神经网络的灵活性也是它的主要缺点之一:有太多超参数可以调整。
Number of Neurons per Hidden Layer
对于每个隐藏层的神经元数目,最佳实践是漏斗模型,即逐层减少。因为许多低级特征可以合并为更少的高级特征。 但是一般来说,通过增加层数而不是每层神经元数量,你将获得更多的收益。
Number of Hidden Layers
对于隐藏层数目,虽然已经证明,只需一个包含足够多神经元的隐层,MLP就能以任意精度逼近任意复杂度的连续函数,但他们忽略了这样一个事实,即深度网络的训练效率要比浅层网络高得多,也就是说可以使用比浅层网络更少的神经元来模拟复杂函数,从而使它们更快地训练。
底层的隐藏层建模低级的结构(抽取低级的细粒度的更具体的特征,比如各种形状和方向的线段),中间的隐藏层结合这些低级特征组成中间级特征(比如组成方形和圆形),最高级隐藏层和输出层结合这些中级特征组成高级的粗粒度的目标特征(比如一张人脸)。
 所以完全可以将DNN所提取的特征送给SVM、LR等传统机器学习模型完成分类任务(loss function使用SVM的hinge损失或者LR的对数损失即可)。
所以完全可以将DNN所提取的特征送给SVM、LR等传统机器学习模型完成分类任务(loss function使用SVM的hinge损失或者LR的对数损失即可)。
假如现在我们已经训练好了一个人脸识别的深度学习模型,现在又来了一个新的业务让我们训练一个动物识别的模型,这时我们可以重用人脸识别模型所抽取的低级特征,即使用其前面几层隐藏层的权重初始化新模型,因为低级的细粒度特征大家都一样,可以共享(而且也因为使用了其他领域的样本而使得低级特征更加多样化),我们只需要学习高级的特征而不用从头开始所有层级的特征,这就是迁移学习,它可以使训练更快并且只需少量的样本即可达到很好的效果。后面会详细讲到。
梯度爆炸梯度消失
一般来说,网络层数越多效果越好。但是随着网络层数的增多,训练会变慢并且容易过拟合,更严重的是,会导致棘手的梯度消失和梯度爆炸问题,使得浅层神经元非常难以训练。
由上节反向传播的基本原理我们知道,根据偏误差反向传递更新参数,由于偏误差一般随着反向传递的过程变得越来越小,从而导致浅层神经元参数几乎不变,这就是梯度消失问题;在某些情况下,偏误差会随着反向传递的过程变得越来越大,浅层神经元大幅度的更新梯度导致训练无法收敛(发散),这是梯度爆炸问题。
激活函数
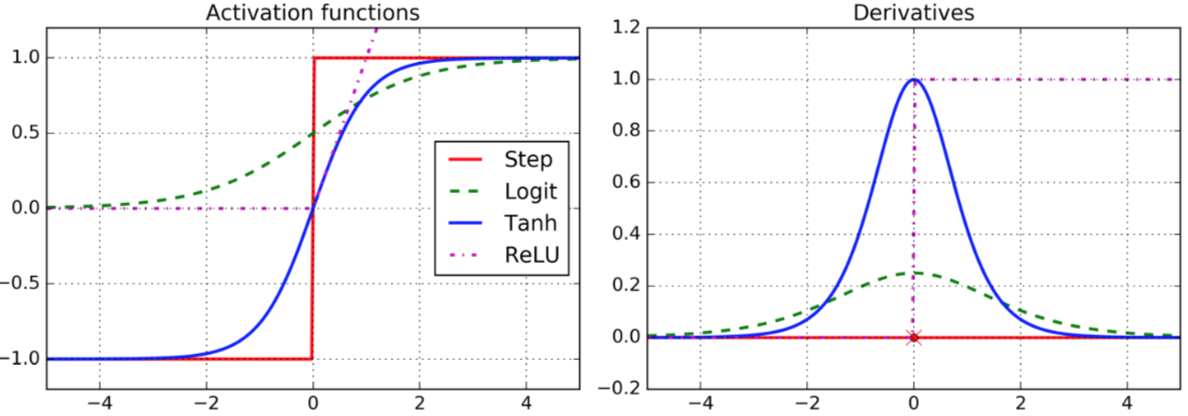
Sigmoid
使用这种激活函数时,如果再用(0, 1)正态分布初始化参数,会导致神经网络的每一层输出的方差比输入方差大很多,因为Sigmoid不是0均值的,所以当神经网络正向计算的时候,方差不断增大,也就是说最终输出值趋近0和1两个极端,这时候回过头来看看反向传播的参数更新过程:
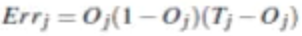 Oj(1-Oj)其实就是Sigmoid函数导数求解公式,当Oj趋近0和1两个极端时,权重更新量几乎为0,所以这种情况下就导致了梯度消失。
Oj(1-Oj)其实就是Sigmoid函数导数求解公式,当Oj趋近0和1两个极端时,权重更新量几乎为0,所以这种情况下就导致了梯度消失。
可以通过Xavier initialization解决Sigmoid激活函数存在的梯度消失问题。这种初始化方式可以使得神经网络每一层的输出方差和输入方差相等,并且还能在BackPropagation的过程中保证流过每一层之前和之后,梯度的方差相等。
he_init = tf.contrib.layers.variance_scaling_initializer()
hidden1 = fully_connected(X, n_hidden1, weights_initializer=he_init, scope="h1")
tanh(hyperbolic tangent)
tanh函数图像与Sigmoid类似,所以也会偶尔出现梯度消失问题,但是由于它是0均值的,所以效果比Sigmoid激活函数稍好,但是其计算稍复杂,所以训练慢。
ReLU(Rectified Linear Unit)
大多数情况下,我们选择使用ReLU激活函数就够了,由于它的梯度要么是0要么是1,所以不会出现梯度消失和爆炸问题,计算(训练)快,且一般来说效果还不错。 但是ReLU也并非完美,它有一个问题叫dying ReLUs,即在训练的过程中,在求偏误差时,如果输出值小于等于0,那么导数就为0,导数为0导致偏误差为0,进而导致这个神经元的所有流入权重向量不发生更新。 当一个很大的梯度反向流过一层神经元的某些权重时(或者learning rate过大),权重大幅度更新,很可能导致正向计算的时候输出值小于等于0,从而导致该神经元的所有流入向量不再发生更新,就永久的死掉了。(因为每次正向计算该神经元的输出都为负值)。
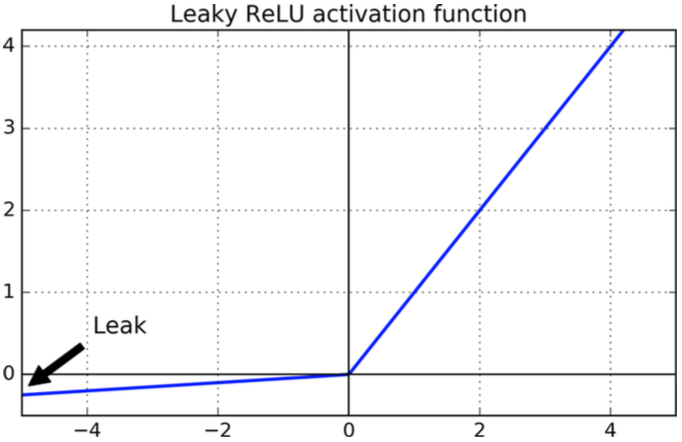
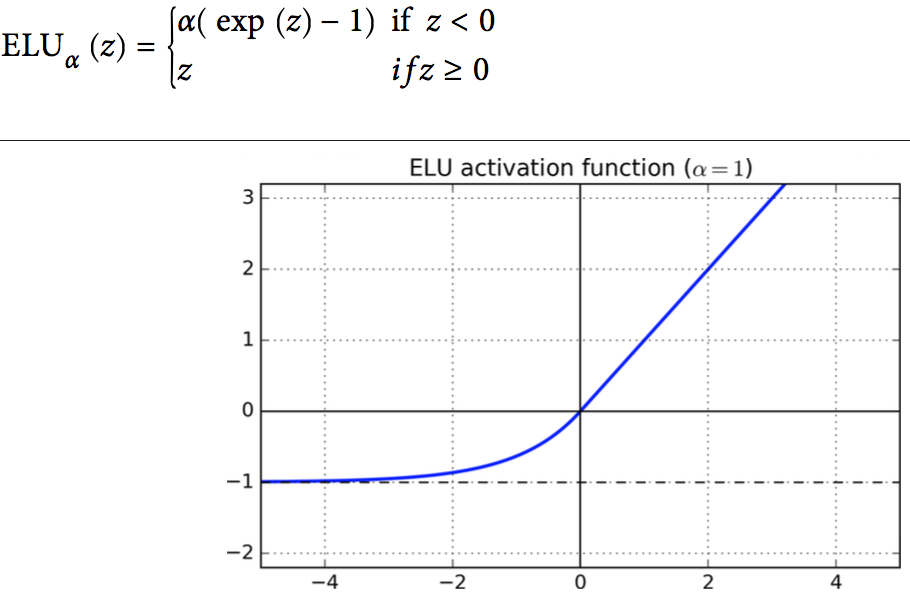
可以通过RelU的变种解决此问题,他们都相当于对小于0的部分做了平滑处理,神经元可以昏迷一段时间,但是仍然有机会苏醒。
- LeakyReLUα(z) = max(αz, z),α一般取0.01;
- ELU(exponential linear unit),α一般取1。
hidden1 = fully_connected(X, n_hidden1, activation_fn=tf.nn.elu)
def leaky_relu(z, name=None):
return tf.maximum(0.01 * z, z, name=name)
hidden1 = fully_connected(X, n_hidden1, activation_fn=leaky_relu)
Batch Normalization
Batch Normalization也是解决梯度爆炸梯度消失问题的利器,它指出了随着前一层的参数改变,后面每一层的输入的分布在训练期间改变的问题。
这项技术只是在每一层的线性变换之后,激活函数之前加了一个操作,即先对之做简单的zero-centering并且归一化(通过当前的mini-batch计算平均值和标准差即可),然后使用两个新的参数(训练得到)对结果进行缩放和位移。换句话说,BN操作让模型自己学到每一层最佳的缩放和位移效果。BN算法如下所示:
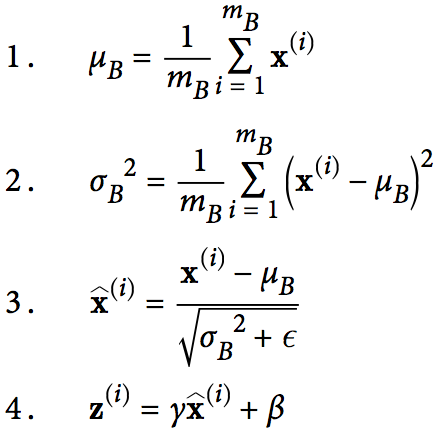
 注意:在测试和预测时,因为没有mini-batch,所以直接使用整个训练集的均值和方差(可以在训练时通过移动平均值高效计算得到)。
注意:在测试和预测时,因为没有mini-batch,所以直接使用整个训练集的均值和方差(可以在训练时通过移动平均值高效计算得到)。
BN优点有以下几个方面:
- 可以有效防止梯度消失和梯度爆炸问题,并且网络越深越有效。
- 使得神经网络模型对权重初始化方式不敏感。
- 可以使用较大的学习率,加速训练。
- 达到了一定的正则化的效果,防止过拟合。(因为对异常值做了归一化和再缩放)
- 输入数据无需再做标准化处理。
- 加速收敛。
当然BN也有缺点:
- 给神经网络增加了额外的计算和复杂度,所以训练和预测成本高且慢。
- 并非处处有效,有时反而使效果变差,要针对具体场景做权衡。
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X")
is_training = tf.placeholder(tf.bool, shape=(), name='is_training')
bn_params = {
"scale": True, # 默认情况下不缩放,即γ=1,这对None和ReLU激活函数是有意义的,因为下一层的权重向量负责缩放。对于其他激活函数,要设置为True。
'is_training': is_training,
'decay': 0.99, # 计算移动平均值,每个mini-batch输入后,该mini-batch的均值依赖于以前所有输入的移动平均值v^ <-v^×decay + v×(1−decay),v为新mini-batch的均值,v^为总的移动平均值。
'updates_collections': None # 必须设置为None,表示由TensorFlow负责计算移动平均值,否则TensorFlow只负责收集到collection,不负责计算。
}
hidden1 = fully_connected(X, n_hidden1, normalizer_fn=batch_norm, normalizer_params=bn_params)
hidden2 = fully_connected(hidden1, n_hidden2, normalizer_fn=batch_norm, normalizer_params=bn_params)
logits = fully_connected(hidden2, n_outputs, activation_fn=None, normalizer_fn=batch_norm, normalizer_params=bn_params)
或者简写为一下形式:
# 第一个参数是函数列表,剩下的参数将自动传递到这些函数里面
with tf.contrib.framework.arg_scope([fully_connected], normalizer_fn=batch_norm, normalizer_params=bn_params):
hidden1 = fully_connected(X, n_hidden1)
hidden2 = fully_connected(hidden1, n_hidden2)
logits = fully_connected(hidden2, n_outputs, activation_fn=None)
Max-Norm Regularization
Max-Norm对每一个神经元,约束其输入权重使其L2正则|w|2 ≤ r,可以用来代替L1、L2正则,并且也可以防止梯度爆炸和梯度消失,所以也可以代替Batch Norm。
hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
with tf.variable_scope("hidden1", reuse=True):
weights1 = tf.get_variable("weights")
threshold = 1.0
clipped_weights = tf.clip_by_norm(weights, clip_norm=threshold, axes=1)
clip_weights = tf.assign(weights, clipped_weights)
with tf.Session() as sess:
for epoch in range(n_epochs):
for X_batch, y_batch in zip(X_batches, y_batches):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
# 每次迭代后,运行权重裁剪
clip_weights.eval()
更简洁的写法如下:
def max_norm_regularizer(threshold, axes=1, name="max_norm", collection="max_norm"):
def max_norm(weights):
clipped = tf.clip_by_norm(weights, clip_norm=threshold, axes=axes)
clip_weights = tf.assign(weights, clipped, name=name)
# 将clip_weights操作添加到
tf.add_to_collection(collection, clip_weights)
return None # there is no regularization loss term
return max_norm
max_norm_reg = max_norm_regularizer(threshold=1.0)
hidden1 = fully_connected(X, n_hidden1, scope="hidden1", weights_regularizer=max_norm_reg)
# 取出集合max_norm中的ops:clip_weights
clip_all_weights = tf.get_collection("max_norm")
with tf.Session() as sess:
for epoch in range(n_epochs):
for X_batch, y_batch in zip(X_batches, y_batches):
sess.run(training_op, feed_dict={X: X_batch, y: y_batch})
sess.run(clip_all_weights)
梯度裁剪(Gradient Clipping)
Gradient Clipping是另一项解决梯度爆炸梯度消失问题的利器,它只不过是在BP的过程中裁剪一下梯度值,以使它不超过设定的阈值。(RNN中常用)
threshold = 1.0 # 超参数
# optimizer’s minimize()方法内部自动执行了compute_gradients和apply_gradients方法
# optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
grads_and_vars = optimizer.compute_gradients(loss)
# 裁剪梯度到–1.0到1.0之间
capped_gvs = [(tf.clip_by_value(grad, -threshold, threshold), var) for grad, var in grads_and_vars]
training_op = optimizer.apply_gradients(capped_gvs)
优化器
GradientDescentOptimizer
这是Batch Gradient Descent算法的实现,没做任何优化,极其低效。
MomentumOptimizer
想象一颗保龄球从光滑的表面滚落,其到达最低点的过程中,速度应该越来越快,但是默认的梯度下降算法越靠近最优点,更新速度越来越慢。所以动量梯度优化器利用之前所有的梯度作为下一次梯度更新的动量,算法如下:
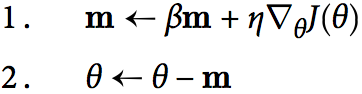 beta是摩擦因子(超参数),防止动量过大,一般为0.9。
当趋近收敛时,将1式的βm移项到左边,则m = η∇θJ(θ) * 1/(1-β),相当于10倍于梯度,所以可以说MomentumOptimizer比GradientDescentOptimizer至少快10倍。而且还有助于跳出局部最优点。
beta是摩擦因子(超参数),防止动量过大,一般为0.9。
当趋近收敛时,将1式的βm移项到左边,则m = η∇θJ(θ) * 1/(1-β),相当于10倍于梯度,所以可以说MomentumOptimizer比GradientDescentOptimizer至少快10倍。而且还有助于跳出局部最优点。
AdagradOptimizer & RMSPropOptimizer
AdagradOptimizer使得每次沿着梯度向量最陡峭的维度更新。
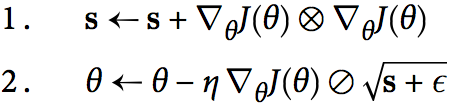 each si accumulates the squares of the partial derivative of the cost function with regards to parameter θi. If the cost function is steep along the ith dimension, then si will get larger and larger at each iteration.
each si accumulates the squares of the partial derivative of the cost function with regards to parameter θi. If the cost function is steep along the ith dimension, then si will get larger and larger at each iteration.
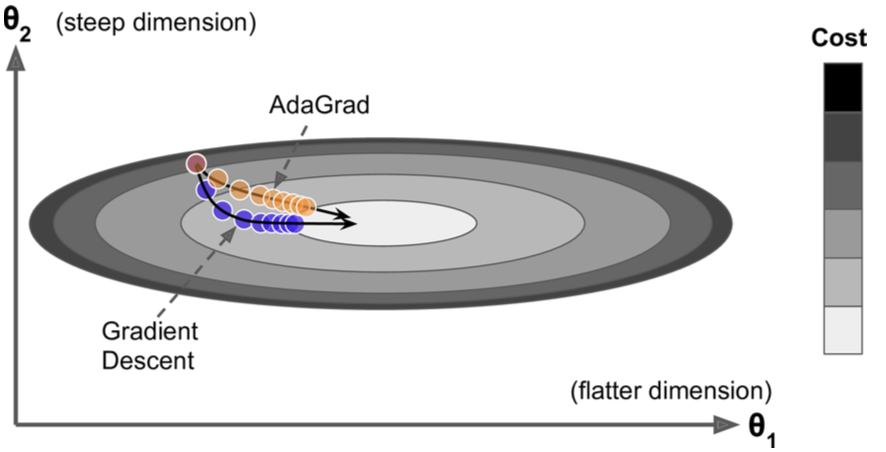 相当于在起点与最优点间搭了一把梯子。
AdagradOptimizer不常用,因为它不保证一定到达最优点,RMSPropOptimizer是它的改良版。
相当于在起点与最优点间搭了一把梯子。
AdagradOptimizer不常用,因为它不保证一定到达最优点,RMSPropOptimizer是它的改良版。
AdamOptimizer
AdamOptimizer结合了GradientDescentOptimizer、MomentumOptimizer、RMSPropOptimizer的所有优点,所以是优化器的最佳实践和首选。
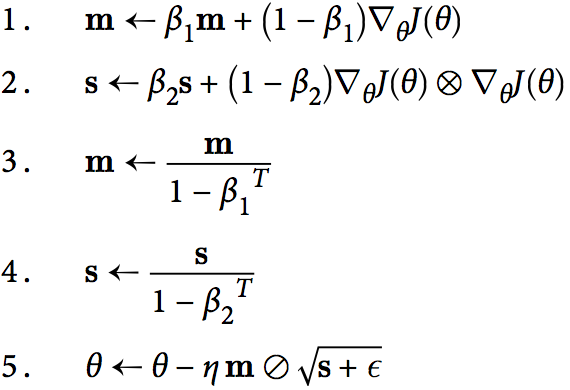 In fact, since Adam is an adaptive learning rate algorithm (like AdaGrad and RMSProp), it requires less tuning of the learning rate hyperparameter η. You can often use the default value η = 0.001。
In fact, since Adam is an adaptive learning rate algorithm (like AdaGrad and RMSProp), it requires less tuning of the learning rate hyperparameter η. You can often use the default value η = 0.001。
learning rate dacay
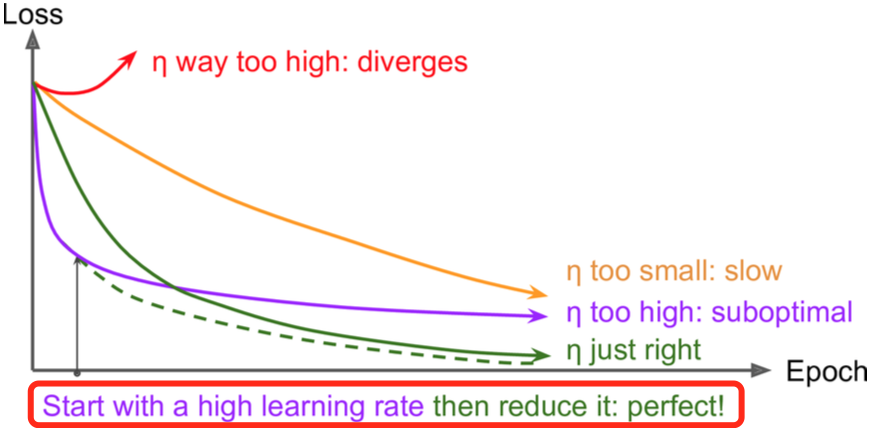
# 初始lr为0.1,每10000步衰减1/10
initial_learning_rate = 0.1
decay_steps = 10000
decay_rate = 1/10
global_step = tf.Variable(0, trainable=False)
learning_rate = tf.train.exponential_decay(initial_learning_rate, global_step, decay_steps, decay_rate)
optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9)
# 传入global_step,它会自己负责自增,无需手动做加1操作
training_op = optimizer.minimize(loss, global_step=global_step)
l1 and l2 Regularization
base_loss = tf.reduce_mean(xentropy, name="avg_xentropy")
reg_losses = tf.reduce_sum(tf.abs(weights))
loss = tf.add(base_loss, scale * reg_losses, name="loss")
tf.get_variable(regularizer=None)中的参数可以设置正则化方式,会被自动加到GraphKeys.REGULARIZATION_LOSSES集合中。下面是更通用的写法:
with arg_scope([fully_connected], weights_regularizer=tf.contrib.layers.l1_regularizer(scale=0.01)):
hidden1 = fully_connected(X, n_hidden1, scope="hidden1")
hidden2 = fully_connected(hidden1, n_hidden2, scope="hidden2")
logits = fully_connected(hidden2, n_outputs, activation_fn=None, scope="out")
······
······
reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES)
loss = tf.add_n([base_loss] + reg_losses, name="loss")
Dropout
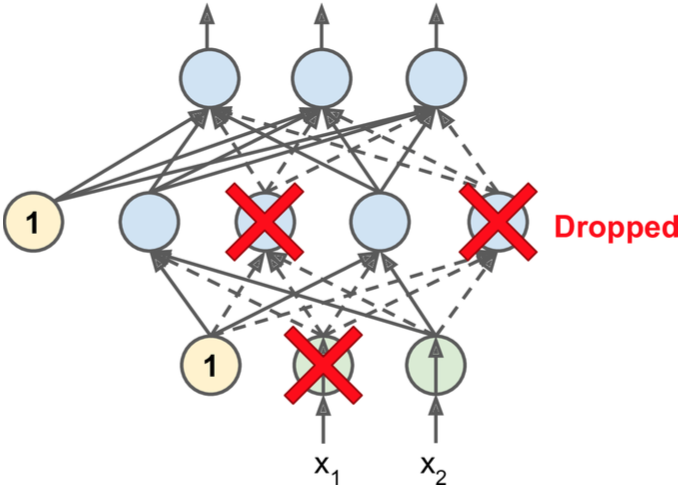 即在训练的每一步,每一层(包括输入层的输入数据和隐藏层的神经元)的元素都有p的概率被drop掉。
假设一家公司的员工,每天早上起床抛硬币决定今天是否去上班,这家公司会运转的好吗?Who knows,没准还真的会越来越好。这样迫使每个人身兼数职,因为身边的人随时可能不在,以前两个人或多个人干的活现在必须一个人完成,最终使得每一个人的能力都得到了增强,即使某个人辞职不干(神经元死掉)了,也不会造成太大影响,因为其他人随时可以顶上。
即在训练的每一步,每一层(包括输入层的输入数据和隐藏层的神经元)的元素都有p的概率被drop掉。
假设一家公司的员工,每天早上起床抛硬币决定今天是否去上班,这家公司会运转的好吗?Who knows,没准还真的会越来越好。这样迫使每个人身兼数职,因为身边的人随时可能不在,以前两个人或多个人干的活现在必须一个人完成,最终使得每一个人的能力都得到了增强,即使某个人辞职不干(神经元死掉)了,也不会造成太大影响,因为其他人随时可以顶上。
还有另一种理解方式,因为dropout,所以每一个神经元都有可能drop或保留,这样如果进行1000次迭代,就训练了1000个不同的神经网络,所以最终的神经网络可以看成是这1000个子网络的averaging ensemble。
需要注意的是,假设dropout设为0.5,那么训练完成后需要将每个神经元的连接权重乘以0.5,或者在训练过程中将WX + b的值乘以2。因为测试和预测阶段是不能dropout的,这样每层神经元个数就是训练时的两倍,导致domain shift。(由TensorFlow自动完成此操作)
from tensorflow.contrib.layers import dropout
is_training = tf.placeholder(tf.bool, shape=(), name='is_training')
keep_prob = 0.5
# dropout一些神经元就是设置这些神经元的输出为0
X_drop = dropout(X, keep_prob, is_training=is_training)
# 还可以使用下面的方法,但这种方式无法设置is_training,需要将keep_prob做成placeholder
# X_drop = tf.nn.dropout(X, keep_prob)
hidden1 = fully_connected(X_drop, n_hidden1, scope="hidden1")
hidden1_drop = dropout(hidden1, keep_prob, is_training=is_training)
hidden2 = fully_connected(hidden1_drop, n_hidden2, scope="hidden2")
hidden2_drop = dropout(hidden2, keep_prob, is_training=is_training)
logits = fully_connected(hidden2_drop, n_outputs, activation_fn=None)
dropout还可以在一定程度上防止梯度消失和梯度爆炸,并且防止过拟合。如果发现模型过拟合,可以增大dropout,相反欠拟合时减小dropout。
Data Augmentation
Data Augmentation,数据扩充或增强是指通过已有的样本生成新的训练样本,可以有效防止过拟合。 当然不能简简单单的复制样本数据。如果是图片,可以进行位移、旋转、缩放、改变光照等。
最佳实践
默认的黄金组合:
 learning rate的选择:
当一开始收敛太慢,这时候你增大learning rate,收敛变快了但是accuracy降低,这时候可以试下learning rate decay。
learning rate的选择:
当一开始收敛太慢,这时候你增大learning rate,收敛变快了但是accuracy降低,这时候可以试下learning rate decay。
社群
- QQ交流群

- 微信交流群

- 微信公众号
