算法原理
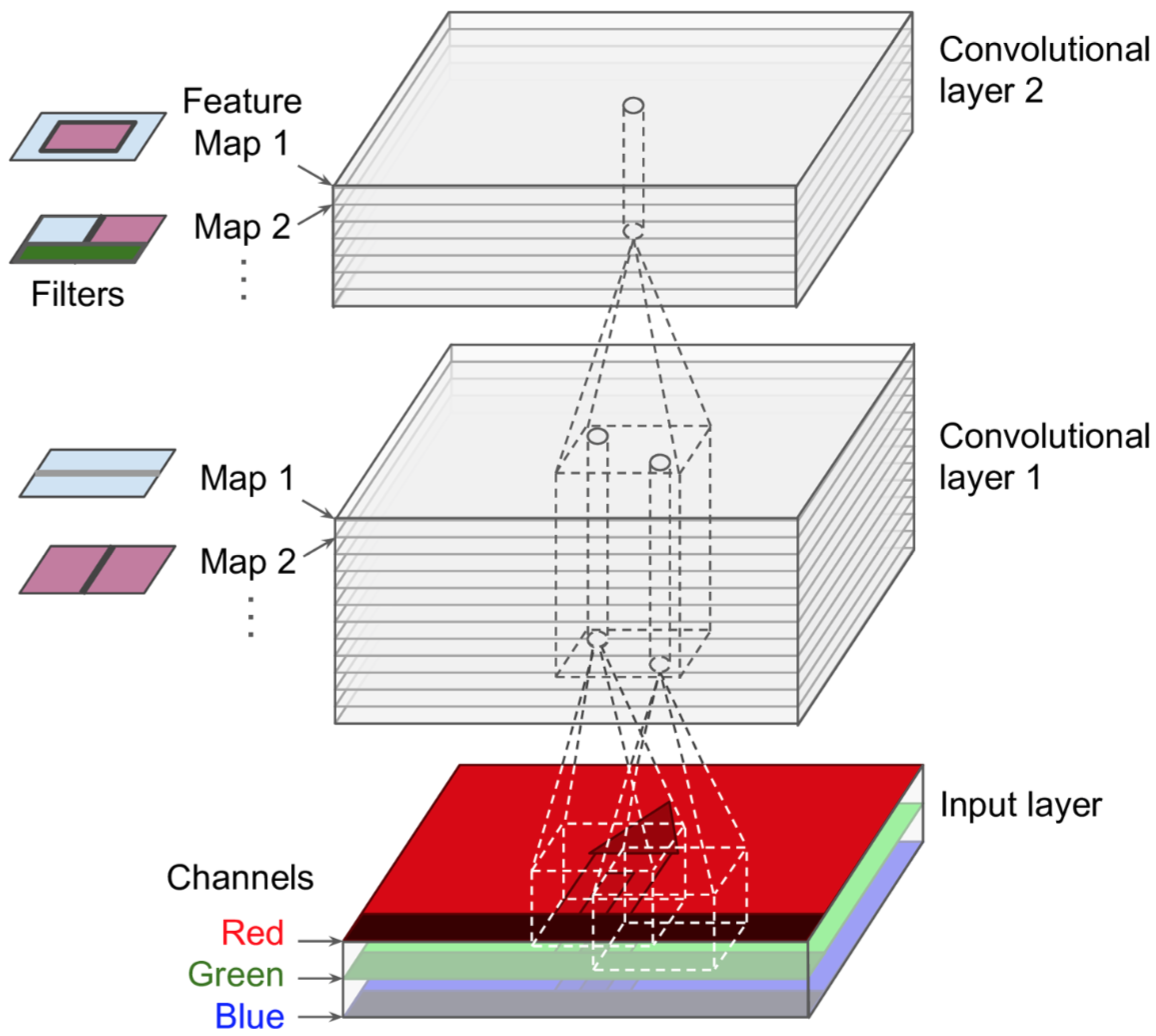
CNN(Convolutional Neural Networks,卷积神经网络),是用一个或多个局部感受野(filter,卷积核)在图像或者词向量组成的矩阵上以滑动窗口的形式不断提取局部特征,然后逐层前馈传递。它支持高效的GPU并行,并且由于参数共享有效的减少了神经网络参数数量,是一种非常重要的神经网络。
CNN主要包括卷积层(convolutional layer)和池化层(pooling layer)。
卷积层
第一个卷积层中的神经元并没有连接到输入图像中的每个像素,而只是连接到它们感知区域中的像素;第二卷积层中的每个神经元仅连接到位于第一层中的小矩形内的神经元。这种分层架构允许网络专注于第一个隐藏层中的低级特征,然后将它们组装成下一个隐藏层中的更高级别特征,依此类推。
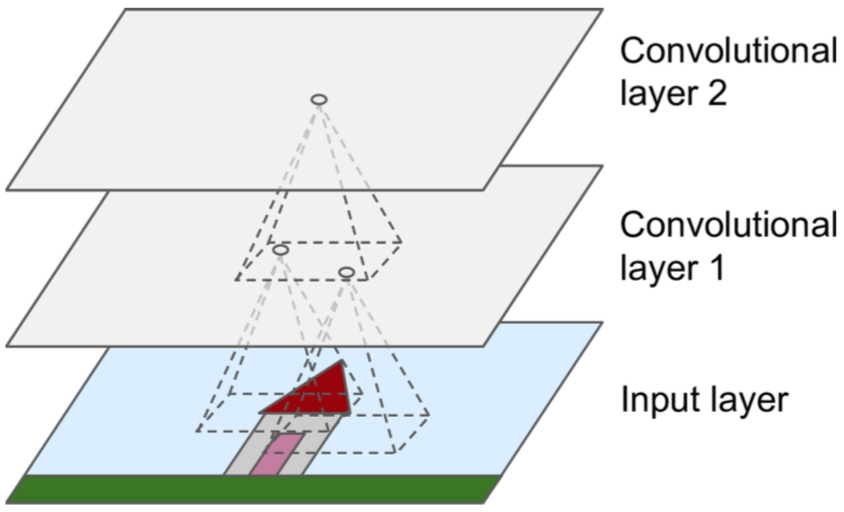 但目前为止,如果用全连接神经网络,必须将图片或者词向量矩阵flatten成一维的向量,才能输入到DNN,但是有了CNN,不需要做flatten,直接可以在二维或更高维的输入上做卷积操作。
但目前为止,如果用全连接神经网络,必须将图片或者词向量矩阵flatten成一维的向量,才能输入到DNN,但是有了CNN,不需要做flatten,直接可以在二维或更高维的输入上做卷积操作。
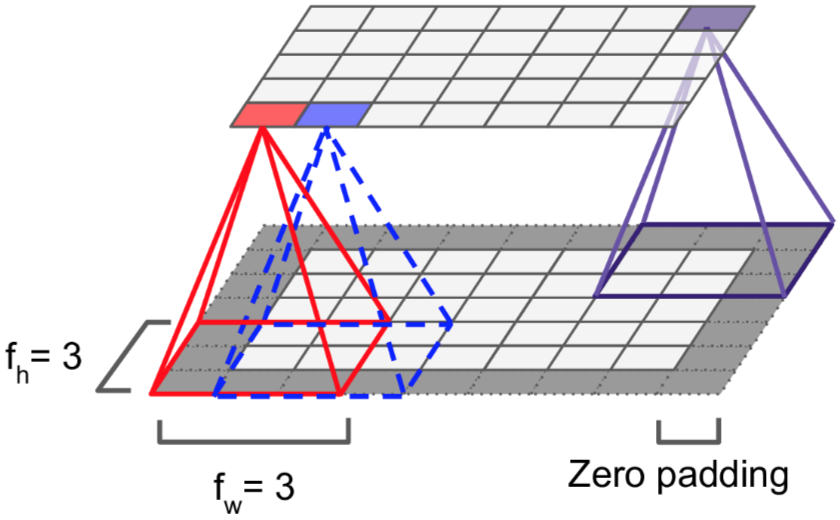
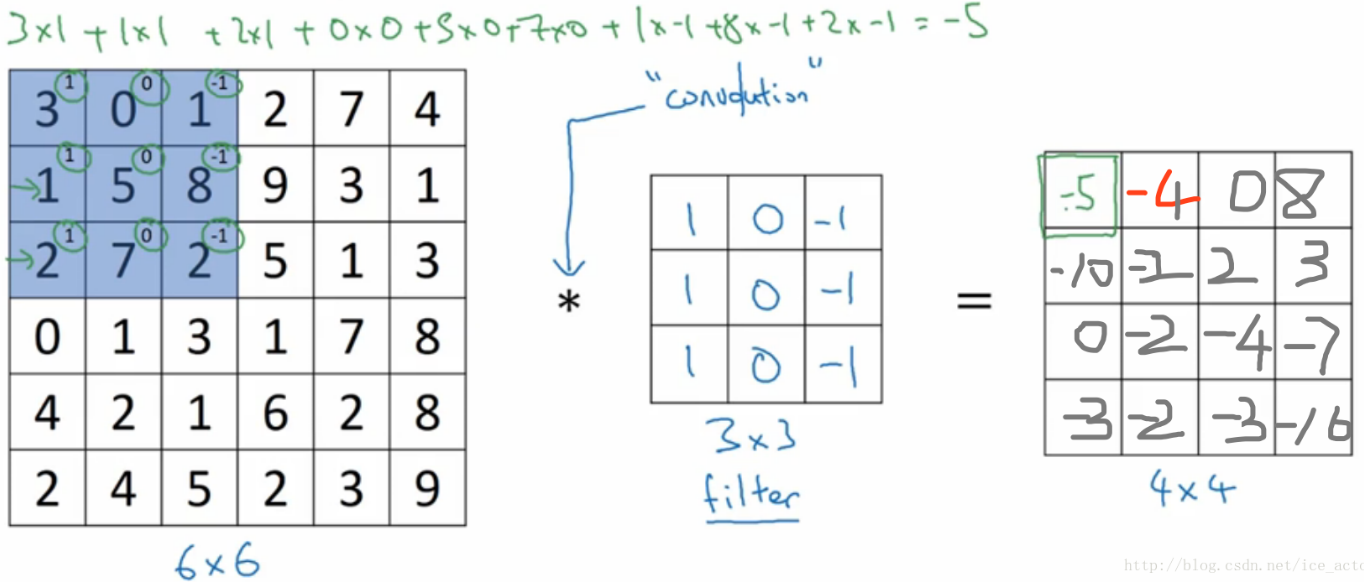 注意每一次卷积计算都要加激活函数,上面的省掉了。
三维图像上的卷积操作是怎样进行的呢?其实就是将二维的卷积核换成三维的就行了。
注意每一次卷积计算都要加激活函数,上面的省掉了。
三维图像上的卷积操作是怎样进行的呢?其实就是将二维的卷积核换成三维的就行了。
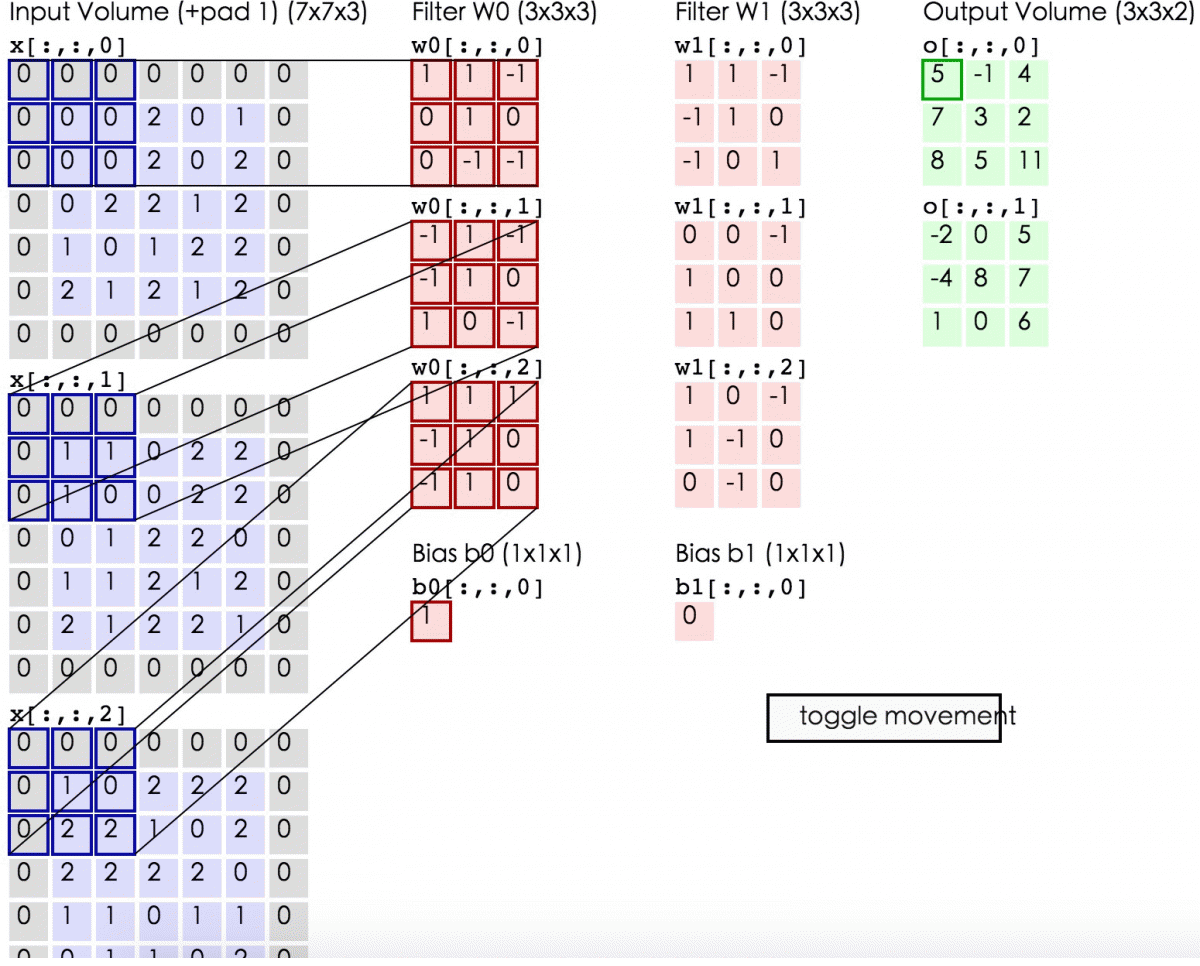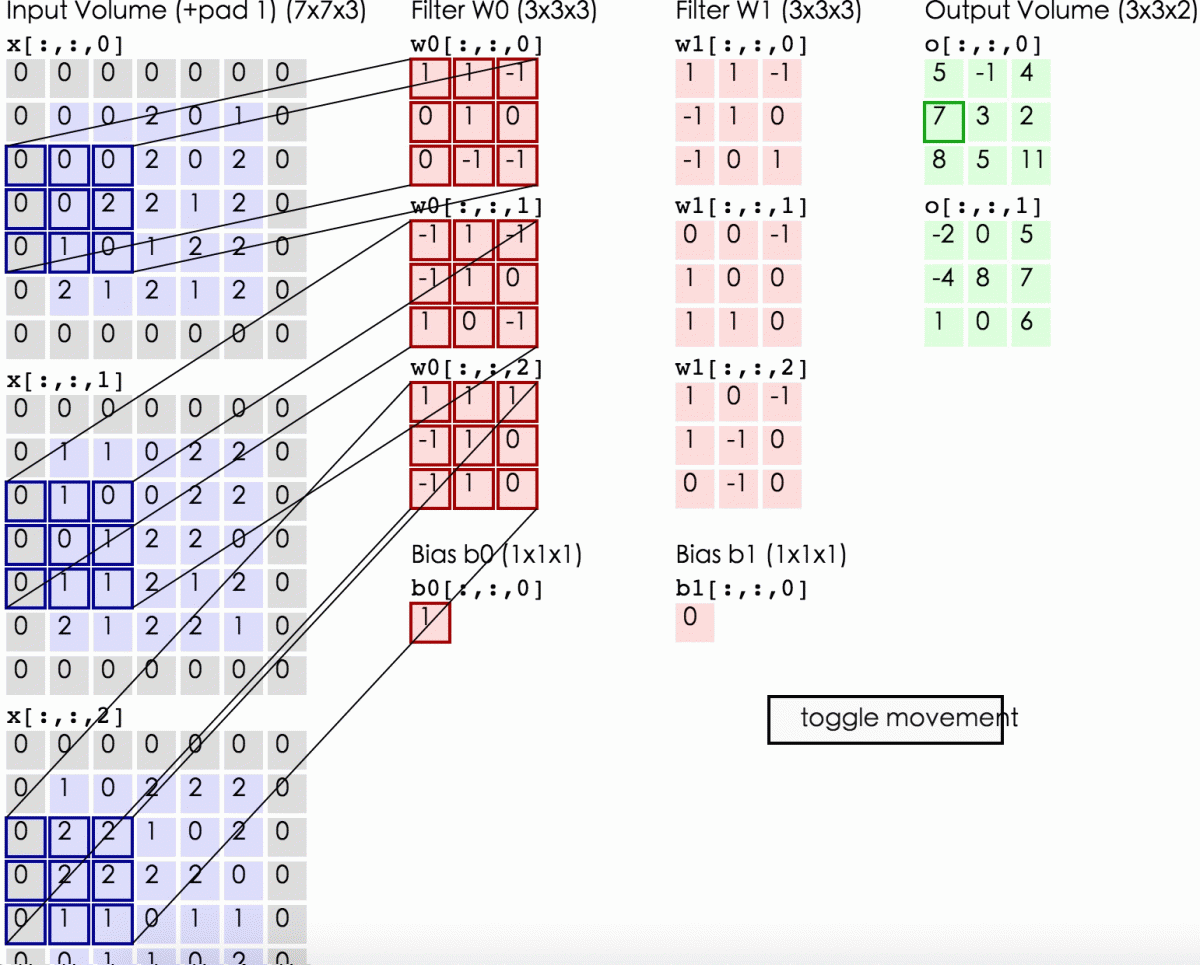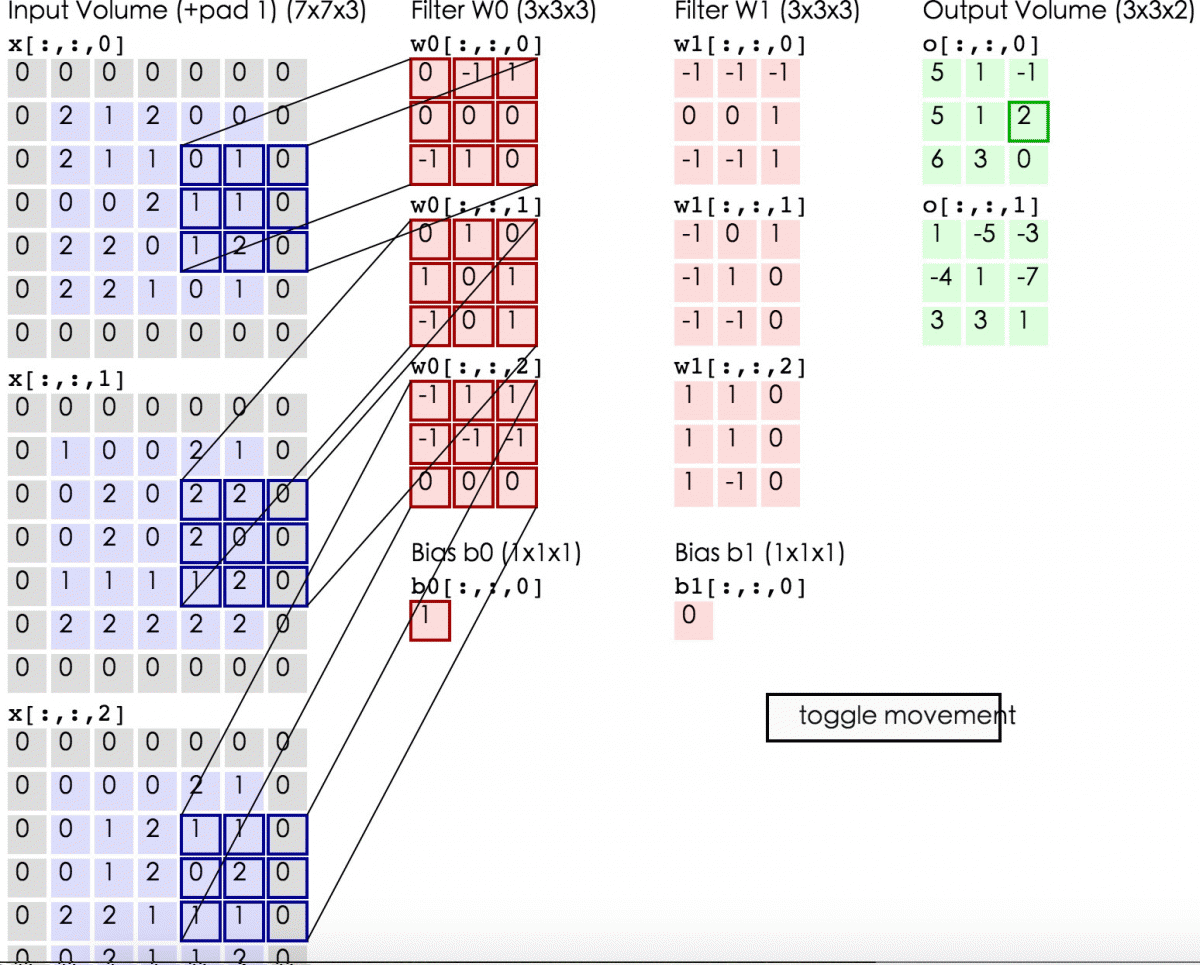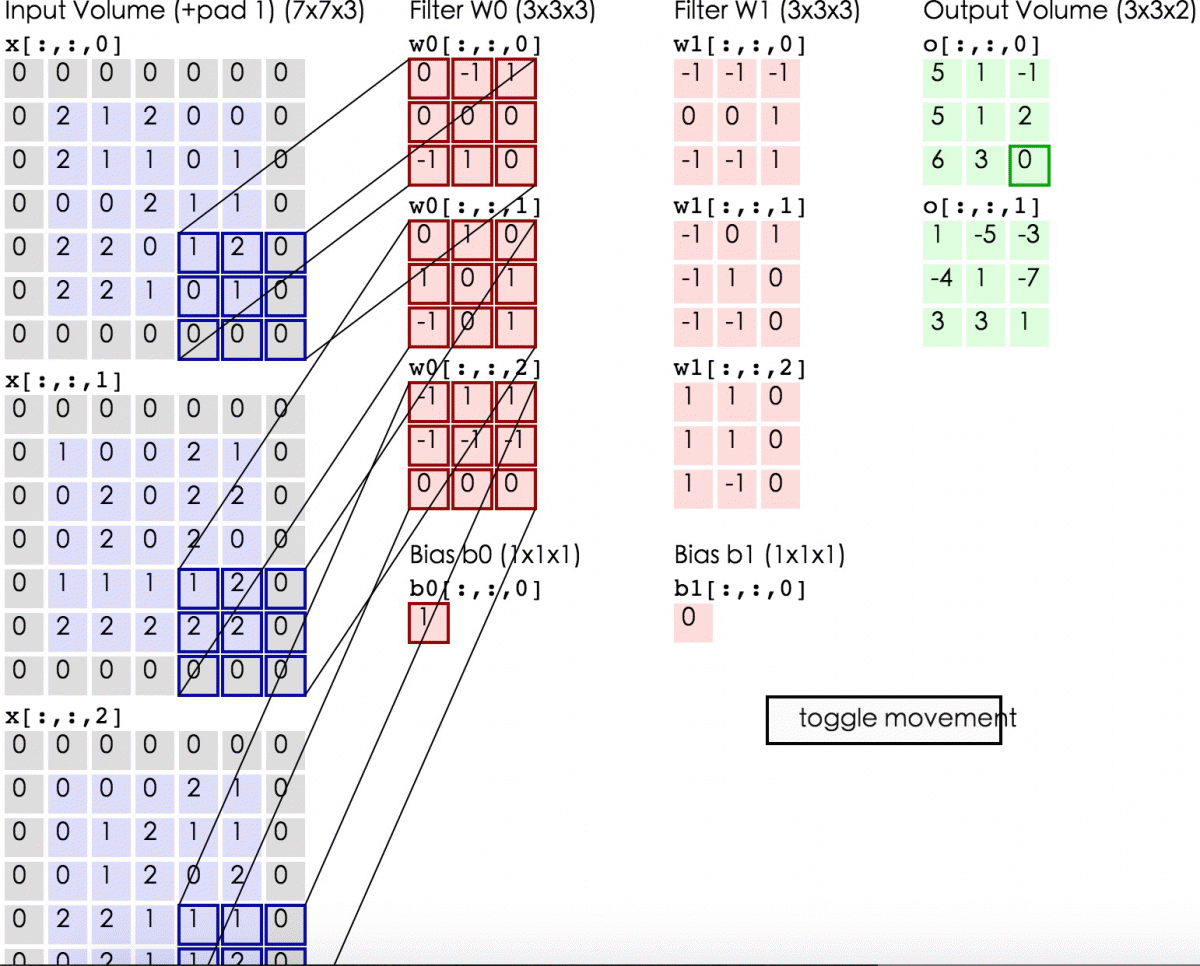 卷积核就是我们要训练的参数,训练完成后,CNN找到最合适的filter参数(weights and bias),提取最合适的局部特征,并且学习如何把这些局部特征组成更复杂的模式。
卷积核就是我们要训练的参数,训练完成后,CNN找到最合适的filter参数(weights and bias),提取最合适的局部特征,并且学习如何把这些局部特征组成更复杂的模式。
一张feature map上的所有提取到的特征都是通过同一个filter得到的,也就是说一张feature map共享同一套参数。这其实是非常有意义的,一旦CNN学会识别一个位置的模式,它就可以在任何位置识别出来此模式,因为filter是滑动的,所以图片即使发生翻转和位移,我仍然能够识别。相反,常规的DNN学会了识别一个位置中的模式,它就只能在该特定位置识别它。
其实卷积神经网络可以看做是一个利用了权值共享的特殊的全连接神经网络,所以依然可以利用反向传播进行模型训练。
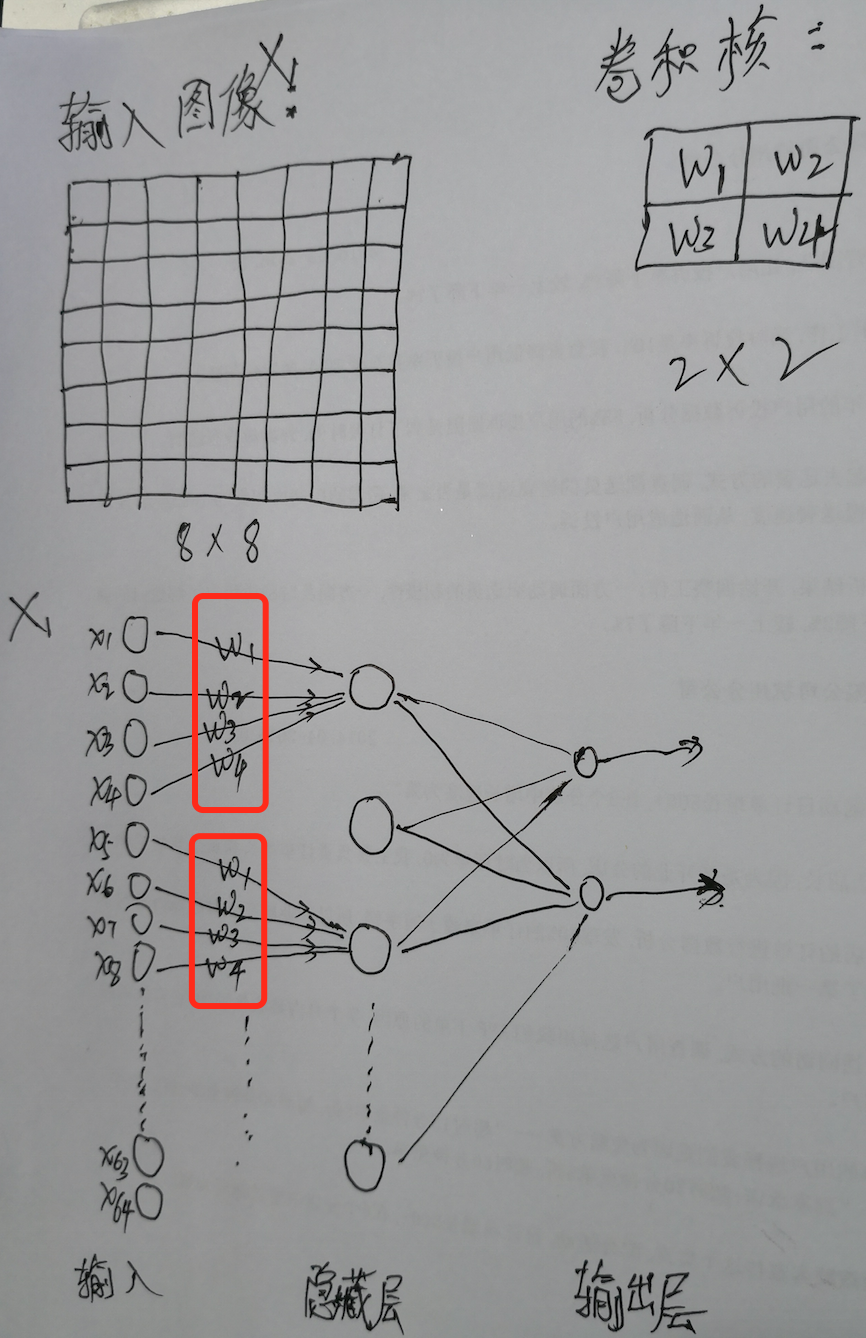 同样的,全连接神经网络也是一种特殊的卷积神经网络,只不过卷积核大小是原输入图像大小而已。
同样的,全连接神经网络也是一种特殊的卷积神经网络,只不过卷积核大小是原输入图像大小而已。
卷积核可以有多个,用于提取不同纬度的局部特征,即同时将多个filter应用于其输入,使其能够在其输入中的任何位置检测多个特征。每个卷积核卷完一整张图片或整个词向量矩阵后就形成了一张feature map,最终将所有的feature map做stack。
 代码示例如下:
代码示例如下:
# 前三个参数分别定义了宽、高、通道数,最后一个参数是卷积核个数
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
# 输入图像的shape
X = tf.placeholder(tf.float32, shape=(None, height, width, channels))
# 1. strides分别是在每一个维度上的步长,第一个1代表跳过一些实例,最后一个1代表跳过一些通道或feature map
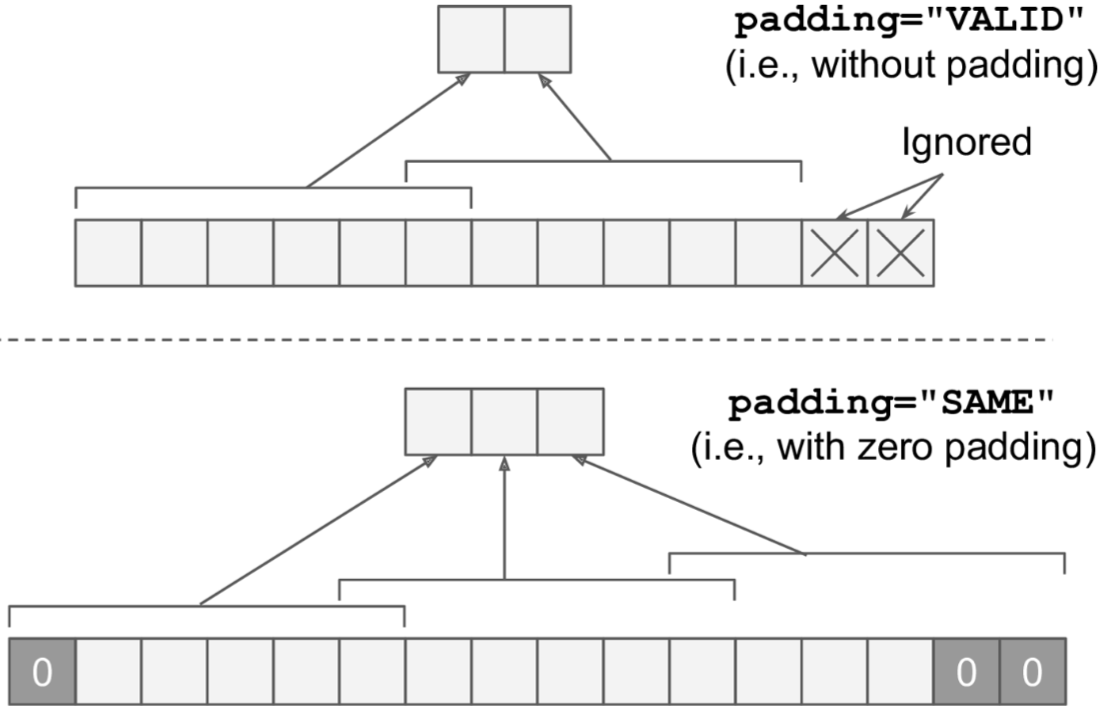
# 2. padding:是否做0填充
convolution = tf.nn.conv2d(X, filters, strides=[1,2,2,1], padding="SAME")
池化层
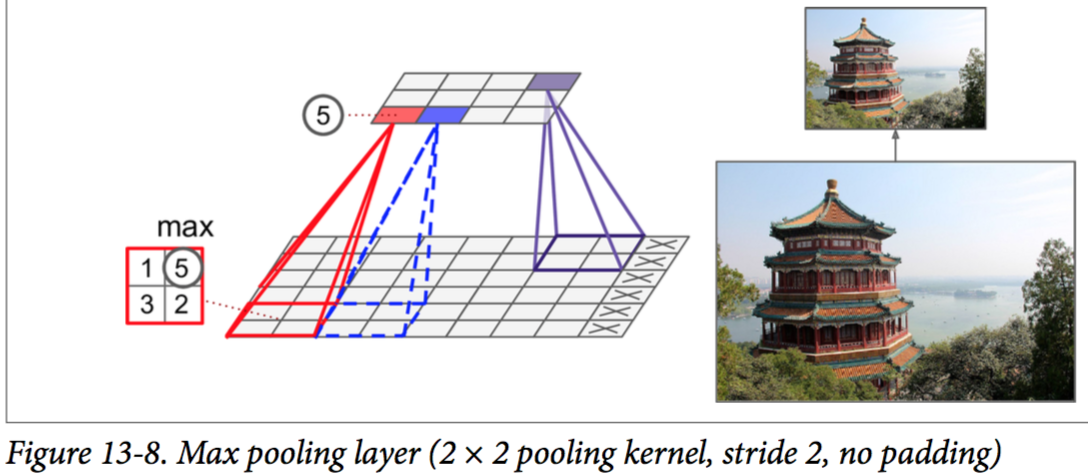
pooling的目标是对输出进行下采样,即收缩输出值,以减少计算量、内存占用量以及参数数量(避免过拟合)。这种下采样也能使神经网络容忍图像偏移(位置不变性)。
pooling层神经元没有weights,它仅仅是使用聚合函数(max、avg)对输出进行aggregate操作。一般来说,max pooling可以找出最重要最显著的特征,avg pooling可以得到最一般化的特征。
 代码示例如下:
代码示例如下:
X = tf.placeholder(tf.float32, shape=(None, height, width, channels))
# strides,padding同上。ksize的第一个1表示对多个instance做聚合,最后一个1表示在通道维度做聚合
max_pool = tf.nn.max_pool(X, ksize=[1,2,2,1], strides=[1,2,2,1], padding="VALID")
注意:虽然卷积神经网络起源于图像识别,但是在NLP领域也同样适用。
- 文字和图像一样也满足局部相关性,即该文字只和其附近的文字相关,距离其距离越远越不相关。
- 图像的像素点shuffle后,不再是以前的图片,但是文字shuffle后,一般还是能识别到以前的类别,这是利用了CNN的位置不变性。
- CNN卷积核天生就能提取文字的N-gram信息,所以一般不需要做分词。
- 因为卷积核是以滑动窗口的形式逐步移动,所以也就具备了时序性。
- CNN通过多层级联、全连接层、Attention机制也可以提取全局特征。
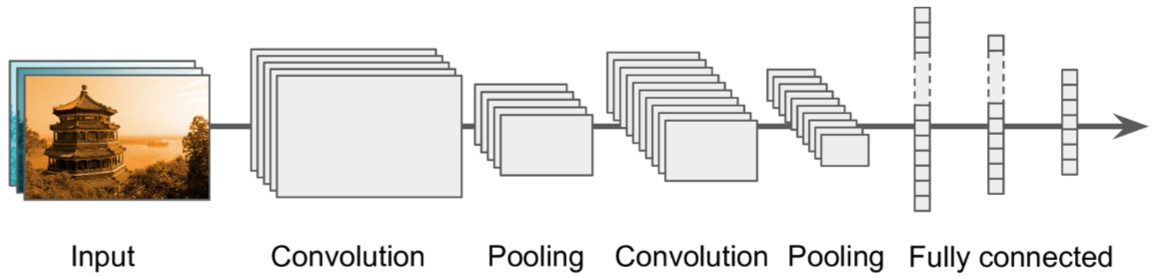
一般的CNN架构图如下所示:
 注意:
注意:
- 通常所说的CNN的dropout,是对输入层和后面的全连接层来说的,卷积层和池化层不存在dropout。
- 由于卷积层和池化层的特殊性,所以很少出现梯度爆炸和梯度消失问题。
Residual learning
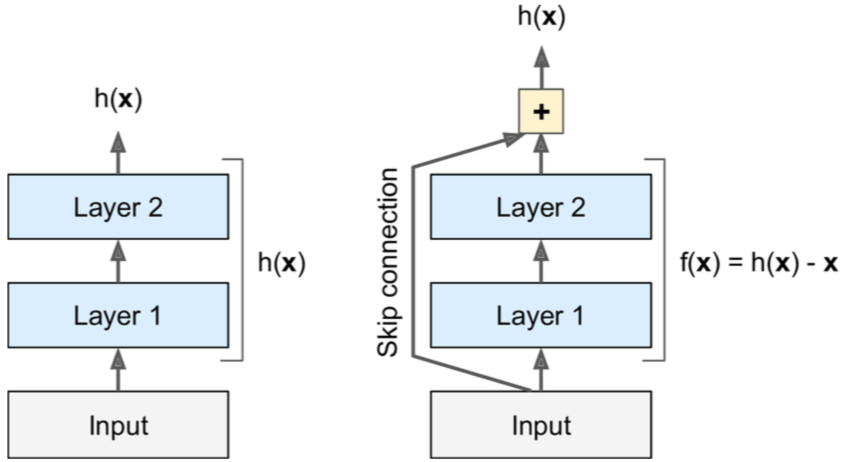 Residual learning,残差网络,又叫做skip connection,即将输入跳过后面几层继续往下传递。
Residual learning,残差网络,又叫做skip connection,即将输入跳过后面几层继续往下传递。
这样做是有意义的,尤其是在网络很深的情况下,如果添加skip connection layer,则生成的网络输出其输入的副本,换句话说,将原始的有用的特征得到了保留和传承,这将大大加快训练速度。
当你发现你的模型在训练集上的loss总是居高不下,增加网络的深度反而效果更差,出现这种情况可能就意味着网络开始退化了,这不是因为过拟合,这其实是烦人的退化问题,残差网络是解决这一问题的利器,可以有效的训练更深的网络。另外,残差网络还能有效缓解梯度消失和梯度爆炸问题,因为采用了残差网络,low level的神经元参数再也不会出现更新不到的问题。
加洞卷积和转置卷积
加洞卷积(dilated convolution,atrous_conv2d()),即将卷积核filter行列之间补零扩张。例如将[[1,2,3]]这个1×3的filter以4的膨胀率扩张,导致扩张后的filter为[[1,0,0,0,2,0,0,0,3]]。这样做可以使得卷积层在没有计算代价的情况下,具有更大的感受野并且不需要使用额外的参数。
转置卷积(conv2d_transpose),或者叫反卷积,它通过在输入的行列之间插入零来实现,因此可以用来做上采样。因为在典型的CNN中,随着卷积和池化的进行,特征图会变得越来越小,因此如果要输出与输入大小相同的特征图,则需要进行反卷积。
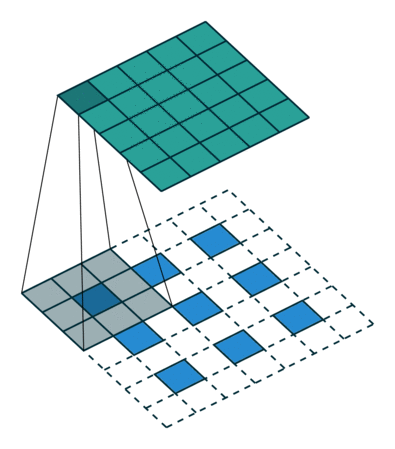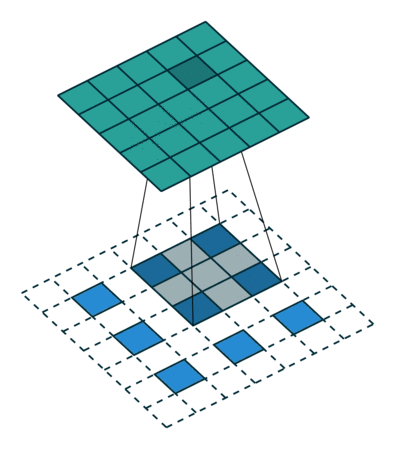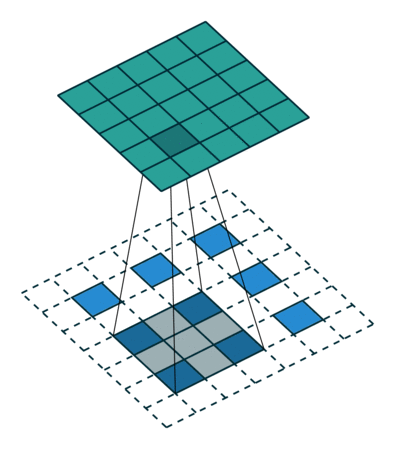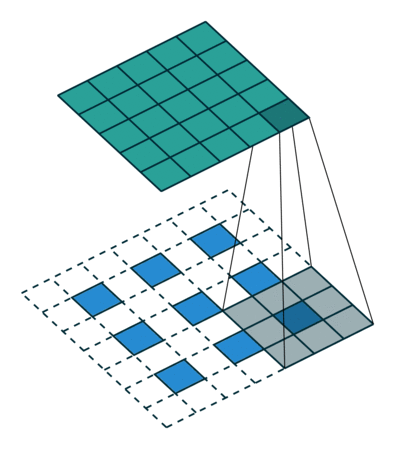
模型训练
代码地址 https://github.com/qianshuang/dl-exp
class TextCNN(object):
"""文本分类,CNN模型"""
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
self.cnn()
def cnn(self):
"""CNN模型"""
# 词向量映射
with tf.device('/cpu:0'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("cnn"):
# CNN layer:输入为1000*64,64为input_channels
# conv = tf.layers.conv1d(embedding_inputs, self.config.num_filters, self.config.kernel_size, name='conv')
filter_w = tf.Variable(tf.truncated_normal([self.config.kernel_size, self.config.embedding_dim, self.config.num_filters], stddev=0.1))
conv = tf.nn.conv1d(embedding_inputs, filter_w, 1, padding='SAME')
print(conv)
# global max pooling layer,这么做是有意义的,它强制前面的神经网络层直接产出目标类别的目标特征,并且有效减少了神经网络的参数,避免了过拟合
# 其作用类似于1 * 1卷积核,一方面降维,另一方面相对于3 * 3卷积核来说有效减少了参数数量,最后还能提取到uni-gram特征
gmp = tf.reduce_max(conv, reduction_indices=[1], name='gmp')
print(gmp)
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc = tf.layers.dense(gmp, self.config.hidden_dim, name='fc1')
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
# 激活函数
fc = tf.nn.relu(fc)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
self.y_pred_cls = tf.argmax(self.logits, 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
运行结果:
Configuring model...
Loading training data...
Training and evaluating...
Epoch: 1
Iter: 0, Train Loss: 5.4, Train Acc: 8.59%, Val Loss: 5.2, Val Acc: 10.40%, Time: 0:00:02 *
Iter: 10, Train Loss: 0.81, Train Acc: 72.66%, Val Loss: 0.92, Val Acc: 71.60%, Time: 0:00:05 *
Iter: 20, Train Loss: 0.61, Train Acc: 85.16%, Val Loss: 0.42, Val Acc: 87.90%, Time: 0:00:08 *
Iter: 30, Train Loss: 0.48, Train Acc: 85.16%, Val Loss: 0.37, Val Acc: 89.80%, Time: 0:00:12 *
Iter: 40, Train Loss: 0.37, Train Acc: 92.97%, Val Loss: 0.32, Val Acc: 91.60%, Time: 0:00:16 *
Iter: 50, Train Loss: 0.18, Train Acc: 94.53%, Val Loss: 0.23, Val Acc: 94.00%, Time: 0:00:18 *
Iter: 60, Train Loss: 0.17, Train Acc: 96.09%, Val Loss: 0.21, Val Acc: 94.10%, Time: 0:00:23 *
Iter: 70, Train Loss: 0.4, Train Acc: 92.50%, Val Loss: 0.18, Val Acc: 95.60%, Time: 0:00:26 *
Epoch: 2
Iter: 80, Train Loss: 0.026, Train Acc: 99.22%, Val Loss: 0.22, Val Acc: 93.90%, Time: 0:00:29
Iter: 90, Train Loss: 0.02, Train Acc: 100.00%, Val Loss: 0.18, Val Acc: 95.20%, Time: 0:00:31
Iter: 100, Train Loss: 0.02, Train Acc: 99.22%, Val Loss: 0.16, Val Acc: 95.80%, Time: 0:00:35 *
......
Epoch: 6
Iter: 360, Train Loss: 0.0017, Train Acc: 100.00%, Val Loss: 0.14, Val Acc: 96.20%, Time: 0:01:57
Iter: 370, Train Loss: 0.0016, Train Acc: 100.00%, Val Loss: 0.14, Val Acc: 96.10%, Time: 0:01:59
Iter: 380, Train Loss: 0.0016, Train Acc: 100.00%, Val Loss: 0.14, Val Acc: 96.10%, Time: 0:02:02
No optimization for a long time, auto-stopping...
Loading test data...
Testing...
Test Loss: 0.14, Test Acc: 96.30%
Precision, Recall and F1-Score...
precision recall f1-score support
财经 0.98 0.97 0.98 115
娱乐 1.00 0.98 0.99 89
时政 0.93 0.96 0.94 94
家居 0.90 0.93 0.92 89
游戏 1.00 0.97 0.99 104
教育 0.97 0.92 0.95 104
时尚 0.95 0.99 0.97 91
科技 0.99 0.99 0.99 94
房产 0.91 0.92 0.91 104
体育 1.00 0.99 1.00 116
avg / total 0.96 0.96 0.96 1000
Confusion Matrix...
[[112 0 1 1 0 0 0 0 1 0]
[ 0 87 1 0 0 0 1 0 0 0]
[ 1 0 90 0 0 0 0 0 3 0]
[ 1 0 0 83 0 1 0 0 4 0]
[ 0 0 0 0 101 1 1 1 0 0]
[ 0 0 1 3 0 96 2 0 2 0]
[ 0 0 0 0 0 1 90 0 0 0]
[ 0 0 0 1 0 0 0 93 0 0]
[ 0 0 3 4 0 0 1 0 96 0]
[ 0 0 1 0 0 0 0 0 0 115]]
社群
- QQ交流群

- 微信交流群

- 微信公众号
