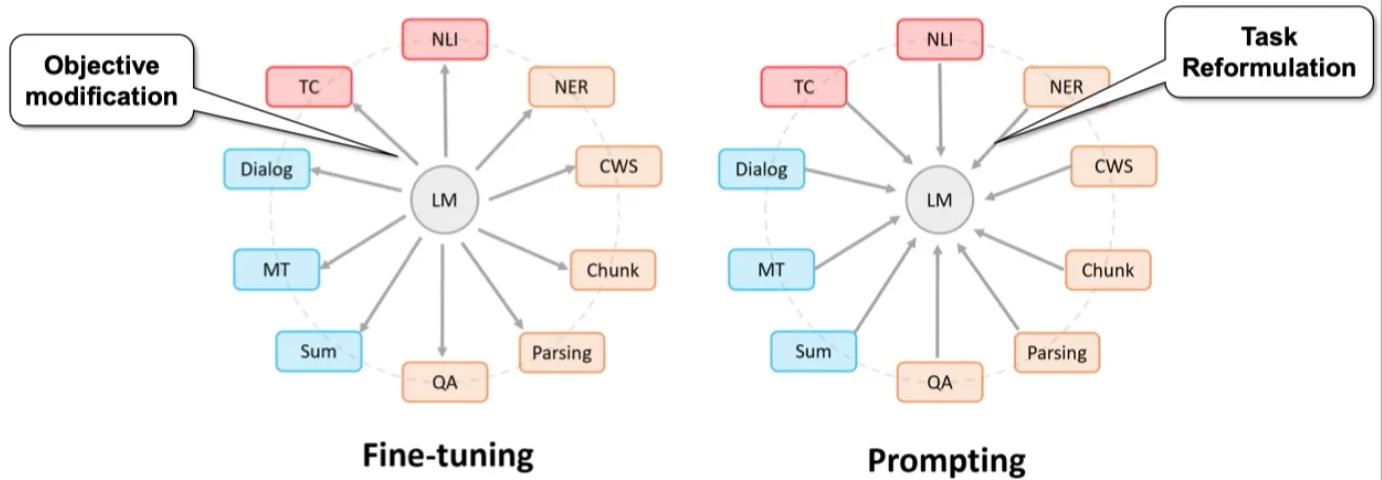
- 目的:更好挖掘预训练语言模型的能力。
- 手段:在输入端添加提示文本,即重新定义任务(task reformulation)。
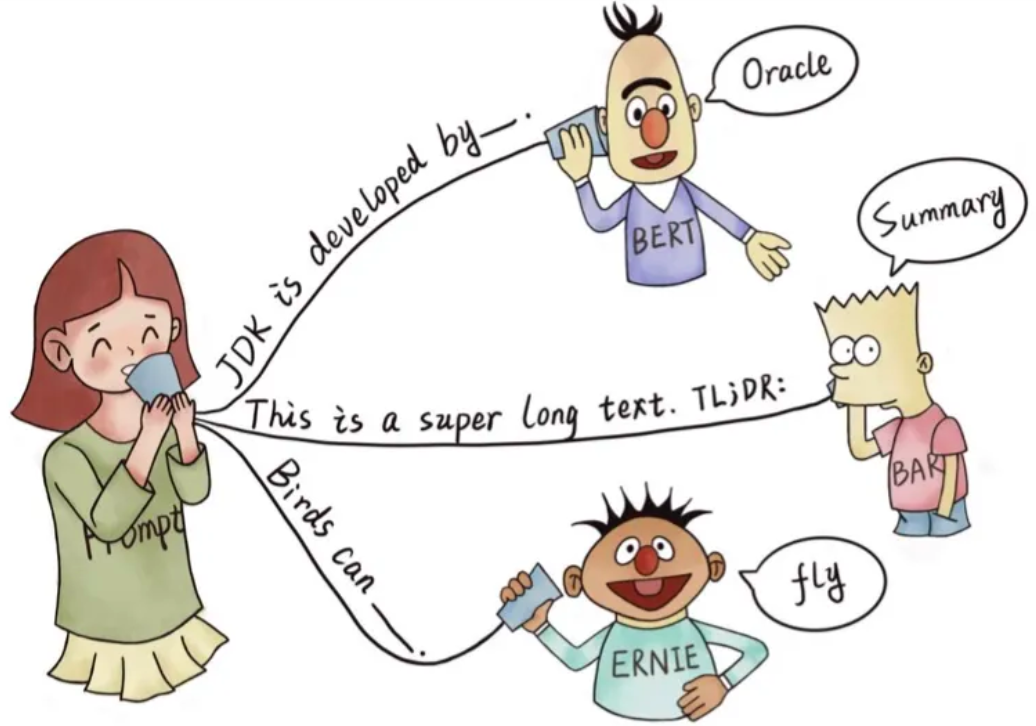 本质上,Prompt Learning可以理解为一种下游任务的重定义方法,这种范式的好处是多方面的:
本质上,Prompt Learning可以理解为一种下游任务的重定义方法,这种范式的好处是多方面的:
- 将所有下游任务均统一为预训练语言模型任务,从而避免了预训练模型和下游任务之间存在的gap。这与BERT类范式(BERT类模型 + fine-tune)有本质上的不同,BERT类范式是模型适配任务,即通过统一的大模型对接各类NLP下游任务,进行fine-tune。这种方式存在的根本问题在于,预训练大模型的训练方式与下游任务差异巨大,打个比方,我本来擅长做完形填空(Masked Language Model),你非要让我去做阅读理解,肯定发挥不出我的最大优势。而prompt learning是通过任务适配模型,将下游任务统一建模为了预训练语言模型的训练任务(MLM),完美的规避了BERT范式的弊端,从而最大程度地挖掘出预训练模型的潜力。
- 如此一来,Prompt Learning在小样本数据集(few shot)上也能够超越Fine-Tuning,即使没有训练数据(zero-shot),Prompt Learning也能达到惊人的效果。
- 而且,正是因为Prompt Learning使得所有任务在使用方法上与训练过程完全一致,下游任务可以公用同一套预训练模型底座,通过训练不同任务特定的prompt参数,使得模型高效适配下游任务。
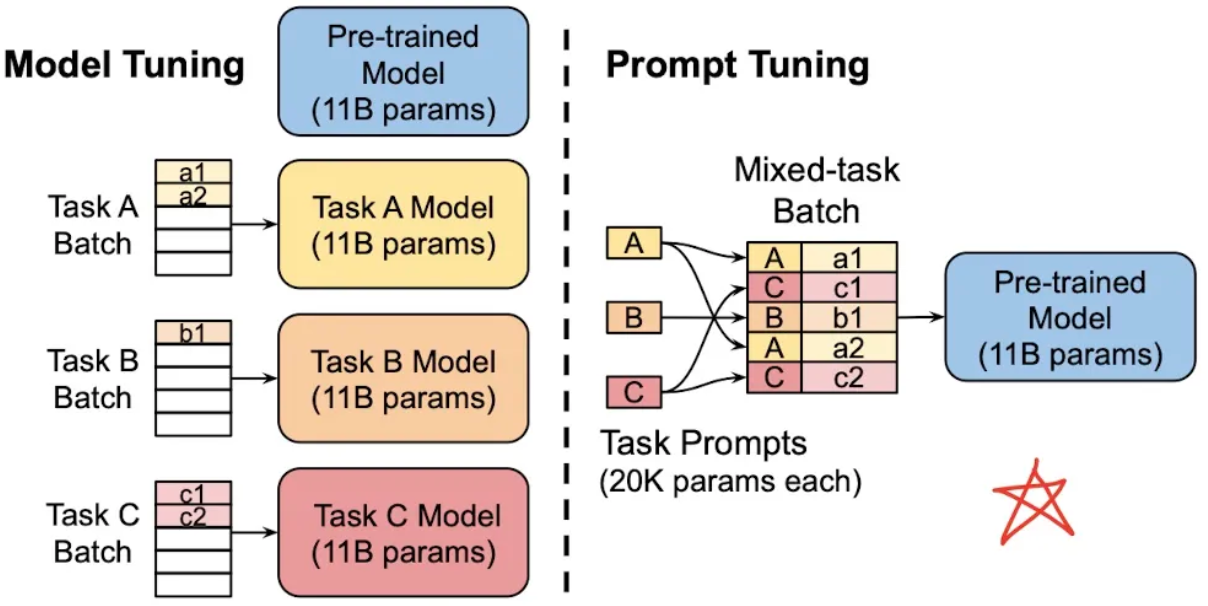 为了告知模型需要执行的任务类型,在输入的文本前添加任务特定的文本前缀(task-specific prefifix)进行提示,这也就是最早的Prompt Learning。通常如果我们只有很少的标注数据,那么就不要去fine-tune预训练语言模型,只训练prompt参数即可。反之,可以选择fine-tune语言模型与训练prompt参数同时进行。注:关于如何fine-tune prompt参数,通常有两种做法,二者本质上是异曲同工的:
为了告知模型需要执行的任务类型,在输入的文本前添加任务特定的文本前缀(task-specific prefifix)进行提示,这也就是最早的Prompt Learning。通常如果我们只有很少的标注数据,那么就不要去fine-tune预训练语言模型,只训练prompt参数即可。反之,可以选择fine-tune语言模型与训练prompt参数同时进行。注:关于如何fine-tune prompt参数,通常有两种做法,二者本质上是异曲同工的:
- 在输入前添加一个由任务相关连续向量组成的前缀,并且fix住PLM参数,仅调参此任务相关连续向量。
- 在输入前添加特殊的tokens作为模板(template),并且仅训练这些tokens的embedding表示。
Prompt的工作流
Prompt的工作流主要包含四个部分:
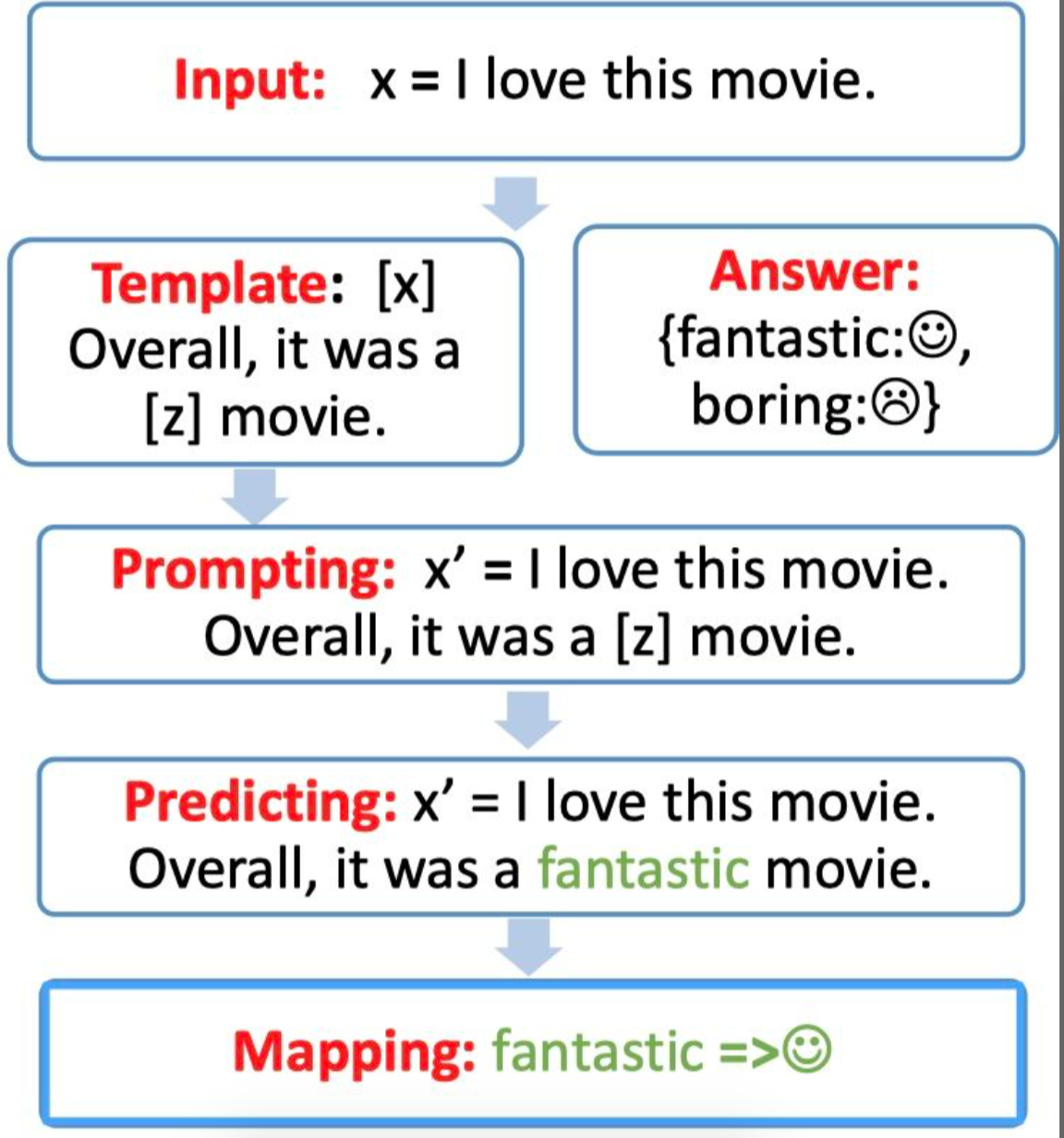 下面我们将结合一个情感分类任务(假设我们需要判断“我喜欢这个电影。”这句话的情感极性),一步步进行拆解分析。
下面我们将结合一个情感分类任务(假设我们需要判断“我喜欢这个电影。”这句话的情感极性),一步步进行拆解分析。
1. Template构建
首先我们需要构建一个模版(Template),Template的作用是将输入和输出重新构造为一个带有mask slots的文本。具体如下:
- 定义一个Template,包含两处代填入的slots([x]和[z]):“[x]总而言之,它是一个[z]电影。”
- 将[x]用输入文本代入:x = “我喜欢这个电影。”
- 最终形成prompting:“我喜欢这个电影。总而言之,它是一个[z]电影。”
prompt learning实际上包含两处feature engineering,Template构建就是其中最重要的一处。如何构造合适的Prompt模版?对于同一个任务,不同的人可能构造出不同的Template。且每个Template都具有合理性。Template的选择,将直接影响prompt learning的最终效果:
 所以为了强化prompt learning的最终效果,可以进行一些范式拓展。如Prompt Ensemble(多个Template集成)、Prompt Decomposition(分拆成多个Template,每个Template只解决单一问题)等。
所以为了强化prompt learning的最终效果,可以进行一些范式拓展。如Prompt Ensemble(多个Template集成)、Prompt Decomposition(分拆成多个Template,每个Template只解决单一问题)等。
2. Verbalizer构建
然后我们需要构建一个答案空间映射(Verbalizer),即通过一个映射函数将预测词与label进行对应。
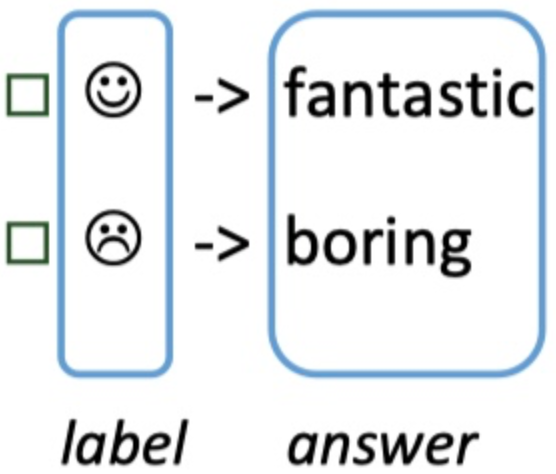 Verbalizer构建是prompt learning的第二处特征工程。上例中我们的label空间是Positive和Negative;答案空间可以是任何表示positive和negative的词,例如Interesting/Fantastic/Happy/Boring/1-Star/Bad,具体的答案空间的选择范围可以由我们指定,并且可以同时指定多个(最终得分取加和)。
Verbalizer构建是prompt learning的第二处特征工程。上例中我们的label空间是Positive和Negative;答案空间可以是任何表示positive和negative的词,例如Interesting/Fantastic/Happy/Boring/1-Star/Bad,具体的答案空间的选择范围可以由我们指定,并且可以同时指定多个(最终得分取加和)。
3. MLM预测
现在我们就只需要选择合适的预训练模型,对mask slots [z]进行预测。例如本例我们得到了结果fantastic。
如何选择一个合适的预训练语言模型也是需要人工经验判别的。具体的预训练语言模型分类可以分为如下几类:
- autoregressive-models: 自回归模型,主要代表有GPT,用于生成任务(如对话)。
- autoencoding-models: 自编码模型,主要代表有BERT,用于NLU任务(如完形填空)。
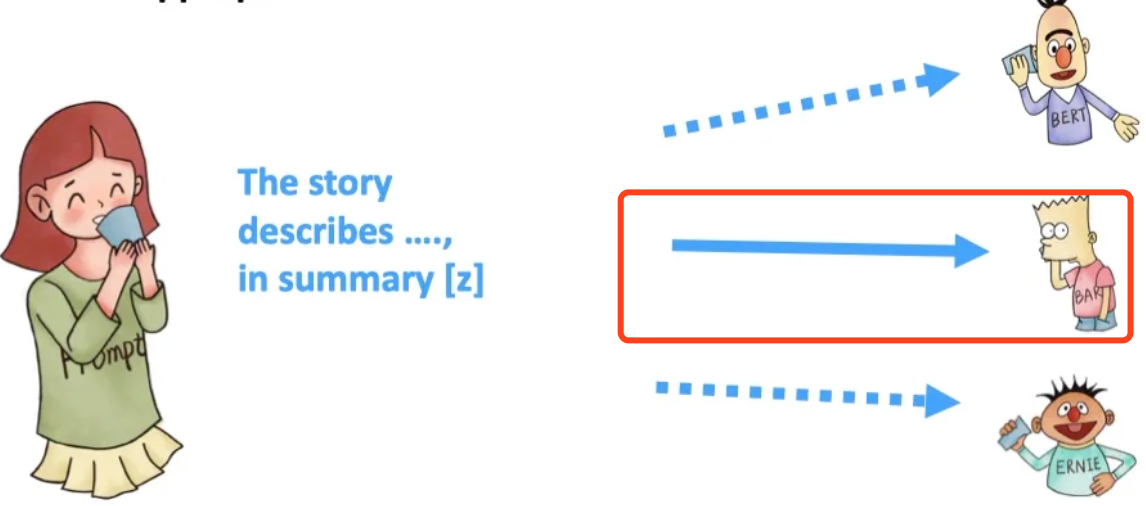
- seq-to-seq-models:序列到序列任务,包含了encoder和decoder,主要代表有BART,用于基于条件的生成任务(如翻译、summary)。
例如下图想要做summary任务,可以选择更合适的BART模型。
4. 答案映射
最后,对于得到的answer,我们只需要使用Verbalizer将其映射回原本的label,就得到了“我喜欢这个电影。”这句话的情感极性了。
代码实现
光说不练假把式,下面我们结合代码深入理解prompt learning。
MLM预测
我们知道,MLM和NSP两个任务是目前BERT类预训练语言模型的预训练任务,其中MLM任务就是通过整句来预测被masked的词(Deep BiDirectional Transformers):
import torch.nn as nn
from transformers import BertModel,BertForMaskedLM
class Bert_Model(nn.Module):
def __init__(self, bert_path ,config_file ):
super(Bert_Model, self).__init__()
self.bert = BertForMaskedLM.from_pretrained(bert_path,config=config_file) # 加载预训练模型
def forward(self, input_ids, attention_mask, token_type_ids):
outputs = self.bert(input_ids, attention_mask, token_type_ids) # masked LM输出的是masked位置对应的ids的概率,即输出词表中每个词的概率
logit = outputs[0] # 池化后的输出 [batch_size, config.hidden_size]
return logit
下面一段代码,简单的使用了hugging face中的bert-base-uncased进行空缺词(masked word)预测,并且按照概率从大到小排序后,默认输出top 5:
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
pred = unmasker("natural language processing is a [MASK] technology.")
print(pred)
[{'score': 0.1892707794904709, 'token': 3274, 'token_str': 'computer',
'sequence': 'natural language processing is a computer technology.'},
{'score': 0.14354866743087769, 'token': 4807, 'token_str': 'communication',
'sequence': 'natural language processing is a communication technology.'},
{'score': 0.09429354965686798, 'token': 2047, 'token_str': 'new',
'sequence': 'natural language processing is a new technology.'},
{'score': 0.051847927272319794, 'token': 2653, 'token_str': 'language',
'sequence': 'natural language processing is a language technology.'},
{'score': 0.040842678397893906, 'token': 15078, 'token_str': 'computational',
'sequence': 'natural language processing is a computational technology.'}]
基于prompt learning的MLM预测
from transformers import pipeline
unmasker = pipeline('fill-mask', model='bert-base-uncased')
template = "Because it was [MASK]."
text1 = "I really like the film a lot. "
prompt1 = text1 + template
pred1 = unmasker(prompt1)
print(pred1)
[{'score': 0.14730945229530334, 'token': 2307, 'token_str': 'great',
'sequence': 'i really like the film a lot. because it was great.'},
{'score': 0.10884211957454681, 'token': 6429, 'token_str': 'amazing',
'sequence': 'i really like the film a lot. because it was amazing.'},
{'score': 0.09781624376773834, 'token': 2204, 'token_str': 'good',
'sequence': 'i really like the film a lot. because it was good.'},
{'score': 0.046277400106191635, 'token': 4569, 'token_str': 'fun',
'sequence': 'i really like the film a lot. because it was fun.'},
{'score': 0.04313807934522629, 'token': 10392, 'token_str': 'fantastic',
'sequence': 'i really like the film a lot. because it was fantastic.'}]
text2 = "this movie makes me very disgusting. "
prompt2 = text2 + template
pred2 = unmasker(prompt2)
print(pred2)
[{'score': 0.054643284529447556, 'token': 9643, 'token_str': 'awful',
'sequence': 'this movie makes me very disgusting. because it was awful.'},
{'score': 0.0503225214779377, 'token': 2204, 'token_str': 'good',
'sequence': 'this movie makes me very disgusting. because it was good.'},
{'score': 0.04008961096405983, 'token': 9202, 'token_str': 'horrible',
'sequence': 'this movie makes me very disgusting. because it was horrible.'},
{'score': 0.035693779587745667, 'token': 3308, 'token_str': 'wrong',
'sequence': 'this movie makes me very disgusting. because it was wrong.'},
{'score': 0.03335856646299362, 'token': 2613, 'token_str': 'real',
'sequence': 'this movie makes me very disgusting. because it was real.'}]
基于prompt learning的情感分类
现在我们将用prompt learning工作流完整的跑一遍zero-shot情感分类任务。
from prompt import Prompting
model_path = "bert-base-uncased"
prompting = Prompting(model=model_path)
template = "Because it was [MASK]."
vervlize_pos = ["great", "amazin", "good"]
vervlize_neg = ["bad", "awfull", "terrible"]
text1 = "I really like the film a lot. "
prompt1 = text1 + template
pred1 = prompting.prompt_pred(prompt1)
pred_score1 = prompting.compute_tokens_prob(prompt1, token_list1=vervlize_pos, token_list2=vervlize_neg)
print(pred1[:3])
print(pred_score1)
[('great', tensor(9.5558)), ('amazing', tensor(9.2532)), ('good', tensor(9.1464))]
tensor([9.9902e-01, 9.8264e-04])
text2 = "I did not like the film. "
prompt2 = text2 + template
pred2 = prompting.prompt_pred(prompt2)
pred_score2 = prompting.compute_tokens_prob(prompt2, token_list1=vervlize_pos, token_list2=vervlize_neg)
print(pred2[:3])
print(pred_score2)
[('bad', tensor(8.6784)), ('funny', tensor(8.1660)), ('good', tensor(7.9858))]
tensor([0.1236, 0.8764])
基于prompt learning的NER
对于NER任务,prompt learning也可以通过跟情感分类任务一样的做法,询问实体所属的类型集合。
from prompt import Prompting
model_path = "bert-base-uncased"
prompting = Prompting(model=model_path)
template = "Savaş went to Laris to visit the parliament. "
vervlize_per = ["person", "man"]
vervlize_pos = ["location", "city", "place"]
pred_score1 = prompting.compute_tokens_prob(template + "Savaş is a type of [MASK].", token_list1=vervlize_per,
token_list2=vervlize_pos)
print(pred_score1)
tensor([9.9996e-01, 3.6852e-05])
pred_score2 = prompting.compute_tokens_prob(template + "Laris is a type of [MASK].", token_list1=vervlize_per,
token_list2=vervlize_pos)
print(pred_score2)
tensor([0.3263, 0.6737])
基于prompt learning的fine-tune
如果我们有标注数据,如何进行fine-tune呢?我们还是基于上面情感分类的例子。
def fine_tune(self, sentences, labels, prompt=" Since it was [MASK].", goodToken="good", badToken="bad"):
"""
对已有标注数据进行Fine tune训练。
"""
good = self.tokenizer.convert_tokens_to_ids(goodToken)
bad = self.tokenizer.convert_tokens_to_ids(badToken)
from transformers import AdamW
optimizer = AdamW(self.model.parameters(), lr=1e-3)
for sen, label in zip(sentences, labels):
tokenized_text = self.tokenizer.tokenize(sen + prompt)
indexed_tokens = self.tokenizer.convert_tokens_to_ids(tokenized_text)
tokens_tensor = torch.tensor([indexed_tokens])
mask_pos = tokenized_text.index(self.tokenizer.mask_token)
outputs = self.model(tokens_tensor)
predictions = outputs[0]
pred = predictions[0, mask_pos][[good, bad]]
prob = torch.nn.functional.softmax(pred, dim=0)
lossFunc = torch.nn.CrossEntropyLoss()
loss = lossFunc(prob.unsqueeze(0), torch.tensor([label]))
loss.backward()
optimizer.step()
代码链接: https://github.com/qianshuang/prompt_learning
参考文献: https://zhuanlan.zhihu.com/p/442486331 https://mp.weixin.qq.com/s/uGm0CquGEwvK8-3JLMhmTw https://xiaosheng.run/2022/09/10/what-is-prompt.html