GPT-3与BERT
GPT-3是chatGPT的核心模块之一,它是一种自然语言生成模型,主要用于对话领域,和BERT一样底层基于deep transformers模型架构,并且都是在超大规模数据集上训练出来的预训练语言模型。BERT与GPT-3主要有以下几点不同:
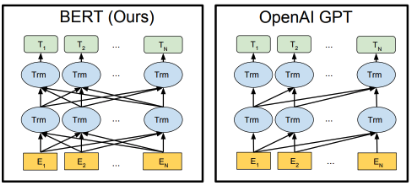
- 模型架构。BERT基于Deep BiDirectional Transformers(详情见往期分享BERT),而GPT-3是基于deep One-Directional Transformers的。
- Transformer使用方式。BERT仅用到了Transformer架构的encoder部分;GPT-3则使用了Transformer的整个架构,包括encoder和decoder部分。
- 训练方式。BERT是一种采用多任务迁移学习的方式(masked LM和NSP)训练出来的自编码模型;GPT-3则是通过Seq2Seq的方式训练出来的自回归模型。所谓自回归模型,通俗的讲就是自己生成自己,即通过输入文本结合T时刻所得到的全部输出,生成T+1时刻的结果。
GPT-3的本质
GPT-3主要聚焦于更通用的NLP模型,解决当前BERT类模型的两个主要缺陷:
- 对领域内有标签数据的过分依赖:虽然有了预训练+精调的两段式框架,但还是少不了一定量的领域标注数据,否则很难取得不错的效果,而标注数据的成本又是非常高的。
- 对于领域数据分布的过拟合:在精调阶段,因为领域数据有限,模型只能拟合全部训练数据分布,如果数据较少的话很可能造成过拟合,致使模型的泛化能力下降,更加无法应用到其他领域。
所以,GPT-3的主要目标是用更少的领域数据,且不经过精调步骤去解决问题。这是一种one stack to rule them all的大一统思想,对于所有任务,GPT-3无需进行任何梯度更新或微调,而仅通过与模型的文本交互指定任务和少量演示即可。
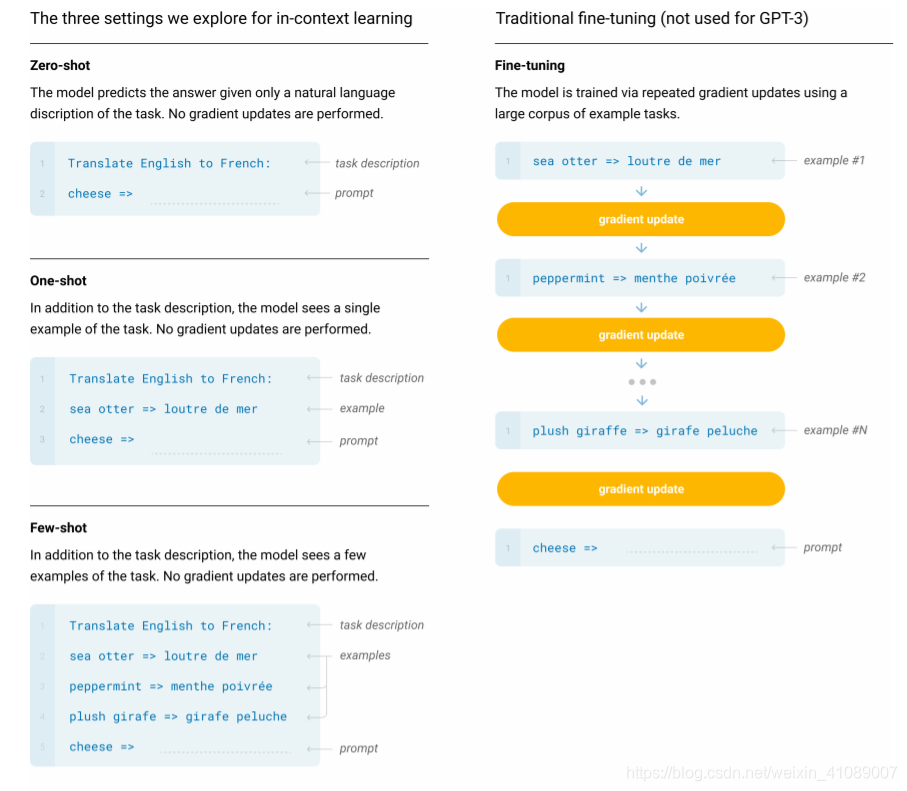
如上所示,不管是Few-Shot还是One-Shot:都只是在推理时对模型进行一些任务相关的示例演示,这就是prompt learning中的template,它与输入文本共同构成prompt,由模型负责适应并识别出被赋予的任务。
GPT-3试图向大家证明,使用足够丰富的数据训练一个足够大的模型,可以获得更通用的自然语言理解能力,这些能力使它在预测时可以迅速地适应并识别出被赋予的任务。这时候模型能承载的并不仅仅是任务本身,比如“汪小菲的妈是张兰”,这条文字包含的信息是通用的,它可以用于分类、判断错误、实体识别、关系推理等。也就是说,信息是脱离具体的NLP任务而存在的,举一反三,能够利用这条信息在每一个NLP任务上都表现出色,这就是元学习(meta-learning),本质上就是语言模型的一脑多用。