之前我们所讲到的BERT、prompt learning、GPT-3,都是人工智能行业的重大突破,但是也只是引起了NLP领域小范围的轰动,但是chatGPT掀起了全球范围内几乎所有领域的热潮,世所罕见,全然一副人工智能奇点将要来临的赶脚。
ChatGPT和去年年初公布的InstructGPT是一对姊妹模型,有时候也被叫做GPT3.5,是在GPT-4之前发布的预热模型,据传还未发布的GPT-4是一个多模态模型,那时ChatGPT可能不光只会理解文本回复文本,还能理解视频图片语音,进而让回复内容更加生动活泼,we will see.
ChatGPT和InstructGPT在模型结构,训练方式上都完全一致,即都使用了指令学习(Instruction Learning)和人工反馈强化学习(RLHF)来进行模型的训练,不同的仅仅是采集数据的方式上有所差异。但目前ChatGPT论文及代码细节尚未公布,但我们完全可以通过InstructGPT来理解ChatGPT模型及训练细节。
模型架构
ChatGPT的核心主要包含以下两个方面:
- 指令学习(Instruct learning):其实就是prompt learning
- RLHF(Reinforcement Learning from Human Feedback):基于人工反馈的强化学习
具体训练过程如下图所示:
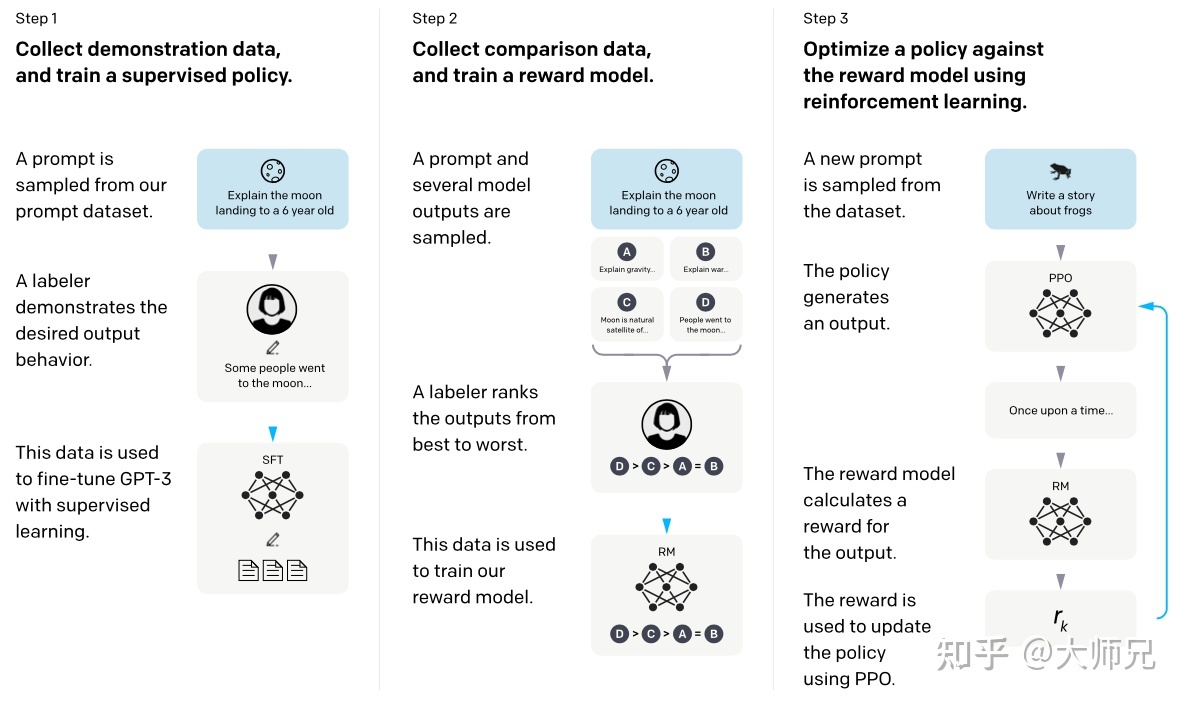 从上图可以看到,InstructGPT/ChatGPT的训练可以分成3步,分别是SFT、RM、PPO,下面将分别进行展开。
从上图可以看到,InstructGPT/ChatGPT的训练可以分成3步,分别是SFT、RM、PPO,下面将分别进行展开。
SFT
该阶段根据采集的SFT数据集对GPT-3进行有监督的微调(Supervised FineTune,SFT),这个过程只进行一次,生成冷启动模型。
- SFT数据集。该数据集格式为PA pair(prompt-answer),一部分来自使用OpenAI的PlayGround的用户,另一部分来自OpenAI内部工程师(赋予代码能力),还有一部分来自OpenAI雇佣的40名标注工(labeler)。
- GPT-3训练。直接利用PA pair对GPT-3进行Seq2Seq训练。
RM
该阶段根据采集的人工标注的RM数据集,训练奖励模型(Reword Model,RM)。
我们需要为InstructGPT/ChatGPT的训练设置一个奖励目标,这个奖励目标不必可导,但是一定要尽可能全面且真实的对齐我们需要模型生成的内容,即论文中提到的3H:有用的(Helpful)、可信的(Honest)、无害的(Harmless)。论文中多次提到了对齐(Alignment)问题,我们可以理解为模型的输出内容和人类喜欢的输出内容的align,也就是让模型具备像人一样的理解能力,而不是仅仅依靠拟合大规模训练数据而具备辨别能力,人类喜欢的不止包括生成内容的流畅性和语法的正确性,还包括生成内容的有用性、真实性和无害性。
很自然的,我们可以通过人工标注的方式来提供这个奖励,通过人工标注给那些对齐质量差的生成内容更低的得分,从而让模型尽量不去生成这些人类不喜欢的内容。具体步骤如下:
- 先用第一步产生的SFT模型为每一个prompt随机生成K个candidates(4 <= K <= 9)。
- 从K个candidates中任取两个,并与prompt组合成(prompt, candidate1, candidate2)元组。
- labeler根据每份元组的对齐质量对两个candidates进行排序打分。
- 将上步共生成的C(K,2)组训练数据作为一个batch送入RM模型进行pair-wise训练。这种按prompt为batch的训练方式要比传统的按样本为batch的训练方式(shuffle后batch)更不容易过拟合,因为这种方式每个prompt会且仅会输入到模型一次。
论文中RM的模型结构是将第一步SFT训练后的模型的最后的非嵌入层去掉后得到的模型(with the final unembedding layer removed,其实就是去掉最后的softmax层),它的输入是(prompt, candidate1, candidate2)元组,输出是两个candidates奖励值的差值的sigmoid再取log,所以它可以看做是一个回归模型。
RM模型的损失函数为:
 这个损失函数的目标是最大化labeler更喜欢的响应和不喜欢的响应之间的差值。其中Rθ(x,y)是提示x和响应y在参数为θ的奖励模型下的奖励值,Yw是labeler更喜欢的响应结果,Yl是labeler不喜欢的响应结果,D是整个训练数据集。
这个损失函数的目标是最大化labeler更喜欢的响应和不喜欢的响应之间的差值。其中Rθ(x,y)是提示x和响应y在参数为θ的奖励模型下的奖励值,Yw是labeler更喜欢的响应结果,Yl是labeler不喜欢的响应结果,D是整个训练数据集。
有同学可能会问,为什么RM模型要通过pair-wise训练方式,而不直接使用point-wise?
- 对于标注者来说,对输出进行排序比从头开始打标要容易得多。
- 通过对一个prompt的K个candidates,进行C(K,2)拓展,产生更多标注数据,能够更充分的融入人类的对齐理解能力。
- pair-wise训练能将对齐关系通过偏好得分(对比后更偏好哪个)直观展现,RM奖励模型训练的目的。
PPO
该阶段使用RM模型的输出奖励值作为强化学习的优化目标,预训练的LM作为策略,将提示作为输入并返回输出文本,它的动作空间是LM的词表,状态是当前生成的token序列,利用PPO(Proximal Policy Optimization)算法微调SFT模型。具体步骤如下:
- 由第一步fine-tune后的SFT模型来初始化PPO策略模型,由第二部生成的RM模型初始化价值函数。
- 从PPO数据集中随机采样一个prompt,并通过第一步的PPO策略模型生成输出结果answer。
- 对prompt和answer,带入RM模型计算奖励值reward。
- 利用reward来更新PPO策略模型参数。
- 重复2~4步,直至PPO策略模型收敛。
为了避免显著偏离初始(调整前)LM,通常将惩罚项纳入奖励函数,这就是所谓的PPO算法。即对于每个输入提示,计算当前LM和初始LM生成的结果之间的KL散度作为惩罚。
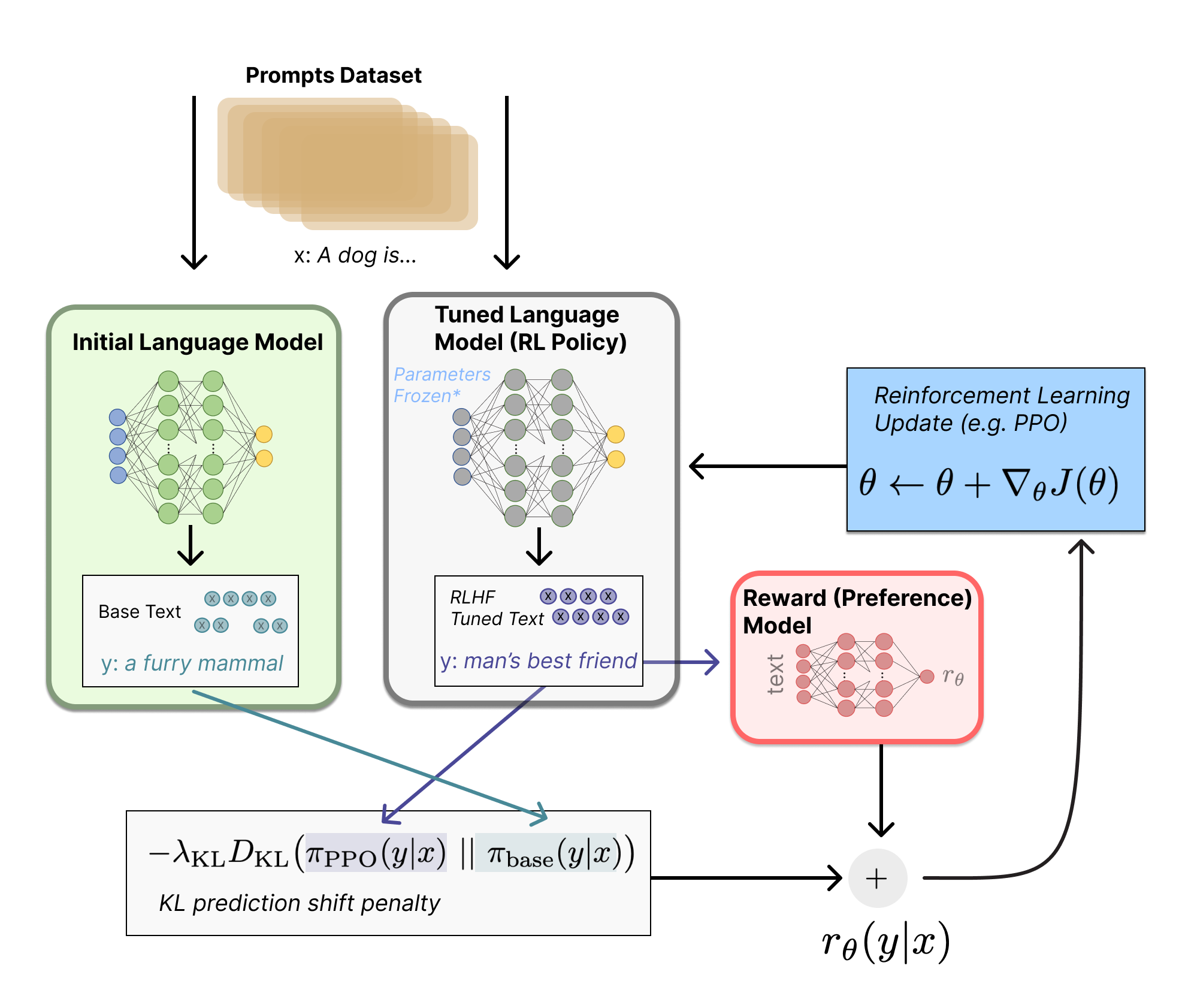 PPO解决的关键问题是RL用在LLM的稳定性上的问题。比如过程中加入“正常的参考”,防止学习的过程太激进,让他尽量保持较好LLM的能力,而不是单纯拟合高分。
KL散度是两个分布p(x)和q(x)之间不相似程度的度量,当p(x)=q(x)时值为0。最小化KL散度等价于最大化似然函数。KL散度详见:https://zhuanlan.zhihu.com/p/39682125
PPO解决的关键问题是RL用在LLM的稳定性上的问题。比如过程中加入“正常的参考”,防止学习的过程太激进,让他尽量保持较好LLM的能力,而不是单纯拟合高分。
KL散度是两个分布p(x)和q(x)之间不相似程度的度量,当p(x)=q(x)时值为0。最小化KL散度等价于最大化似然函数。KL散度详见:https://zhuanlan.zhihu.com/p/39682125
强化学习和预训练模型是最近两年最为火热的AI研究方向,之前不少科研工作者说强化学习并不是非常适合应用到预训练模型中,因为很难通过模型的输出内容建立奖励机制。而InstructGPT/ChatGPT反直觉的做到了这点,它通过结合人工标注,将强化学习引入到预训练语言模型中是这个算法最大的创新点。
chatGPT的人工标注数据总量并不大,下图展示了三份数据的来源及其数据量:
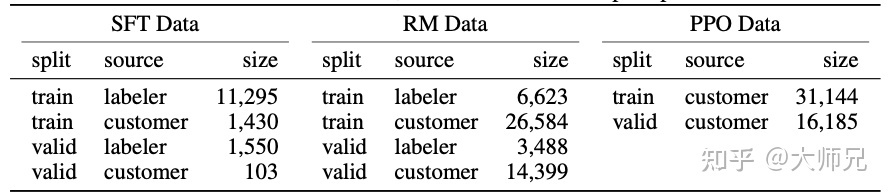
注意:RM模型训练步骤和PPO模型训练步骤会在同一份数据上交替进行好几次。
个人感悟
- chatGPT经历着模型泛化能力和任务准确度之间的零和博弈。泛化能力增强,准确度必然降低,所以chatGPT在PPO训练阶段引入了很多对抗损失用以调和这两者之间的矛盾,但始终无法根除。
- 为什么chatGPT要引入RM与PPO的两阶段训练方式,而不是直接利用训练数据微调SFT?一方面是为了充分利用标注数据挖掘出模型的潜能(充分泛化),另一方面最重要的是让模型学习到人类的对齐理解能力(其实就是希望机器能够学习到人的打分逻辑)。
- 本质上预训练模型的能力取决于对训练数据的拟合程度(利用度),充分利用会过拟合,不充分利用又不能物尽其用。
- 总体来说,chatGPT还是基于prompt learning的,同时它也是基于multi-task transfer learning的(训练数据上有分类任务、QA任务、文本摘要任务、闲聊问答任务等),只不过通过重建prompt来统一训练。不论是人工标注的prompt,还是模型上线后的输入prompt(input),都是prompt越详尽,提示越清晰,回答效果越好。
- chatGPT最重要的,是统一了智能机器人范式。之前我们在智能机器人章节提到,智能机器人包括QA-bot、Task-bot、chat-bot、IR-bot等,chatGPT出现后,江湖将再无此种划分边界,因为chatGPT本身具有In-Context learning的能力,你只要将全部信息(作为prompt)输入chatGPT,等待结果即可。
- 关于微软bing将如何整合chatGPT的能力?笔者认为可能有3种方式:
- Stack模式,即搜索做召回,chatGPT做精排,将搜索得到的全部网页结果再输入chatGPT,得到直接准确答案。
- 使用chatGPT的RM模型和PPO模型,进一步指导网页排序。
- 页面内内嵌chatGPT。由chatGPT理解分析整个页面内容,进行页面内问答。
参考文献: https://arxiv.org/pdf/2203.02155.pdf https://zhuanlan.zhihu.com/p/590311003 https://www.bilibili.com/video/BV1hd4y187CR/?buvid=Y84DF9891E5B5A7C4BC08D0925D9E4C07834&is_story_h5=false&mid=i2Rn%2FKFF7dd8tCpF%2B3Zt8w%3D%3D&p=1&plat_id=116&share_from=ugc&share_medium=iphone&share_plat=ios&share_session_id=08B5112B-D95E-4A47-9272-7BE77DDA14F2&share_source=WEIXIN&share_tag=s_i×tamp=1676866918&unique_k=j4bWOxO&up_id=1567748478